






写在前面:
本文是对Jonathan Rentzsch(他的Twitter,GitHub)的Data alignment: Straighten up and fly right的翻译。此文从偏底层的方面,详要解释了内存对齐是什么,为什么需要内存对齐,有哪些方式,一些现实应用场景,以及对可能出现的“诡异”问题的分析。此分割线以下是全部译文,自己翻译,欢迎勘误。
对于那些直接操作内存的程序员来说,数据对齐是一个非常重要的课题。它关系到你的程序能运行得多好,甚至关系到你的程序是不是能运行。就像这篇文章阐述的一样,理解了数据对齐的原理,你也就能解释发生在某些处理器上的一些“诡异”现象了。
内存访问粒度
程序员习惯于认为内存是一连串字节组成的简单数组。在C语言族群中,char * 通常被认为是代表一片内存块,甚至在JavaTM中,也有类似的byte [] 类型来代表内存的含义。
图 1. 程序员眼中的内存分布

然而,你的计算机处理器并不是按照单字节为单位来读写内存的,而是通过2-字节,或4-字节,或8-字节,或16-字节甚至是32-字节为单位来访问内存的。我们把处理器访问内存的这个单位大小,叫做内存访问粒度 。
图 2. 处理器眼中的内存分布

相对于现代处理器而言,程序员处于整个内存架构的上层,处理器的实际工作方式对于程序员的正常使用来说是透明的。因为程序员理解中的内存处理方式与处理器实际的内存处理方式之间存在出入,所以有时就会导致一些意料之外的情况发生,本文要探索的,就是这些有趣的“意外”。
如果你没有真正理解对齐问题,在你的程序开发中也不重视它,那你的程序可能遇到以下相关的问题(按严重程度排序):
- 程序运行慢
- 程序卡死
- 操作系统崩溃
- 程序莫名其妙地运行失败,产生错误的结果
对齐的基本原理
对齐背后的逻辑究竟是怎样的,处理器的内存访问粒度是如果影响对齐的,为了把这些问题解释清楚,我需要你重复以下的一个小任务。这个任务很简单:首先,把从地址0开始的四个字节读到处理器的寄存器里面。然后,把从地址1开始的四个字节,还是读到同一个寄存器里面。
首先,让我们来分析一下,如果处理器以单字节为内存访问粒度时,会发生什么:
图 3. 单字节内存访问粒度
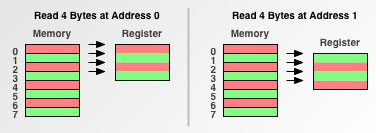
这样的内存处理方式,我们姑且把它称作是菜鸟程序员的内存模型:从地址0开始读数据是,他读了4个连续地址空间的数据到寄存器里;当从地址1开始读内存时,他又读了4个连续地址空间的数据到寄存器里面。现在,我们再来看看双字节内存访问粒度的处理器,比如最初的68000,是怎么处理的:
图 4. 双字节内存访问粒度

在从地址0开始读内存时,双字节处理器比单字节处理器的内存访问次数少了一半。因为每次内存访问都会有一些额外的开销,所以,减少内存访问的次数能提高性能。
接下来,请注意从地址1开始读内存时会发生什么。因为1这个地址序号不是双字节处理器的内存访问边界,所以处理器必须做一些额外的工作。这种情况下的地址1,就被称作未对齐地址 。因为地址1没有被对齐,所以双字节处理器必须多一次内存访问,性能也就相应地下降了。
最后,咱们看看四字节粒度的处理器,比如68030或PowerPC® 601,会怎么处理:
图 5. 四字节内存访问粒度
四字节处理器的一次读操作,就能从已对齐的地址空间中一次性地取出四个字节。对于未对齐地址,也只需要两次访问。
既然你已经理解了已对齐数据访问背后的原理,现在你可以尝试分析一下与数据对齐相关的一些问题。
懒惰的处理器
在访问未对齐地址时,处理器会有一些处理技巧。回想一下四字节处理器是怎样从地址1读取4个字节的例子,你应该能想出来处理器需要做的操作:
图 6. 处理器如何处理未对齐的地址访问
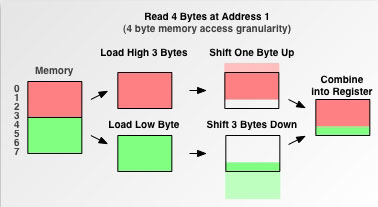
处理器会先去读取为对齐地址空间的第一个内存块,并且把后面不需要的若干字节移除掉。然后处理器会对第二个内存块做同样的操作。最后把这两次操作取出的数据拼接在一起,放入寄存器中。工作量比较大。
有些处理器甚至根本没帮你做这些工作。
初版的68000是双字节粒度的处理器,并且缺少能处理未对齐地址的电路。当遇到未对齐地址时,68000会抛异常。最初的Mac OS并不能很好地处理这种异常,经常会要求用户重启机器。真蛋疼。
