







在正题之前,先了解一下java下抓取网页上特定内容的方法,也就是所谓的网络爬虫,在本文中只会涉及简单的文字信息与链接爬取。java中访问http的方式不外乎两种,一种是使用原生态的httpconnection,还有一种是使用封装好的插件或框架,如httpclient,okHttp等。在测试爬取网页信息的过程中,本人是使用的jsoup工具,因为该工具不仅仅封装了http访问,还有强大的html解析功能,详细使用教程可参考http://www.open-open.com/jsoup/。
第一步,访问目标网页
Document doc = Jsoup.connect("http://bbs.my0511.com/f152b").get();
第二步,根据网页所需内容的特定元素使用jsoup的选择器选取(使用正则表达式效率更高),在这个例子中,目标网页是一个论坛,而我们所需要做的是爬取论坛首页所有帖子的标题名与链接地址。
先打开目标网址,使用谷歌浏览器浏览网页结构,找到结构所对应的内容,如下图所示

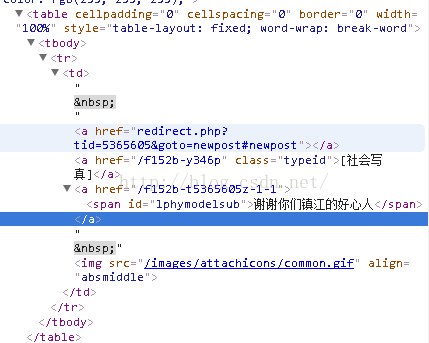
接着选取区域
Elements links = doc.getElementsByAttributeValue("id","lphymodelsub");
接下来对选取区域的内容进行获取,保存到数组中
for (Element link : links) {
CatchModel c = new CatchModel();
String linkHref = "http://bbs.my0511.com"+link.parent().attr("href");
String linkText = link.text();
c.setText(linkText);
c.setUrl(linkHref);
fistCatchList.add(c);
}
这样一个简单的抓取就完成了。
接下来就是新浪微博的抓取,一般的http访问新浪微博网站得到的html都是很简略的,因为新浪微博主页是用js动态生成的并且要进过多次的http请求与验证才能访问成功,所以为了数据抓取的简便,我们走一个后门,也就是访问新浪微博的手机端,weibo.cn进行抓取,但随之而来的一个问题是,新浪微博的访问不管哪一端都需要强制的登陆验证,所以我们需要在http请求的时候附带一个cookie进行用户验证。在网上找了好久使用webcontroller这个开源的爬虫框架,访问很简便,效率也高,那记下来我们就看看如何使用这个框架。
首先需要导入依赖的包,WebController的ja包与selenium的jar包
下载地址:http://download.csdn.net/detail/u013407099/9409372
利用Selenium获取登陆新浪微博weibo.cn的cookie(WeiboCN.java)
利用WebCollector和获取的cookie爬取新浪微博并抽取数据(WeiboCrawler.java)
WeiboCN.java
import java.util.Set;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 利用Selenium获取登陆新浪微博weibo.cn的cookie
* @author hu
*/
public class WeiboCN {
/**
* 获取新浪微博的cookie,这个方法针对weibo.cn有效,对weibo.com无效
* weibo.cn以明文形式传输数据,请使用小号
* @param username 新浪微博用户名
* @param password 新浪微博密码
* @return
* @throws Exception
*/
public static String getSinaCookie(String username, String password) throws Exception{
StringBuilder sb = new StringBuilder();
HtmlUnitDriver driver = new HtmlUnitDriver();
driver.setJavascriptEnabled(true);
driver.get("http://login.weibo.cn/login/");
WebElement mobile = driver.findElementByCssSelector("input[name=mobile]");
mobile.sendKeys(username);
WebElement pass = driver.findElementByCssSelector("input[name^=password]");
pass.sendKeys(password);
WebElement rem = driver.findElementByCssSelector("input[name=remember]");
rem.click();
WebElement submit = driver.findElementByCssSelector("input[name=submit]");
submit.click();
Set<Cookie> cookieSet = driver.manage().getCookies();
driver.close();
for (Cookie cookie : cookieSet) {
sb.append(cookie.getName()+"="+cookie.getValue()+";");
}
String result=sb.toString();
if(result.contains("gsid_CTandWM")){
return result;
}else{
throw new Exception("weibo login failed");
}
}
}
WeiboCrawler.java
import cn.edu.hfut.dmic.webcollector.model.CrawlDatum; import cn.edu.hfut.dmic.webcollector.model.CrawlDatums; import cn.edu.hfut.dmic.webcollector.model.Page; import cn.edu.hfut.dmic.webcollector.net.HttpRequest; import cn.edu.hfut.dmic.webcollector.net.HttpResponse; import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; /** * 利用WebCollector和获取的cookie爬取新浪微博并抽取数据 * @author hu */ public class WeiboCrawler extends BreadthCrawler { String cookie; public WeiboCrawler(String crawlPath, boolean autoParse) throws Exception { super(crawlPath, autoParse); /*获取新浪微博的cookie,账号密码以明文形式传输,请使用小号*/ cookie = WeiboCN.getSinaCookie("你的用户名", "你的密码"); } @Override public HttpResponse getResponse(CrawlDatum crawlDatum) throws Exception { HttpRequest request = new HttpRequest(crawlDatum); request.setCookie(cookie); return request.getResponse(); } @Override public void visit(Page page, CrawlDatums next) { int pageNum = Integer.valueOf(page.getMetaData("pageNum")); /*抽取微博*/ Elements weibos = page.select("div.c"); for (Element weibo : weibos) { System.out.println("第" + pageNum + "页\t" + weibo.text()); } } public static void main(String[] args) throws Exception { WeiboCrawler crawler = new WeiboCrawler("weibo_crawler", false); crawler.setThreads(3); /*对某人微博前5页进行爬取*/ for (int i = 1; i <= 5; i++) { crawler.addSeed(new CrawlDatum("http://weibo.cn/zhouhongyi?vt=4&page=" + i) .putMetaData("pageNum", i + "")); } crawler.start(1); } }
最新抓取方法:http://blog.csdn.net/u013407099/article/details/51424448














 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









