







Abstract
We investigated a novel deep learning method to recognize clinical entities in Chinese clinical documents using the minimal feature engineering approach.
We developed a deep neural network (DNN) to generate word embeddings from a large unlabeled corpus through unsupervised learning and another DNN for the NER task.
两次DNN方法,一次生成词嵌入,第二次用作实体识别。
Introduction
介绍electronic health record的应用价值,以及面临实体识别的问题。
Many existing clinical NLP systems use dictionariesand rule-based methods to identify clinical concepts, such as MedLEE, MetaMap, cTAKES.
More recently, a number of challenges on NER involving shared tasks in clinical text have been organized, including the 2009 i2b2, the 2010 i2b2, the 2013 Share/CLEF challenge and the 2014 Semantic Evaluation challenge.(有空着重了解下=_=)
Conventional ML-based methods have been applied to Chinese clinical NER tasks.
In summary, current efforts on NER in Chinese clinical text primarily focus on investigating different machine learning algorithms or optimizing combinations of different types of features via human engineering.
最近越来越多人对基于深度学习的NLP系统感兴趣。这种系统能从大规模的未标注的语料通过非监督的方法学习到有用的特征表达式。深度学习是一个能通过深度神经网络学习高级特征表达的机器学习的研究领域。现在在图像处理,语音自动识别和机器翻译方面获得了先进的表现。NLP研究者开发出DNNs从大量的未标注的数据中去学习有用的特征,不再用花费大量时间去寻找任务特性的特征。Dr. Ronan Collobert的系统通过单个深度神经网络在很多NLP任务中获得了最先进的表现。
本文首个应用DNNs研究中文病历NER,并对比了传统的CRF方法。
Methods
Datasets
共两个数据集,第一个是来自Lei(雷建波)等人先前的研究中标注好的数据集。包含了北京协和医科大学附属医院的EHR数据库随机选择的400份入院记录。每份入院记录标注problem, lab tests, procedure, and medication. 具体数量见下表。
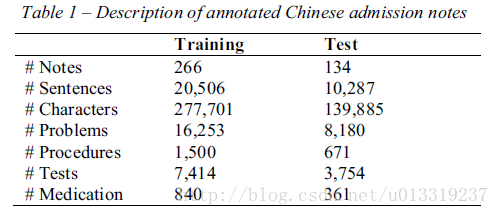
另外一个数据集,同样来自协和医院,包含了36828份未标注的入院记录用作学得字嵌入。使用单个汉字训练嵌入矩阵,预处理不用分词。
Experiments and evaluation
对比了三种NER方法:
- 传统的基于CRF的NER方法,可见Lei的论文。
- 基于DNN的NER方法用随机初始化的字嵌入矩阵。
- 另一个使用从未标注语料库导出的字嵌入矩阵的基于DNN的NER方法。
All scores were calculated using the Conll 2000 challenge official evaluation script 1. Wilcoxon signed-ranks test was used to test the statistical significance between two classifiers.
CRF vs.DNN Appraoches
CRF-based NER
The CRFs model decodes the sequence labeling problem by undirected Markov chain and Viterbi algorithm with a training criteria of maximizing the likelihood estimation of conditional probability of the output variable y given the observation x.
CRFs was intrinsically designed for sequence labeling problem as it models the relationships between neighboring tokens in sequence.
DNN-based NER
系统架构图如下: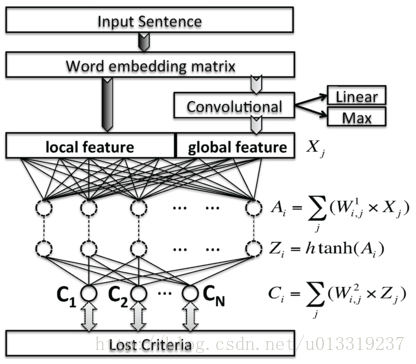
In this research, we adopted one of the popular architectures from Dr. Ronan Collobert – the sentence level log-likelihood approach [23], which consists of a convolutional layer, a non-linear layer using the hard version of the hyperbolic tangent (HardTanh), and several linear layers.
接下来讲述,每层的公式以及公式含义,词嵌入方法的优点,以及学习率等一些参数的确定。
(算法的具体细节在这里不再详述,毕竟我看不懂,慢慢再说~)
Results
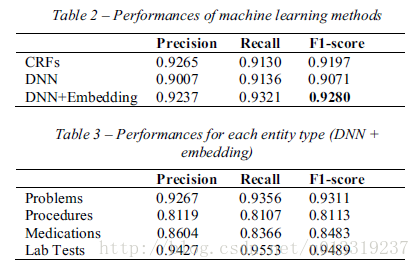
结果如下图,不再详述。
Discussion
(待完善)
Conclusion
(待完善)














 2792
2792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