之后的680x0系列处理器,比如68020,解决了这种限制,帮你做了这些必需的读取与拼接工作。这就是为什么一些老程序在68020芯片上正常运行,但是在68000上就会崩溃。这也解释了,为什么很久很久之前,一些老的Mac程序员总是用奇数地址来初始化指针了。在最初的Mac上,如果指针在被访问时没有被重新对齐到一个合适的地址,Mac会立刻进入Debugger模式,然后他们就能通过检查函数调用链的堆栈,来定位错误了。
在所有的处理器中,用于实际工作的晶体管的数量都是有限的。支持未对齐地址访问的晶体管能有效地减轻“晶体管负担”。在某些情况下,使用这类晶体管能使处理器的某些部分运转得更快,或者支持新功能。
MIPS就是一种以高速而著称的,支持未对齐地址访问功能的处理器。MIPS能够省去几乎所有不必要的细枝末节,从而显著地提高真实工作的效率。
PowerPC则是一种综合方案。迄今为止,每一个PowerPC处理器对于未对齐的32-bit整型数的访问提供硬件支持。虽然我们仍要为处理未对齐地址的访问付出一些额外的工作量,但是这样的工作量已经渐渐变得微乎其微,不值一提了。
在另一方面,现代的PowerPC处理器对于未对齐的64-bit浮点数的访问缺少硬件支持。当需要将一个未对齐的64-bit浮点数载入内存时,PowerPC处理器会抛出一个异常,让操作系统来处理程序中的数据对齐事项。在软件中执行数据对齐,远远慢于在硬件中执行。
速度
这里写了一些例子,来进一步解释未对齐内存访问的效率开销。例子很简单:读取一些数字,撤销,再把这些数字写会一个10M的内存区块。这些例子有两个参数:
- 申请的内存块的大小,以byte为单位。在申请的内存块内,你需要先每次只取1个字节,之后,你需要逐个尝试每次取2,4,8个字节。
- 内存块对齐的步长大小。你需要以这个数值为步长来移动指针,将内存块切割,以这个步长来对齐,然后再来执行每一个测试。
测试环境为800MHz PowerBook G4。为了避免受其他进程的影响,保证数据尽可能的准确,每个测试执行10次,取平均值。首先是每次操作一个字节:
方法 1. 一次处理一个字节
void Munge8( void *data, uint32_t size ) {
uint8_t *data8 = (uint8_t*) data;
uint8_t *data8End = data8 + size;
while( data8 != data8End ) {
*data8++ = -*data8;
}
}执行这个方法平均耗时67364ms。现在把它改成每次读两个字节,这样会把内存访问次数减半:
方法 2. 一次处理两个字节
void Munge16( void *data, uint32_t size ) {
uint16_t *data16 = (uint16_t*) data;
uint16_t *data16End = data16 + (size >> 1); /* Divide size by 2. */
uint8_t *data8 = (uint8_t*) data16End;
uint8_t *data8End = data8 + (size & 0x00000001); /* Strip upper 31 bits. */
while( data16 != data16End ) {
*data16++ = -*data16;
}
while( data8 != data8End ) {
*data8++ = -*data8;
}
}执行这个方法平均耗时48765ms,比Munge8快了38%,当然,这是在内存块已经被对齐的情况下。如果内存块并没有被对齐的话,执行时间大概增长到66385ms,比对齐的情况多了27%的时间。下图更直观地表示了访问已对齐内存与未对齐内存的效率差别。
图 7. 单次单字节 vs. 单次双字节
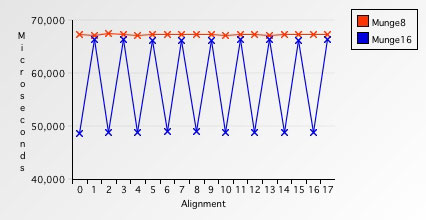
你可以看到,不管是对齐或是未对齐的内存,每次只访问一个字节总是比每次访问两个字节要慢。另外,有意思的是,如果内存地址序号不是2的倍数,访问内存就会多27%的开销。
现在,再把它改成每次访问四个字节:
方法 3. 每次访问四个字节
void Munge32( void *data, uint32_t size ) {
uint32_t *data32 = (uint32_t*) data;
uint32_t *data32End = data32 + (size >> 2); /* Divide size by 4. */
uint8_t *data8 = (uint8_t*) data32End;
