









参考文章地址:http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html
人脸检测属于计算机视觉的范畴,早期人们的主要研究方向是人脸识别,即根据人脸来识别人物的身份,后来在复杂背景下的人脸检测需求越来越大,人脸检测也逐渐作为一个单独的研究方向发展起来。
目前的人脸检测方法主要有两大类:基于知识和基于统计。
“基于知识的方法主要利用先验知识将人脸看作器官特征的组合,根据眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之间的几何位置关系来检测人脸。基于统计的方法则将人脸看作一个整体的模式——二维像素矩阵,从统计的观点通过大量人脸图像样本构造人脸模式空间,根据相似度量来判断人脸是否存在。在这两种框架之下,发展了许多方法。目前随着各种方法的不断提出和应用条件的变化,将知识模型与统计模型相结合的综合系统将成为未来的研究趋势。”(来自论文《基于Adaboost的人脸检测方法及眼睛定位算法研究》)
基于知识的人脸检测方法
Ø 模板匹配
Ø 人脸特征
Ø 形状与边缘
Ø 纹理特性
Ø 颜色特征
基于统计的人脸检测方法
Ø 主成分分析与特征脸
Ø 神经网络方法
Ø 支持向量机
Ø 隐马尔可夫模型
Ø Adaboost算法
所谓分类器,在这里就是指对人脸和非人脸进行分类的算法,在机器学习领域,很多算法都是对事物进行分类、聚类的过程。OpenCV中的ml模块提供了很多分类、聚类的算法。
注:聚类和分类的区别是什么?一般对已知物体类别总数的识别方式我们称之为分类,并且训练的数据是有标签的,比如已经明确指定了是人脸还是非人脸,这是一种有监督学习。也存在可以处理类别总数不确定的方法或者训练的数据是没有标签的,这就是聚类,不需要学习阶段中关于物体类别的信息,是一种无监督学习。
其中包括Mahalanobis距离、K均值、朴素贝叶斯分类器、决策树、Boosting、随机森林、Haar分类器、期望最大化、K近邻、神经网络、支持向量机。
我们要探讨的Haar分类器实际上是Boosting算法的一个应用,Haar分类器用到了Boosting算法中的AdaBoost算法,只是把AdaBoost算法训练出的强分类器进行了级联,并且在底层的特征提取中采用了高效率的矩形特征和积分图方法,这里涉及到的几个名词接下来会具体讨论。
虽说haar分类器采用了Boosting的算法,但在OpenCV中,Haar分类器与Boosting没有采用同一套底层数据结构,《Learning OpenCV》中有这样的解释:“Haar分类器,它建立了boost筛选式级联分类器。它与ML库中其他部分相比,有不同的格局,因为它是在早期开发的,并完全可用于人脸检测。”
是的,在2001年,Viola和Jones两位大牛发表了经典的《Rapid Object Detection using a Boosted Cascade of Simple Features》【1】和《Robust Real-Time Face Detection》【2】,在AdaBoost算法的基础上,使用Haar-like小波特征和积分图方法进行人脸检测,他俩不是最早使用提出小波特征的,但是他们设计了针对人脸检测更有效的特征,并对AdaBoost训练出的强分类器进行级联。这可以说是人脸检测史上里程碑式的一笔了,也因此当时提出的这个算法被称为Viola-Jones检测器。又过了一段时间,Rainer Lienhart和Jochen Maydt两位大牛将这个检测器进行了扩展【3】,最终形成了OpenCV现在的Haar分类器。之前我有个误区,以为AdaBoost算法就是Viola和Jones搞出来的,因为网上讲Haar分类器的地方都在大讲特讲AdaBoost,所以我错觉了,后来理清脉络,AdaBoost是Freund 和Schapire在1995年提出的算法,是对传统Boosting算法的一大提升。Boosting算法的核心思想,是将弱学习方法提升成强学习算法,也就是“三个臭皮匠顶一个诸葛亮”,它的理论基础来自于Kearns 和Valiant牛的相关证明【4】,在此不深究了。反正我是能多简略就多简略的把Haar分类器的前世今生说完鸟,得出的结论是,大牛们都是成对儿的。。。额,回到正题,Haar分类器 = Haar-like特征 + 积分图方法 + AdaBoost + 级联;
