










前面的文章我们已经完成了Kafka基于Zookeeper的集群的搭建了。Kafka集群搭建请点我。记过几天的研究已经实现Spring的集成了。本文重点
jar包准备
- 集成是基于spring-integration-kafka完成的。我这里用的项目是maven。该jar包在maven的位置
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-kafka</artifactId>
<version>1.3.0.RELEASE</version>
</dependency>友情提醒:自己在网上看的教程多引入了kafka_2.10jar包。我的项目报错。建议搭建指引入和kafka相关的上面那个jar包
配置生产者(spring-kafka-producer.xml)
有了jar包我们只需要在spring的配置文件中配置就行了。这里我单独将生产者和消费者进行抽离配置
首先我们配置生产消息的频道(工具类),这个频道基于queue。最后我们在消息发送也是通过该类实现发送消息的
<int:channel id="kafkaProducerChannel">
<int:queue />
</int:channel>- 有了频道我们需要将频道和消息分类结合起来 , outbound-channel-adapter 。顾名思义发送+频道+分类。该类就是设置这三个的联系的。这里我们主要看的是kafka-producer-context-ref。他是生产者消息的来源地
<int-kafka:outbound-channel-adapter
id="kafkaOutboundChannelAdapterTopic" kafka-producer-context-ref="producerContextTopic"
auto-startup="true" channel="kafkaProducerChannel" order="3">
<int:poller fixed-delay="1000" time-unit="MILLISECONDS"
receive-timeout="1" task-executor="taskExecutor" />
</int-kafka:outbound-channel-adapter>- 生产者的类别设置。及消息的编码序列化等操作都是该类设置的
首先就是这里的topic。每个topic对应一个类。topic中的broker-list是kafka服务(集群)。key-serializer和key-encoder分别设置序列化和编码。两者只需要设置一个就行。value-class-type是消息的类型。value-serializer和value-encoder和key是一样的解释
<int-kafka:producer-context id="producerContextTopic"
producer-properties="producerProperties">
<int-kafka:producer-configurations>
<!-- 多个topic配置 broker-list kafaka服务
key_serializer value-serializer 就是用了自己的编码格式
value-class-type 指定发送消息的类型-->
<int-kafka:producer-configuration
broker-list="192.168.1.130:9091" key-serializer="stringSerializer"
value-class-type="java.lang.Object" value-serializer="stringSerializer"
topic="testTopic" />
<int-kafka:producer-configuration
broker-list="192.168.1.130:9091" key-serializer="stringSerializer"
value-class-type="java.lang.Object" value-serializer="stringSerializer"
topic="myTopic" />
</int-kafka:producer-configurations>
</int-kafka:producer-context>- 上面消费者设置的序列化我们需要单独设置一下。我们可以采用spring-integration-kafka提供的序列化类。但是用了那个序列只能传递字符串。我们可以从定义该类实现传递对象(包括字符串)
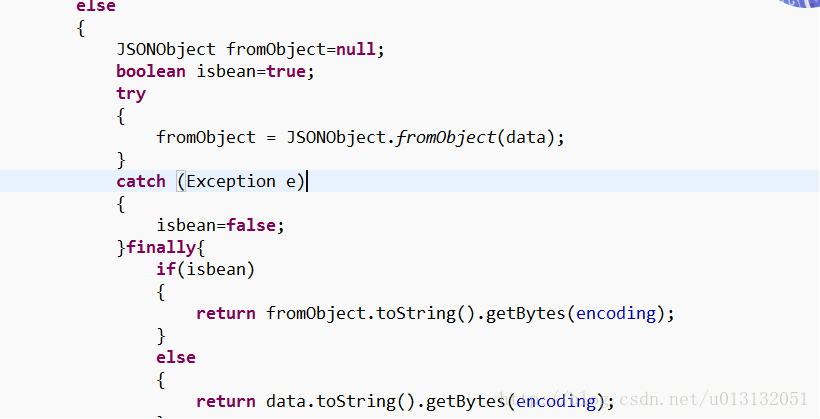
<bean id="stringSerializer" class="com.bshinfo.web.base.kafka.producer.MySerializer" />- 完整配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:int="http://www.springframework.org/schema/integration"
xmlns:int-kafka="http://www.springframework.org/schema/integration/kafka"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/integration/kafka http://www.springframework.org/schema/integration/kafka/spring-integration-kafka.xsd
http://www.springframework.org/schema/integration http://www.springframework.org/schema/integration/spring-integration.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd">
<!-- 生产者生产信息是键值对内容的格式。默认是 org.apache.kafka.common.serialization.StringSerializer
这里我们重写方法。便于方法传递对象 具体看MySerializer-->
<bean id="stringSerializer" class="com.bshinfo.web.base.kafka.producer.MySerializer" />
<!-- 这里的Encoder在下面没有用到 删掉也可以 Encoder和Serializer只用设置一个就行了。
consumer.xml中的配置也是一样 -->
<!-- <bean id="kafkaEncoder"
class="org.springframework.integration.kafka.serializer.avro.AvroReflectDatumBackedKafkaEncoder">
