






重做红楼梦的数据分析-判断前80回后40回是否一个人写的
红楼梦的数据分析已经有许多人做过,结论也各不相同。
我在知乎上看到两篇帖子:
1. 通过数据挖掘能分析《红楼梦》各回的真伪吗?
2. 用机器学习判定红楼梦后40回是否曹雪芹所写
觉得很有意思,于是用自己的方法重做了一次
环境配置:
我主要使用的编程环境是Jupyter Notebook 4.2.1,因为可以调整每一个代码块,方便
纠错什么的。
然后我们得用到一个中文分词工具 - Jieba, 是由百度工程师Sun Junyi开发的
之后我们还得用到一些做机器学习/数据挖掘的标准包:numpy, matplotlib 和 sklearn
数据准备:
用爬虫思想,我去这个网站扒下来红楼梦全集,然后剪掉中间所有的换行符,使得每一回只
占文档中的一行。这样的话,方便接下来读取。
直接上代码:
一、导入各种需要的包
# -*-coding:utf-8 -*-
import urllib
import urllib2
import re
from bs4 import BeautifulSoup as bs
book = []
for i in range(120):
print("处理第{}回...".format(i+1))
if i+1<10:
url = "http://www.purepen.com/hlm/00{}.htm".format(i+1)
elif i+1 < 100:
url = "http://www.purepen.com/hlm/0{}.htm".format(i+1)
else:
url = "http://www.purepen.com/hlm/{}.htm".format(i+1)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
bsObj = bs(response.read().decode('gb18030')) #注意原网页的codec是哪一种
chapter = bsObj.table.font.contents[0]
book.append(chapter)下面是结果:

之后把全文存进一个txt文件:
with open('红楼梦.txt', 'w') as f:
f.write(codecs.BOM_UTF8)
for chap in book:
s = chap.encode('utf-8').strip()
f.write("".join(s.split()))
f.write('\n')数据ready,可以开始进行处理了
处理:
直接上代码:
一、导入各种需要的包
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 因为后面会用到3d作图
import operator
# 下面是机器学习包
from sklearn.cross_validation import train_test_split
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.decomposition import PCA
# Jieba
import jieba二、读取文件并分词
with open('红楼梦.txt') as f:
all_chaps = [chap.decode('utf8') for chap in f.readlines()]
# 给整本书分词
dictionary = []
for i in range(120):
print "处理第{}回".format(i+1)
words = list(jieba.cut(all_chaps[i]))
dictionary.append(words)三、Flatten数组 (中文是’摊平’? 哈哈)
tmp = [item for sublist in dictionary for item in sublist] # 摊平
dictionary = tmp四、 给每一回贴上标签
# 给每一回贴上标签
for i in range(120):
if i < 80:
all_chaps[i] = [all_chaps[i],'1']
else:
all_chaps[i] = [all_chaps[i],'0']
content = [row[0] for row in all_chaps]
label = [row[1] for row in all_chaps]五、找出每一回均出现的词
之所以要这么做,是因为有一些很常出现的角色名在后四十回因为剧情原因不再出现了。在整个分析中我们注重对于文言虚词和其他连接词的分析,因为这样更能体现出写作者的个人风格。另外,这也是为什么我们没有在Jieba里加入角色名称的字典,因为没有这个必要。
# 找出每一回均有出现的词
from progressbar import ProgressBar # 显示进度
pbar =ProgressBar()
wordineverychap = []
length = len(dictionary)
print "共有{}个词".format(length)
for word in pbar(dictionary):
