







一、需求分析
模拟登陆新浪微博,爬取新浪微博的热门话题版块的24小时内的前TOP500的话题名称、该话题的阅读数、讨论数、粉丝数、话题主持人,以及对应话题主持人的关注数、粉丝数和微博数。
二、开发语言
python2.7
三、需要导入模块
import requests
import json
import base64
import re
import time
import pandas as pd
四、抓取流程
首先先手机端模拟登陆新浪
然后发送请求得到网页源代码数据
之后用正则表达式解析数据
五、字段说明
话题名称:topic_name
阅读数:topic_reading
讨论数:topic_discuss
话题粉丝数:topic_fans
话题主持人:host_name
主持人关注数:host_follow
主持人粉丝数:host_fans
主持人微博数:host_weibo
六、抓取步骤
1、模拟登录新浪微博(手机版), 解密,用requests发送post请求,session方法记住登录状态。
###########模拟登录新浪
def login(username, password):
username = base64.b64encode(username.encode('utf-8')).decode('utf-8')
postData = {
"entry": "sso",
"gateway": "1",
"from": "null",
"savestate": "30",
"useticket": "0",
"pagerefer": "",
"vsnf": "1",
"su": username,
"service": "sso",
"sp": password,
"sr": "1440*900",
"encoding": "UTF-8",
"cdult": "3",
"domain": "sina.com.cn",
"prelt": "0",
"returntype": "TEXT",
}
loginURL = r'https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.15)'
session = requests.Session()
res = session.post(loginURL, data = postData)
jsonStr = res.content.decode('gbk')
info = json.loads(jsonStr)
if info["retcode"] == "0":
print(U"登录成功")
# 把cookies添加到headers中,必须写这一步,否则后面调用API失败
cookies = session.cookies.get_dict()
cookies = [key + "=" + value for key, value in cookies.items()]
cookies = "; ".join(cookies)
session.headers["cookie"] = cookies
else:
print(U"登录失败,原因: %s" % info["reason"])
return session
session = login('新浪微博账号', '新浪微博密码')2、定义列表数据结构存储数据。
##################定义数据结构列表存储数据
top_name = []
top_reading = []
top_discuss = []
top_fans = []
host_name = []
host_follow = []
host_fans = []
host_weibo = []
url_new1=[]
url_new2=[]3、请求翻页实现,用Fiddle 抓包工具 抓取请求url,点点击下一页时,发现真正请求url,通过拼接 page 来实现翻页
4、解析网页采用正则表达式re.findall()
#####正则表达式匹配
name=re.findall("Pl_Discover_Pt6Rank__5(.*?)</script>",html,re.S)
for each in name:
# print each
5、主持人有三个数据是从手机端抓取的,通过分析(按F12分析XHR请求 手机移动版的URL http://m.weibo.cn/api/container/getIndex?type=uid&value=5710151998
返回的是json ,数据,这里有用户的关注数,微博数,粉丝数。
通过解析json数据,得到这三个字段。
方法如下:
url="http://m.weibo.cn/api/container/getIndex?type=uid&value=5710151998"
html=session.get(url).content
html=json.loads(html)
userInfo=html['userInfo']
statuses_count=userInfo['statuses_count']
followers_count=userInfo['followers_count']
follow_count=userInfo['follow_count']
print statuses_count,followers_count,follow_count6、利用循环抓取数据之后,把数据组织成数据框的形式(表格)写入excel
7、通过 time模块 time.sleep(4) 方法控制网络请求速度。
七、结果图
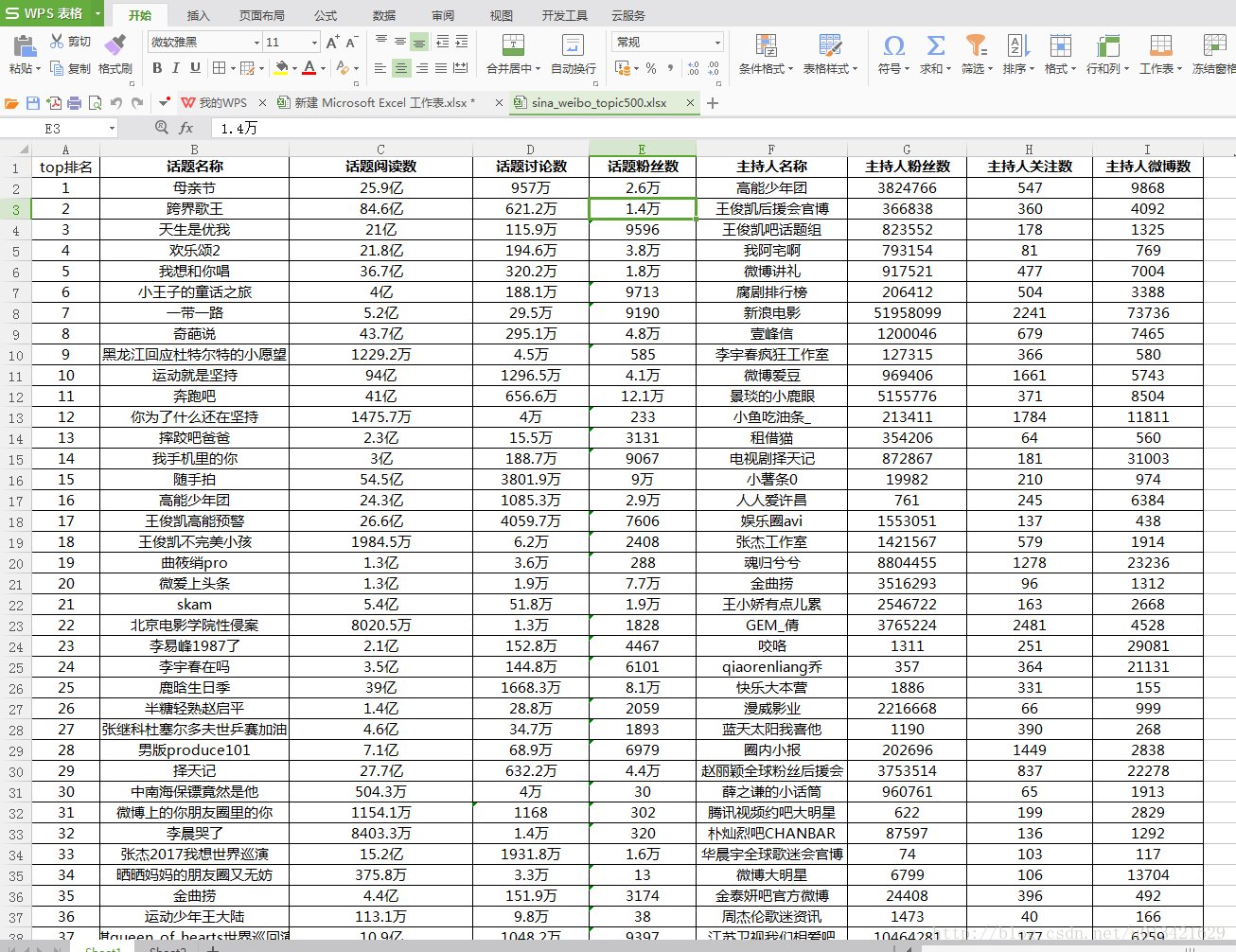
八、实现源代码
# encoding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
import json
import base64
import re
import time
