







本文主要是针对“Latent Dirichlet Allocation”部分的解读。该paper除了提出LDA,还将其与LSI,pLSI以及其他生成模型做了对比。另外它提到了LDA的一个简化版本,其实这个简化版本就足够用来做tweet的情感分析了。
Note: All snapshots and formula below come from the paper "Latent Dirichlet Allocation" 。Appreciation for their great work!
I Latent Dirichlet Allocation
文本处理中,最传统的做法是将文档用tf-idf向量表示。这里,tf-idf其实也可以看成一种降维的方法。但这种方法降维的力度比较小,而且无法体现更抽象的含义。因此,后续出现了LSI,它对term-document矩阵进行奇异值分解。降维的效果是好了,但LSI没有对应的generative(生成)模型,而且SVD的复杂度是O(N^3)。后来,Hofmann提出一个概率上的生成模型pLSI。其公式如下:
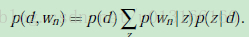
其中,每个word来自一个mixture model。Mixture Component是latent topic概率上的表示p(w|z)——即不同的topic下,每个word出现的频率也是不一样的。 Mixture Weight是p(z|d),它表示每篇文章有不同的topic distribution。可见在pLSA中,一篇文章可以是多个topic的混合,表现为不同单词可以来自不同的topic。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