n = 0
for text in content:
if word in text:
n+=1
if n==120:
wordineverychap.append(word)六、合并虚词,以防虚词被过滤掉
这里用的虚词是直接从维基百科上抄下来的,一共20个左右,所以也并不麻烦。
with open('xuci.txt') as f:
xuci = [word.decode('utf8').strip() for word in f.readlines()]
for word in xuci:
if word not in wordineverychap:
wordineverychap.append(word)七、过滤重复的词语,并去掉标点符号
selected_words = list(set(wordineverychap))
# 人工处理, 删除标点符号
for w in selected_words:
print w计算结果是一共有125个词语
八、给每个词语计数 并 排序
wordT = []
countT = []
table = {}
chapNo = 1
for chap in content:
sub_table = {}
for word in uw:
sub_table[word.decode('utf8')] = chap.count(word.decode('utf8'))
table[chapNo] = sub_table
chapNo+=1
import operator
table_sorted = []
for idx in table:
sub_table_sorted = sorted(table[idx].items(),key=operator.itemgetter(1),reverse=True)
table_sorted.append(sub_table_sorted)九、把数据存在csv里,以免不小心关掉程序后不用重新计算
# 任务:把数据存到csv里
import unicodecsv as csv
# 写入第一行和第一列
f1 = open('cipin.csv', 'w+')
writer = csv.writer(f1, encoding='utf8', delimiter=',')
first_row = [''] # A1留空
for i in range(120):
first_row.append('第{}回'.format(i+1))
writer.writerow(first_row)
for word in selected_words:
row = [word]
for i in range(120):
row.append(table[i+1][word.decode('utf8')])
writer.writerow(row)
f1.close()十、把数据向量化
# 任务:把数据向量化
all_vectors = []
for i in range(120):
chap_vector = []
for word in selected_words:
chap_vector.append(table[i+1][word.decode('utf8')])
all_vectors.append(chap_vector)
十一、把高维向量压缩为3维向量,方便作图
这里我们使用PCA(Principal Component Analysis),就是一种把高维度向量变成低维度向量的算法。比如我们现在每一回就有125维,无法作图。这个算法,像它的名字一样,会采集最重要的向量,然后压缩成到我们所需要的维数(3维)
#设置PCA的目标维数并创建一个model
pca = PCA(n_components=3)
#Feed我们的向量,进行训练
pca.fit(all_vectors)
#取得目标向量
z = pca.fit_transform(all_vectors)
#取得前八十回的向量
xs_a = [row[0] for row in z[:80]]
ys_a = [row[1] for row in z[:80]]
zs_a = [row[2] for row in z[:80]]
#取得后四十回的向量
xs_b = [row[0] for row in z[-40:]]
ys_b = [row[1] for row in z[-40:]]
zs_b = [row[2] for row in z[-40:]]
#创建一个新的图表
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
#绘图
ax.scatter(xs_a, ys_a, zs_a, c='r', marker='o')
ax.scatter(xs_b, ys_b, zs_b, c='b', marker='^')
plt.show()这就是绘制出来的图表:
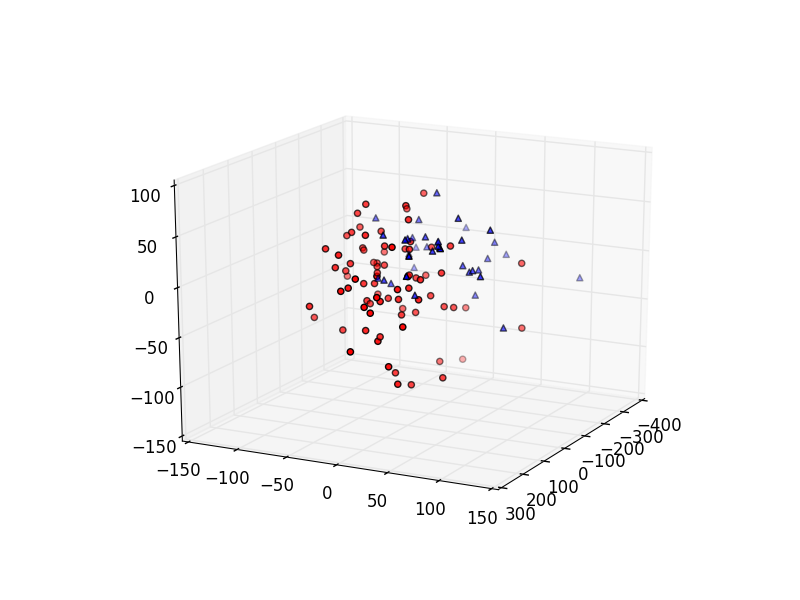
每一个点表示一回,红色的点表示的是前八十回,蓝色的点表示的是后四十回。从该图我们可以发现,前八十回和后四十回的写作者用词习惯有可观察到的不同,所以由此我们可以大胆的说,前后的写作者是不同的!