import pandas as pd
time1=time.time()
###########模拟登录新浪
def login(username, password):
username = base64.b64encode(username.encode('utf-8')).decode('utf-8')
postData = {
"entry": "sso",
"gateway": "1",
"from": "null",
"savestate": "30",
"useticket": "0",
"pagerefer": "",
"vsnf": "1",
"su": username,
"service": "sso",
"sp": password,
"sr": "1440*900",
"encoding": "UTF-8",
"cdult": "3",
"domain": "sina.com.cn",
"prelt": "0",
"returntype": "TEXT",
}
loginURL = r'https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.15)'
session = requests.Session()
res = session.post(loginURL, data = postData)
jsonStr = res.content.decode('gbk')
info = json.loads(jsonStr)
if info["retcode"] == "0":
print(U"登录成功")
# 把cookies添加到headers中,必须写这一步,否则后面调用API失败
cookies = session.cookies.get_dict()
cookies = [key + "=" + value for key, value in cookies.items()]
cookies = "; ".join(cookies)
session.headers["cookie"] = cookies
else:
print(U"登录失败,原因: %s" % info["reason"])
return session
session = login('此处填写你的微博账号', '此处填写你的微博密码')
##################定义数据结构列表存储数据
top_name = []
top_reading = []
top_discuss = []
top_fans = []
host_name = []
host_follow = []
host_fans = []
host_weibo = []
url_new1=[]
url_new2=[]
#########################开始循环抓取
for i in range(1,501):
try:
print "正在抓取第"+str(i)+"页。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。"
url2="http://d.weibo.com/100803?pids=Pl_Discover_Pt6Rank__5&cfs=920&Pl_Discover_Pt6Rank__5_filter=hothtlist_type=1&Pl_Discover_Pt6Rank__5_page="+str(i)+"&ajaxpagelet=1&__ref=/100803&_t=FM_149273744327929"
html=session.get(url2).content
###########正则表达式匹配#######################
name=re.findall("Pl_Discover_Pt6Rank__5(.*?)</script>",html,re.S)
for each in name:
# print each
k=re.findall('"html":"(.*?)"}',each,re.S)
for each1 in k:
k1=str(each1).replace('\\t',"").replace('\\n','').replace('\\','').replace('#','')
# print k1
k2=re.findall('alt="(.*?)" class="pic">',str(k1),re.S)
for each2 in k2:
print each2
top_name.append(each2)
k3=re.findall('</span><a target="_blank" href="(.*?)" class="S_txt1" >',str(k1),re.S)
for each3 in k3:
print each3
url_new1.append(each3)
heads={
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate, sdch",
"Accept-Language":"zh-CN,zh;q=0.8",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Host":"weibo.com",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36"}
html2=session.get(each3,headers=heads).content
time.sleep(4)
p1=re.findall('Pl_Core_T8CustomTriColumn__12(.*?)</script>',str(html2),re.S)
for each3_1 in p1:
p2=str(each3_1).replace('\\t',"").replace('\\n','').replace('\\','').replace('#','')