uint8_t *data8End = data8 + (size & 0x00000003); /* Strip upper 30 bits. */
while( data32 != data32End ) {
*data32++ = -*data32;
}
while( data8 != data8End ) {
*data8++ = -*data8;
}
}对于已对齐内存,执行方法平均耗时43043ms,对于未对齐内存,平均耗时55775ms。因此,在这台测试机器上,访问已对齐内存时,每次访问四个字节的访问速度比两个的更慢。
图 8. 单字节 vs. 双字节 vs. 四字节内存访问对比
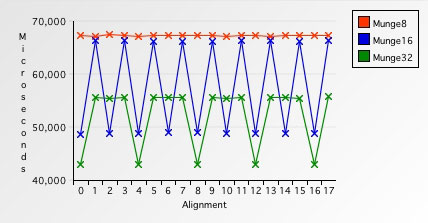
最后,咱们来试试每次访问八个字节。
方法 4. 每次访问八个字节
void Munge64( void *data, uint32_t size ) {
double *data64 = (double*) data;
double *data64End = data64 + (size >> 3); /* Divide size by 8. */
uint8_t *data8 = (uint8_t*) data64End;
uint8_t *data8End = data8 + (size & 0x00000007); /* Strip upper 29 bits. */
while( data64 != data64End ) {
*data64++ = -*data64;
}
while( data8 != data8End ) {
*data8++ = -*data8;
}
}对于已对齐内存,Munge64平均耗时39085ms,大概比每次访问四字节快了10%。然而,对于未对齐内存,却花了整整1841155ms,比已对齐内存慢了两个数量级,多了惊人的4610%的开销!
这其中到底发生了什么?因为现代PowerPC处理器缺少对于未对齐内存的硬件支持,对于每一次的未对齐内存访问,都会抛出一个异常。操作系统抓住此异常后,帮助程序做内存对齐,所以耗时会骤升。下图直观地展示了开销究竟有多大,什么时候的开销最大:
图 9. 各种访问步长的对比
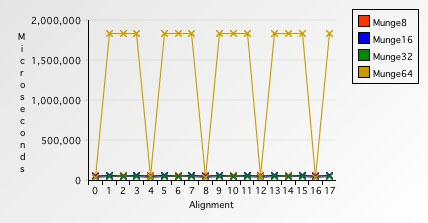
相对于对未对齐内存每次访问八字节来说,其他的几种情况耗时真是微不足道。可能我们只截取这张图的最下面的部分,能看得更直观:
图 10. 各种访问步长的对比 #2
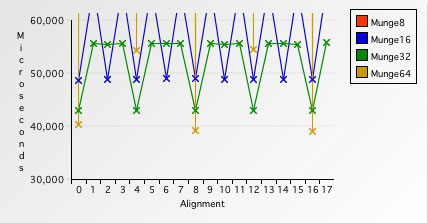
放大之后,我们能注意到,有一些微妙的地方。对比一下八字节访问速度和四字节访问速度的极值:
图 11. 各种访问步长的对比 #3
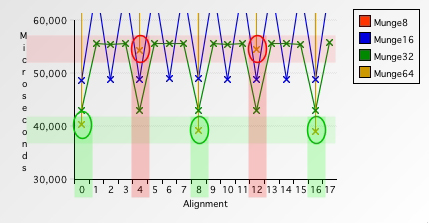
每八字节访问内存时,在第4和第12字节的位置,比每四字节访问甚至每两字节访问都要慢。即使PowerPC处理器对按四字节方式对齐的八字节长浮点数有硬件支持,你仍不可避免地需要一些开销。但是绝对不是4610%的开销,这样的开销实在太大了。结论:如果我们访问未对齐内存时,较大的步长比较小的步长更耗时。
原子性
所有现代处理器都支持原子指令。对于同步多个必须并行执行的操作来说,原子指令起到了至关重要的作用。就像它的名字“原子”一样,原子指令必须是不可见的,看不到,也摸不到,是暴露给外界的最小可执行块,这就是为什么用它们来做同步这么轻松:原子指令不允许被抢占。
为了能让原子指令正常地正确地执行,你传给它们的内存地址必须是4字节对齐的。这是因为原子指令和虚拟内存之间存在一些细微的相互影响。
如果内存地址不是已对齐的,那就至少需要两次内存访问。那么,如果需要的数据块是在虚拟内存的两块不同的页里面呢?可能我们需要的第一页已经被装载在内存里了,而第二块还没有。当我们取需要的数据块期间,会发现第二页不在内存中,这就需要调用虚拟内存切换的代码,这样就打破了原子指令的原子性。为了保证简洁和正确,68000系列和PowerPC处理器都自动地将内存地址划分为至少4字节对齐。
然而,对于PowerPC处理器,在保存一个未对齐地址时,它并不会抛异常,而是直接fail掉。这可能导致情况有些失控,因为在多数的原子方法中,当执行的终状态是fail时,它就会认定自己在执行的过程中被抢占了,所以会去继续重试。这就导致你的程序会出现死锁。蛋碎…
AltiVec