为了准确,我们还可以做一组对比试验,这次我们分别画出前四十回 ,中间四十回 和 后四十回:
#前四十回
xs_a = [row[0] for row in z[:40]]
ys_a = [row[1] for row in z[:40]]
zs_a = [row[2] for row in z[:40]]
#中间四十回
xs_b = [row[0] for row in z[40:80]]
ys_b = [row[1] for row in z[40:80]]
zs_b = [row[2] for row in z[40:80]]
#最后四十回
xs_c = [row[0] for row in z[-40:]]
ys_c = [row[1] for row in z[-40:]]
zs_c = [row[2] for row in z[-40:]]
ax.scatter(xs_a, ys_a, zs_a, c='b', marker='o')
ax.scatter(xs_b, ys_b, zs_b, c='y', marker='^')
ax.scatter(xs_c, ys_c, zs_c, c='r', marker='o')
plt.show()画出的图表是这样:
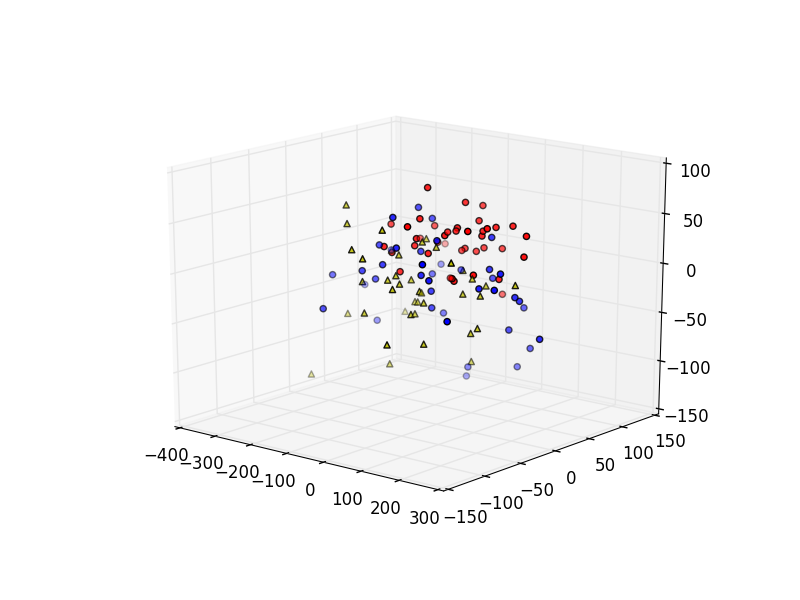
蓝色的是前四十回,绿色的是中间四十回,红色的是后四十回。在这个图里我们也能看到前四十回和中间四十回重合了很多,而后四十回相对独立。
十三、用机器学习的思路处理
简单的说,就是我们把前八十回和后四十回分别做标注,用‘1’表示属于前八十回,‘0’表示属于后四十回。接着我们从前八十回中抽16回,后四十回中抽8回用作训练样本,剩下的用作测试样本。如果训练出来的模型成功从预测样本中预测出是否属于前八十回,就代表我们的想法是对的—–前八十回和后四十回的用词习惯的确不同。
上代码:
label = []
for i in range(120):
if i<80:
label.append(1)
else:
label.append(0)
# 分出训练和测试样本
x_train, x_test, y_train, y_test = train_test_split(all_vectors, label, test_size=0.8)
# 使用GridSearch找到合适的参数
params = [{'C':[1,5,10,50,100,250,500]}]
grid = GridSearchCV(SVC(kernel='linear'),params,cv=10)
# 训练!
grid.fit(x_train,y_train)
# 预测
y_pred = grid.predict(x_test)
# 显示预测结果
print(classification_report(y_test, y_pred))最后我们的预测结果是这样的:
| prediction | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 0.85 | 0.97 | 0.90 | 29 |
| 1 | 0.98 | 0.93 | 0.95 | 67 |
| avg/total | 0.94 | 0.94 | 0.94 | 96 |
就结果而言,我们的模型比较准确的预测了测试样本属于哪个分类,说明我们的直观判断,可能是对的。
撒花~
欢迎转载














 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