# print p2
p3=re.findall('阅读</span>r<td class="S_line1">r<strong (.*?)</strong><span class="S_txt2">讨论</span>',str(p2),re.S)
for each3_2 in p3:
print str(each3_2).replace('class="">','').replace('class="W_f12">','').replace('class="W_f16">','').replace('class="W_f14">','').replace('class="W_f18">','')
top_discuss.append(str(each3_2).replace('class="">','').replace('class="W_f12">','').replace('class="W_f16">','').replace('class="W_f14">','').replace('class="W_f18">',''))
p4=re.findall('><strong class(.*?)</strong><span class="S_txt2">粉丝',str(p2),re.S)
for each3_3 in p4:
print str(each3_3).replace('="">','').replace('="W_f12">','').replace('="W_f16">','').replace('="W_f14">','').replace('="W_f18">','')
top_fans.append(str(each3_3).replace('="">','').replace('="W_f12">','').replace('="W_f16">','').replace('="W_f14">','').replace('="W_f18">',''))
k4=re.findall('阅读数:<span><span class="number">(.*?) </span></div> <div class="sub_box W_fl">',str(k1),re.S)
for each4 in k4:
print each4
top_reading.append(each4)
k5=re.findall('主持人:<span><a target="_blank" href="(.*?)" class="tlink S_txt1"',str(k1),re.S)
for each5 in k5:
print each5
mm=re.findall('\d+',str(each5),re.S)
for mm_1 in mm:
pp1="http://m.weibo.cn/api/container/getIndex?type=uid&value="+str(mm_1)
html3=session.get(pp1).content
html3=json.loads(html3)
userInfo=html3['userInfo']
statuses_count=userInfo['statuses_count']
followers_count=userInfo['followers_count']
follow_count=userInfo['follow_count']
print statuses_count,followers_count,follow_count
host_follow.append(follow_count)
host_fans.append(followers_count)
host_weibo.append(statuses_count)
url_new2.append(pp1)
k6 = re.findall('" class="tlink S_txt1" >(.*?)</a></div> </div><div class="opt_box"', str(k1), re.S)
for each6 in k6:
print each6
host_name.append(each6)
except:
pass
print len(top_name),len(top_reading),len(top_discuss),len(top_fans),len(host_name),len(url_new2),len(host_follow),len(host_fans),len(host_weibo)
data = pd.DataFrame({"top_name":top_name[0:501], "top_reading": top_reading[0:501],"top_discuss":top_discuss[0:501],"top_fans":top_fans[0:501],"host_name":host_name[0:501],\
"host_follow":host_follow[0:501],"host_fans":host_fans[0:501],"host_weibo":host_weibo[0:501]})
print len(data)
# 写出excel
writer = pd.ExcelWriter(r'C:\\sina_weibo_topic500.xlsx', engine='xlsxwriter', options={'strings_to_urls': False})
data.to_excel(writer, index=False)
writer.close()
time2 = time.time()
print u'ok,爬虫结束!'
print u'总共耗时:' + str(time2 - time1) + 's'















 1625
1625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