AltiVec的存在就是为了效率。未对齐内存访问拖慢了处理器,需要更昂贵的晶体管。因此,AltiVec继承自MIPS指令集,简单地不支持未对齐内存访问。因为AltiVec的访问步长是16字节,所有交由AltiVec处理的地址必须是按16字节对齐的。你根本不敢想象如果地址没有被对齐会发生什么。
AltiVec不会抛异常来警告你这是个未对齐的地址。它会直接忽略地址的最后4个bit位,然后在错误的地址上继续执行。这意味着,如果你不能保证你的数据是16位对齐的话,那你的程序就可能悄悄地污染了内存,或者返回错误的结果。
AltiVec这样武断的忽略处理也有好处。因为你就不需要显式地截断地址,当你把地址加载到处理器中时,这会省去你一到两个指令的操作。
当然,这也不是说AltiVec就完全无法处理未对齐内存。你可以在AltiVec编程环境手册中找到详细的处理方法。这需要更多的工作量,但是因为相比处理器,内存的速度实在是太慢太慢了,所以,事实上,这些改进的实际效果非常有限。
结构体对齐
方法 5. 一个菜鸟结构体
看看下面这个结构体:
void Munge64( void *data, uint32_t size ) {
typedef struct {
char a;
long b;
char c;
} Struct;这个结构体占多少字节呢?很多程序员都会回答“6字节”。看起来也有道理:a占1字节,b占4字节,c占1字节,1+4+1=6。下表描述它在内存中是怎么存储的:
表 1. 结构体的内存存储
| Field | Field Name | Field Offset | Field Size | Field End |
|---|---|---|---|---|
| char | a | 0 | 1 | 1 |
| long | b | 1 | 4 | 5 |
| char | c | 5 | 1 | 6 |
| Total Size in Bytes | 6 |
然后,当你实际运行sizeof(Struct)时,你的编译器返回的答案却大于6,可能是8或者甚至是24。有两个原因可能导致这样的结果:后台兼容性,效率。
首先,后台兼容性。还记得68000处理器是双字节内存访问粒度的吧,当遇到奇数地址时,会抛出一个异常。当你要读/写b字段时,你要访问的就是一个奇数地址。如果你没有装调试器的话,旧的Mac OS会抛出一个系统错误对话框,上面只要一个按钮:重启。蛋稀碎!
所以,编译器会必要地补齐结构体,保证b和c是从偶数地址开始的,而不是完全连续地按照你的代码中的顺序依次排列:
| Field | Field Name | Field Offset | Field Size | Field End |
|---|---|---|---|---|
| padding | 1 | 1 | 2 | |
| char | a | 0 | 1 | 1 |
| long | b | 1 | 4 | 5 |
| char | c | 5 | 1 | 6 |
| padding | 7 | 1 | 8 | |
| Total Size in Bytes | 8 |
补齐操作在结构体内添加了一些实际上是没有用的空间,目的就是为了保证其中的各个字段都能处于我们期望的地址。如今,因为68020处理器已经对未对齐内存访问提供了硬件支持,补齐操作也就不是必需的了。但是,就算是做了补齐也不会导致错误,甚至还会提升一些效率。
第二个原因就是效率。现如今,在PowerPC机器上,双字节对齐表现得已经很不错了,但是四字节对齐甚至八字节会表现得更优异。你可能不关心68000没有处理未对齐内存,但是你应该会关心结构体中未对齐的那个double字段可能带来的4610%的额外开销。
结论
如果你不理解数据对齐,并且在实际编码时不注意它:
- 你的程序可能会遇到因为未对齐内存访问异常带来的效率问题,而处理这样的异常会带来很大的开销。
- 你的程序不经意间可能会保存未对齐地址,导致程序死锁。
- 你的程序可能会把未对齐的地址传给AltiVec,导致AltiVec在错误的地址上执行读/写,导致数据污染或者输出错误结果。
致谢
感谢Alex Rosenberg和Ian Ollmann的反馈,Matt Slot的FastTimes定时库,和Duane Hayes提供的测试机器。
引用
略。见原文。














 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









