







从100号部门开始,创建10个部门。
- delimiter $$
- drop procedure insert_dept $$
- create procedure insert_dept(in start int(10),in max_num int(10))
- begin
- declare i int default 0;
- set autocommit = 0;
- repeat
- set i = i + 1;
- insert into dept values((start + i),rand_string(10),rand_string(8));
- until i = max_num
- end repeat;
- commit;
- end$$
构建好海量数据后,我们执行一条查询语句,看看耗时多久:
select * from emp where empno = 123456;
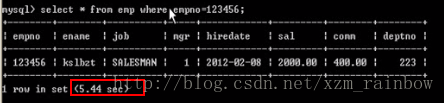
耗时5.44秒,这个耗时我们已经不能接受了。那么如何在一个项目中,找到慢查询的select语句呢?步骤如下:
(1)启用慢查询的机制(默认不启用)。MySQL数据库本身支持把慢查询语句记录到日志中,供程序员分析。
要这样启用:进入到MySQL的安装目录,在bin中有一个mysqld的文件:

如果没有启用慢查询,日志文件会根据my.ini配置文件中的配置存放,片段如下:
- datadir="C:/Documents and Settings/...(数据库地址) "
如果出现一次慢查询,就会将信息记录到这个文件中。
如果你的数据库引擎是MyISAM的,则当创建一个表以后,会创建三个文件,*.frm记录表结构,*.myd记录数据,*.myi是个索引文件。
(2)启动数据库的时候命令行启动,输入命令:mysqld.exe –slow-query-log启动。
(3)测试,查询select语句执行时间。
修改慢查询的默认时间:set long_query_time=1;
修改成一秒以后,很有可能出现慢查询,如果出现慢查询,就会将信息记录到my.ini指定的文件中去。
优化方案:
(1)建立适当的索引。
说起提高数据库性能,索引是最物美价廉的东西了,不用加内存,不用改程序,不用调用sql。
索引有四种:
主键索引(把某列设置为主键,就是主键索引)
唯一索引
普通索引
全文索引
例如:在emp表的empno列上建立索引。使用alter table语法。
给emp表的empno加上主键索引:alter table emp add primary key(empno);
观察emp.MYI文件的变化,执行这条语句之前,这个文件的大小是1K,执行之后变成了16M。为什么变大了呢?对我们有什么好处呢?这里我们再次按id查询emp表。
例如:select * from emp where empno =200000;
会发现用了0秒,这就是用空间换取了时间。
索引的原理:
数据库的一般查找方式是一行一行的找,这样效率很慢。
索引就是将所有数据的索引,另开辟一块空间存放,当查询的时候,先查询这块空间,找到对应数据的位置,在直接去这个位置上取数据,所以是用空间换取了时间。
但是这样的话,可能会造成插入删除修改出现问题,例如添加了一个数据进去,那么如果不为这个数据建立索引,就永远不可能知道这条数据的存在,就无法查询到这条数据。同样,如果删除了一条记录,但是没有删除索引,那么找索引的时候可以找到,但是索引对应的数据却没了。
小结:
(1)索引可以加快查询速度,但是对增删改是有影响的。但是增删改的次数要比查询少的多,所以还是可以的。而且是以空间换取时间。
(2)这个索引本身也要占空间。索引信息是存在于*.myi文件中的。
如何在执行之前就知道我们的语句能不能用到索引?通过一个工具实现。
非常重要的工具:explain
这是一个分析工具,可以在我们执行之前对sql语句进行分析,可以预测sql语句的执行效率。
例如:
explain select * from emp where empno =200000\G;
加G可以将结果纵向排列。
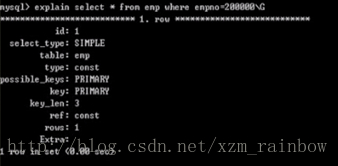
解释参数:
id = 1 代表分析的sql语句会使用到的索引。
table = emp表示对哪张表查询。
type : const表示的是表的连接类型。Type有三种:ALL,system,const
如果显示的是ALL,表示结果将会很慢。之前的empno字段加了索引,如果我们按照empno查询就不会是ALL,但是按照没有加索引的字段,就会是ALL了,也就是全表扫描,结果会很惨。
如果是system,表示这个表仅有一行(=系统表),这是const连接类型的一个特例。
Const这个表最多有一个匹配行。
possible_keys:PRIMARY表示可能用到的索引,PRIMARY表示用的是主键索引。
key:PRIMARY表示实际用到的索引。
key_len:3表示索引的长度
rows:1表示检索了多少条数据后才将目标数据取出来。这里因为有索引,所以直接找到,就是1,
如果将索引去掉,会变得很大。
Extra:也是一个很重要的信息,可以查询细节信息。有如下几个值:
Notables:即在Query中使用From dual或不含任何from语句,即没有查询具体的表。
Usingfilesort:指的是当前的查询需要排序,例如根据一个不是主键的列进行排序,就会
出现这个信息,会在文件里排序,尽量避免。
Usingtemporary:某些操作必须使用临时表,常见的有Group by 和 Order by。