<constructor-arg value="com.kafka.demo.util.ObjectEncoder" />
</bean> -->
<!-- 生产者一些配置属性。不配置按默认执行 -->
<bean id="producerProperties"
class="org.springframework.beans.factory.config.PropertiesFactoryBean">
<property name="properties">
<props>
<prop key="topic.metadata.refresh.interval.ms">3600000</prop>
<prop key="message.send.max.retries">5</prop>
<!-- <prop key="serializer.class">com.kafka.demo.util.ObjectEncoder</prop> -->
<prop key="request.required.acks">1</prop>
</props>
</property>
</bean>
<!-- 生产者通过这个频道传送消息 基于queue-->
<int:channel id="kafkaProducerChannel">
<int:queue />
</int:channel>
<!-- 生产者发送消息设置 频道+方法配置 -->
<int-kafka:outbound-channel-adapter
id="kafkaOutboundChannelAdapterTopic" kafka-producer-context-ref="producerContextTopic"
auto-startup="true" channel="kafkaProducerChannel" order="3">
<int:poller fixed-delay="1000" time-unit="MILLISECONDS"
receive-timeout="1" task-executor="taskExecutor" />
</int-kafka:outbound-channel-adapter>
<task:executor id="taskExecutor" pool-size="5"
keep-alive="120" queue-capacity="500" />
<!-- 消息发送的主题设置。必须设置了主题才能发送相应主题消息 -->
<int-kafka:producer-context id="producerContextTopic"
producer-properties="producerProperties">
<int-kafka:producer-configurations>
<!-- 多个topic配置 broker-list kafaka服务
key_serializer value-serializer 就是用了自己的编码格式
value-class-type 指定发送消息的类型-->
<int-kafka:producer-configuration
broker-list="192.168.1.130:9091" key-serializer="stringSerializer"
value-class-type="java.lang.Object" value-serializer="stringSerializer"
topic="testTopic" />
<int-kafka:producer-configuration
broker-list="192.168.1.130:9091" key-serializer="stringSerializer"
value-class-type="java.lang.Object" value-serializer="stringSerializer"
topic="myTopic" />
</int-kafka:producer-configurations>
</int-kafka:producer-context>
</beans>- 最后我们在生产消息的地方注入我们配置文件中的频道就可以发送消息了


消费者配置(spring-kafka-consumer.xml)
上面的配置就可以实现消息的发送了。我们项目中会继续配置接收消息(消费者)。配置和生产者的配置一样。这里就不详细的解释了。代码里解释的很详细了。只不过里面多了配置Zookeeper的集群信息。还有一点因为在生产者我配置的序列化。所以这里为了配置全面这里采用配置的编码了
- 完整配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:int="http://www.springframework.org/schema/integration"
xmlns:int-kafka="http://www.springframework.org/schema/integration/kafka"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/integration/kafka
http://www.springframework.org/schema/integration/kafka/spring-integration-kafka.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task.xsd">
<!-- 接收的频道 也可以理解为接收的工具类 -->
<int:channel id="inputFromKafka">
<int:dispatcher task-executor="kafkaMessageExecutor" />
</int:channel>
<!-- zookeeper配置 可以配置多个 -->
<int-kafka:zookeeper-connect id="zookeeperConnect"
zk-connect="192.168.1.130:2181,192.168.1.130:2182,192.168.1.130:2183" zk-connection-timeout="6000"
zk-session-timeout="6000" zk-sync-time="2000" />
<!-- channel配置 auto-startup="true" 否则接收不发数据 -->
<int-kafka:inbound-channel-adapter
id="kafkaInboundChannelAdapter" kafka-consumer-context-ref="consumerContext"
auto-startup="true" channel="inputFromKafka">
<int:poller fixed-delay="1" time-unit="MILLISECONDS" />
</int-kafka:inbound-channel-adapter>
