







由于item-based CF算法能对新用户进行推荐,并且能对推荐做出合理的解释,因此它在商用中的应用是很普遍的。[35]主要的贡献则是将item-based CF算法使用map-reduce框架并行化。作者指出,在0-1评分下,基于物品的相似度的计算可以写成这个这样子(A是以user为行,item为列的矩阵,S是要计算的物品相似度矩阵):
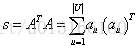
其中,a_u表示用户u在A中对应的行,也就是u的评分记录(比如有看过的电影为1,没有的为0)。
所以,将整个评分矩阵按行(用户)存于HDFS中。每个map task求每一行与自身的外积(outer product),最后使用reduce task将map的结果聚合起来,就能将物品的相似度计算并行化了。具体算法如下:

算法中相似度的计算用函数similarity(d, n[i], n[j])表示。很多基于两个向量内积(inner product, dot)的相似度都可以在这个框架中实现,最常见的有Cosine (余弦相似度),Pearson correlation(皮尔逊系数),和 Jaccard coeffieient(雅卡尔系数)。具体计算还涉及预处理,可以参见论文。整个相似度的计算涉及2次map-reduce迭代。第3次map-reduce迭代用于去掉低于某个threshold的相似度,以此降低物品相似度矩阵的密度。这种做法对item-based CF 算法性能的影响是很小的,因为一个物品的邻域一般定义为:与他相似度最高的前K个其他物品。
得到相似度矩阵S后,如果一个mapper task的内存能容下整个矩阵,那么可以将S放在hadoop的分布式缓存(distributed cache)中。接下来只使用map阶段就能进行推荐计算。但是一般情况下S会很大,那得将S和用户评分记录都存在磁盘上,推荐最后使用reduce来完成。不管怎么样,使用map-reduce框架来做推荐只适合批量推荐的情况。
最后,从公式(1)可以看到,处理一行的计算量最坏情况决于,评分最多的那个用户到底评了多少个。假设为N个,那么计算量就是N^2。不幸的是,虽然数量很少很少,但总有那么一些个用户的评分是很多的。如下图所示:
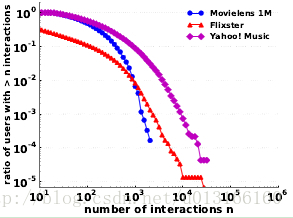
可以看到,在Yahoo! Music数据集中,虽然50%以上的用户评论数最多不超过1000个,但有少数用户的(被作者称为”power user”)评分数达到了1w多个。于是乎,这些power user在公式(1)中处理起来则比一般用户要慢100倍。为了处理这个问题,作者采用对这些”power user”采用的方法——每个人只抽取p个物品。 最终,相似度矩阵S计算的复杂度只有|U|p^2——随着用户数线性增长。
实验结果表示,这种采样的做法不会对性能造成多少影响。其中的一个解释是:这些”power user” 由于评论了太多东西,它对物品相似度贡献的参考价值反而降低了。 Why? 回顾一下,这里物品相似度计算的基本思路是:对于物品i和j,共同评价(喜欢)它们的用户越多,则他们越相似。评分少的用户u可能是因为他更趋向于某一类的物品,因而被u共同评分的两个物品相互之间很可能是有借鉴价值的。On the other hand, 虽然很可能有用户评论了所有的物品,但很明显不是所有物品都相似。这个问题在推荐问题中可以被称为active user problem。
[1] Scalable Similarity-Based Neighborhood Methods with MapReduce














 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