注:为何称其为Haar-like?这个名字是我从网上看来的,《Learning OpenCV》中文版提到Haar分类器使用到Haar特征,但这种说法不确切,应该称为类Haar特征,Haar-like就是类Haar特征的意思。
一看到Haar-like特征这玩意儿就头大的人举手。好,很多人。那么我先说下什么是特征,我把它放在下面的情景中来描述,假设在人脸检测时我们需要有这么一个子窗口在待检测的图片窗口中不断的移位滑动,子窗口每到一个位置,就会计算出该区域的特征,然后用我们训练好的级联分类器对该特征进行筛选,一旦该特征通过了所有强分类器的筛选,则判定该区域为人脸。
那么这个特征如何表示呢?好了,这就是大牛们干的好事了。后人称这他们搞出来的这些东西叫Haar-Like特征。
下面是Viola牛们提出的Haar-like特征。
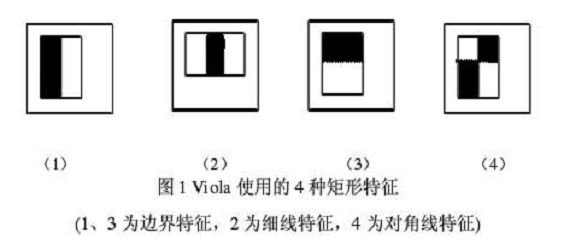
下面是Lienhart等牛们提出的Haar-like特征。
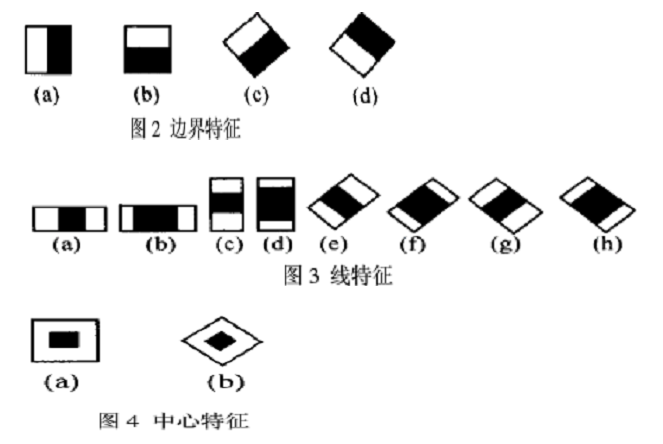
这些所谓的特征不就是一堆堆带条纹的矩形么,到底是干什么用的?我这样给出解释,将上面的任意一个矩形放到人脸区域上,然后,将白色区域的像素和减去黑色区域的像素和,得到的值我们暂且称之为人脸特征值,如果你把这个矩形放到一个非人脸区域,那么计算出的特征值应该和人脸特征值是不一样的,而且越不一样越好,所以这些方块的目的就是把人脸特征量化,以区分人脸和非人脸。
之所以放到最后讲积分图(Integral image),不是因为它不重要,正相反,它是Haar分类器能够实时检测人脸的保证。当我把Haar分类器的主脉络都介绍完后,其实在这里引出积分图的概念恰到好处。
在前面的章节中,我们熟悉了Haar-like分类器的训练和检测过程,你会看到无论是训练还是检测,每遇到一个图片样本,每遇到一个子窗口图像,我们都面临着如何计算当前子图像特征值的问题,一个Haar-like特征在一个窗口中怎样排列能够更好的体现人脸的特征,这是未知的,所以才要训练,而训练之前我们只能通过排列组合穷举所有这样的特征,仅以Viola牛提出的最基本四个特征为例,在一个24×24size的窗口中任意排列至少可以产生数以10万计的特征,对这些特征求值的计算量是非常大的。
而积分图就是只遍历一次图像就可以求出图像中所有区域像素和的快速算法,大大的提高了图像特征值计算的效率。
我们来看看它是怎么做到的。
积分图是一种能够描述全局信息的矩阵表示方法。积分图的构造方式是位置(i,j)处的值ii(i,j)是原图像(i,j)左上角方向所有像素的和:
积分图构建算法:
1)用s(i,j)表示行方向的累加和,初始化s(i,-1)=0;
2)用ii(i,j)表示一个积分图像,初始化ii(-1,i)=0;
3)逐行扫描图像,递归计算每个像素(i,j)行方向的累加和s(i,j)和积分图像ii(i,j)的值
s(i,j)=s(i,j-1)+f(i,j)
ii(i,j)=ii(i-1,j)+s(i,j)
4)扫描图像一遍,当到达图像右下角像素时,积分图像ii就构造好了。
积分图构造好之后,图像中任何矩阵区域的像素累加和都可以通过简单运算得到如图所示。
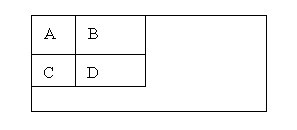
设D的四个顶点分别为α、β、γ、δ,则D的像素和可以表示为
Dsum = ii( α )+ii( β)-(ii( γ)+ii( δ ));
而Haar-like特征值无非就是两个矩阵像素和的差,同样可以在常数时间内完成。














 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