<task:executor id="kafkaMessageExecutor" pool-size="8" keep-alive="120" queue-capacity="500" />
<!-- <bean id="kafkaDecoder" class="org.springframework.integration.kafka.serializer.common.StringDecoder" /> -->
<bean id="kafkaDecoder" class="com.bshinfo.web.base.kafka.consumer.MyDecoder" />
<bean id="consumerProperties"
class="org.springframework.beans.factory.config.PropertiesFactoryBean">
<property name="properties">
<props>
<prop key="auto.offset.reset">smallest</prop>
<prop key="socket.receive.buffer.bytes">10485760</prop> <!-- 10M -->
<prop key="fetch.message.max.bytes">5242880</prop>
<prop key="auto.commit.interval.ms">1000</prop>
</props>
</property>
</bean>
<!-- 消息接收的BEEN -->
<bean id="kafkaConsumerService" class="com.bshinfo.web.base.kafka.consumer.ConsumerMessages" />
<!-- 指定接收的方法 -->
<int:outbound-channel-adapter channel="inputFromKafka"
ref="kafkaConsumerService" method="processMessage" />
<int-kafka:consumer-context id="consumerContext"
consumer-timeout="1000" zookeeper-connect="zookeeperConnect"
consumer-properties="consumerProperties">
<int-kafka:consumer-configurations>
<int-kafka:consumer-configuration
group-id="default1" value-decoder="kafkaDecoder" key-decoder="kafkaDecoder"
max-messages="5000">
<!-- 两个TOPIC配置 -->
<int-kafka:topic id="myTopic" streams="4" />
<int-kafka:topic id="testTopic" streams="4" />
</int-kafka:consumer-configuration>
</int-kafka:consumer-configurations>
</int-kafka:consumer-context>
</beans>- 配置中消费者实现类
package com.bshinfo.web.base.kafka.consumer;
import java.util.Collection;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import net.sf.json.JSONArray;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class ConsumerMessages
{
private static final Logger logger = LoggerFactory.getLogger(ConsumerMessages.class);
public void processMessage(Map<String, Map<Integer, Object>> msgs)
{
logger.info("================================processMessage===============");
for (Map.Entry<String, Map<Integer, Object>> entry : msgs.entrySet())
{
logger.info("============Topic:" + entry.getKey());
System.err.println("============Topic:" + entry.getKey());
Map<Integer, Object> messages = entry.getValue();
Set<Integer> keys = messages.keySet();
for (Integer i : keys)
{
logger.info("======Partition:" + i);
System.err.println("======Partition:" + i);
}
Collection<Object> values = messages.values();
for (Iterator<Object> iterator = values.iterator(); iterator.hasNext();)
{
Object object = iterator.next();
String message = "["+object.toString()+"]";
logger.info("=====message:" + message);
System.err.println("=====message:" + message);
JSONArray jsonArray = JSONArray.fromObject(object);
for (int i=0;i<jsonArray.size();i++)
{
Object object2 = jsonArray.get(i);
System.out.println(object2.toString());
/*JSONObject object2 = (JSONObject) jsonArray.get(i);
UserInfo userInfo = (UserInfo) JSONObject.toBean(object2,UserInfo.class);
System.out.println(userInfo.getRealName()+"@@@"+userInfo.getUserSex());*/
}
}
}
}
}
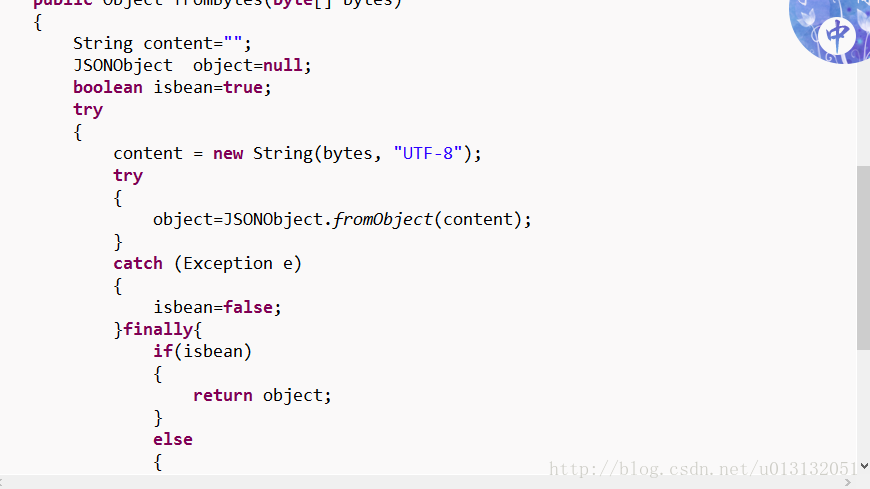
- 消费者中转码的工具类














 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









