







一、带ROLLUP或CUBE运算的GROUP BY
在一个查询的GROUP BY子句中指定ROLLUP和CUBE运算。ROLLUP分组产生一个包含常规分组行和小计行的结果集。CUBE分组产生一个包含ROLLUP行和交叉表行的结果集。
ROLLUP和CUBE操作只在ORACLE8i及以后版本可用。
二、ROLLUP操作
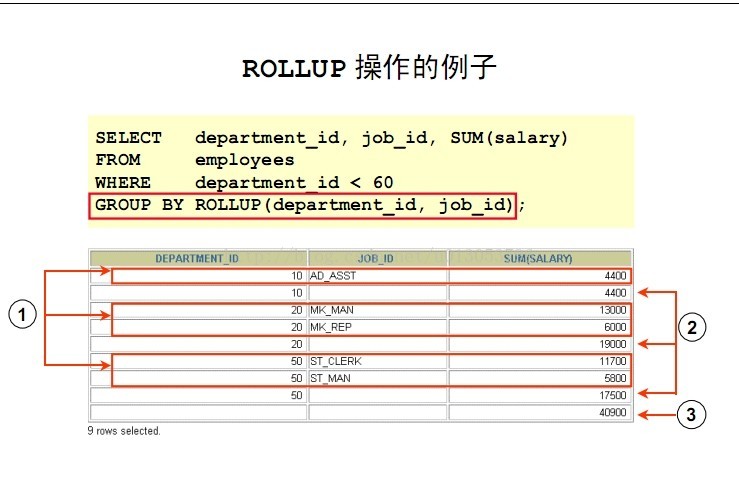
在幻灯片的例子中:
- 显示用GROUP BY子句分组的部门号小于60的每个部门(被标注为1)中的每个job_id的合计薪水。
- ROLLUP操作显示:
- 部门号小于60的部门的合计薪水(被标注为2)。
- 所有部门号小于60的部门的合计薪水, 不考虑job ids(被标注为3)。
- 所有行被1指出的是常规行, 所有被2和3指出的行是超合计行。
ROLLUP操作按照在GROUP BY子句中指定的分组列表, 从最细的级别到总计累计创建子合计。首先它对在GROUP BY子句中指定的组计算标准的合计值(在例子中,在一个部门中每个工作岗位的薪水合计)。然后它逐渐增多地创建更高级的子合计, 从右到左移动通过分组列字段的列表。(在前面的例子中, 计算每个部门的薪水合计, 接着计算所有部门的薪水总计。也就是说GROUP BY ROLLUP(DEPARTMENT_ID,JOB_ID)是按照先GROUP BY (DEPARTMENT_ID,JOB_ID)再GROUP BY(DEPARTMENT_ID)最后再GROUP BY(0) )。
- 在GROUP BY 子句的ROLLUP操作中给N个表达式, 操作结果有n+1=2+1=3个分组。
- 比如GROUP BY ROLLUP(A,B,C)则按照GROUP BY(A,B,C) GROUP BY(A,B) GROUP BY(A) GROUP BY(0)分别分组汇总ROLLUP产生n+1种组合。
- 基于第一个n表达式的值的行被称为行或常规行, 其它的行被称为超合计行。
三、CUBE操作
CUBE操作是一个在SELECT语句的GROUP BY子句中附加的开关。CUBE操作可以应用所有的合计函数, 包括AVG、SUM、MAX、MIN和COUNT。它被用于产生结果集, 典型的用途是用来做交叉表报表。ROLLUP只能产生可能的小计组合的一小部分, CUBE产生在GROUP BY子句中指定的所有可能的分组组合, 和总数之和。
CUBE操作与合计函数一起使用, 在结果集中产生附加行。包含在GROUP BY 子句中的列被交叉引用, 来产生一个分组的超集。在SELECT列表中指定的合计函数被用于这些分组以产生附加总合计行的概要值。在结果集中的额外分组数由包含在GROUP BY 子句中的列数确定。
事实上, 每一个可能的列组合或在GROUP BY 子句中的表达式都被用于产生总合计。如果在GROUP BY 子句中有n列或表达式, 将有2的n次方个可能的总合组合。
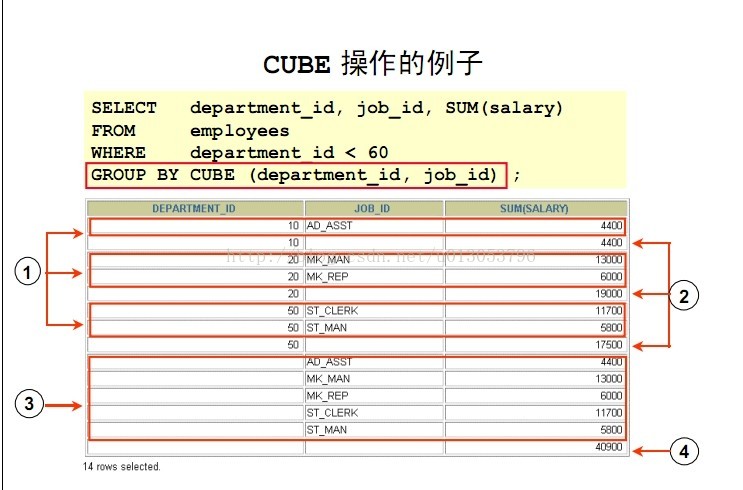
CUBE操作的例子:
在例子中SELECT语句的输出可以解释如下:
- 在一个部门中每个岗位的合计薪水(对于那些部门ID小于60的部门)按照GROUP BY子句显示(标注1)
- 部门ID小于60的那些部门的合计薪水(标注2)
- 不考虑部门的每个工作岗位的合计薪水(标住3)
- 部门ID小于60, 不考虑工作岗位的部门合计薪水(标注4)
在前面的例子中, 所有指示为1的行是规则行, 所有指示是2和4的行是总合计行, 所有指示是3的行交叉表值。
CUBE操作也执行ROLLUP操作以显示那些部门ID小于60的部门的小计,和那些部门ID小于60而不考虑工作岗位的部门的合计薪水。另外, CUBE操作显示每个工作岗位而不考虑部门的合计薪水。也就是说GROUP BY ROLLUP(DEPARTMENT_ID,JOB_ID)是按照先GROUP BY (DEPARTMENT_ID,JOB_ID)再GROUP BY(DEPARTMENT_ID), 再GROUP BY(JOB_ID),最后再GROUP BY(0) )。
- 比如 GROUP BY CUBE(A,B,C)则按照GROUP BY(A,B,C) GROUP BY(A,B) GROUP BY(A,C) GROUP BY(B,C) GROUP BY(A) GROUP BY(B) GROUP BY(C) GROUP BY(0)分别分组汇总CUBE产生2的n次方结果。














 6178
6178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