Usingwhere :不用读取表中所有信息,仅通过索引就可以获取所需数据。
删掉empno的主键索引以后,再次执行这个查询语句,分析如下:
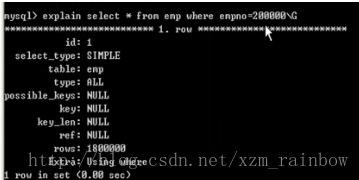
从上面的例子可以看出,如果为一个字段建立了主键,则自动建立索引,建立主键意味着表中的每一条记录都是唯一的,最少满足第二范式。
如果没有建立主键索引,则执行查询的时候,如按条件empno=200000查询,这里的empno不是主键,数据库会查询数据库所有记录,数据库不知道下面有没有符合empno=200000的,所以如果有empno=200000的,全部取出。而建立主键索引以后,意味着是唯一的,不会重复,一旦找到就不会再找了,而且主键可以直接找到需要的数据。
小结:explain的基本用法。
explain sql语句\G
根据返回的信息我们可以得知该sql是否使用索引,一共走了多少记录才取出,还可以看到排序的方式。
索引不是随便加的,根据非索引字段查询的时候还是很慢。
那么在哪些列上适合添加索引呢?
l 较频繁的被作为查询条件的字段应该创建索引。
如:select * from emp where empno = 1;这一类的id主键。
l 唯一性太差的字段不适合建立索引,比如男女,就两个值,很明确,就不用建立索引了。
l 更新非常频繁的字段不适合建立索引。刚建立了索引就要改动,索引也要变动。
l 不会出现在where子句中的字段不该创建索引。
上述内容主要是主键索引。
另一种索引:唯一索引(unique)。
为一列添加unique约束并不会为该列建立唯一索引。
具有唯一索引的列具有唯一性,同时又有索引。
建立唯一索引的语法:
create unique index index_name ontable_name(column_name[(length)][asc|desc],...)
全文索引的建立方式:
create fulltext index index_name ontable_name(column_name[(length)][asc|desc],...)
全文索引通常用于分词。中文的全文索引建立的比较少,英文的全文索引建立的多,因为英文的词是通过空格隔开的,分词容易。Sphinx可以做中文分词。
普通索引:index。
建立方式:alter table table_name ADD INDEX[index_name](index_column_name);
复合索引(多列合在一起)
建立:create index myind on 表名(列1,列2);
创建索引方式总结:
1),create [unique|FULLTEXT] index 索引名 on 表名(列名...);
2),alter table 表名 add index 索引名(列名...);
3),添加主键索引:
alter table 表名 add primary key(列...)
删除索引:
1)drop index 索引名 on 表名;
2)alter table 表名 drop index_name;
3)alter table 表名 drop primary key;
显示索引:
1)show index(es) from 表名\G;
2)show keys from 表名\G;
3)desc 表名;
索引的使用:
查询要使用索引,最重要的条件是查询条件中需要使用索引。
以下几种情况可能使用到索引:
1)对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。例如我们对一个表中的两列建立了复合索引,那么查询时,以第一列为条件查询效率会很高,如果以第二列为条件查询,效率依然低。
2)对于使用like的查询,查询如果是’%aaa’则不会使用到索引,如果是’aaa%’则会使用到索引。也就是说,查询是将%放到前面,索引是用不上的。将%放到中间也可以使用索引。
以下情况不会使用索引:
1)如果条件中有or是不会使用到索引的,例如我们通过explain分析以下两句:
Explain select * from dept where dname= ‘aaa’\G;
Explain select * from dept where dname= ‘aaa’ or loc = ‘aaa’\G;
则第一句会使用索引,第二句不会使用索引。
2)对于多列索引,不是使用的第一部分,则不会使用索引。
与刚才的一致,复合索引时,如果不使用最左边的列作为查询条件,是不会使用索引的。
3)like查询是以%开头。与刚才一致。
4)如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不会使用索引。
例如dname列是字符串类型,那么查询的时候必须:select * from dept where dname = ‘aaa’;
才会使用索引,如果:select * from dept wheredname = aaa;则不会使用索引。
5)如果MySQL估计使用全表扫描要比使用索引快,则不使用索引。
查看索引的使用情况(如何检测你的索引是否有效):
1)show status like ‘Handler_read%’;
Handler_read_key:这个参数值越高,表示索引使用的越好。
Handler_read_rnd_next:这个参数值越高,说明查询越低效。













 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









