







为了用手机登录校网时不用一遍一遍的输入账号密码,于是决定用爬虫抓取学校登录界面,然后模拟填写本次保存的账号、密码,模拟点击登录按钮。实现过程折腾好几个。
一开始选择的是htmlunit解析登录界面html,在pc上测的能实现,结果在android上运行不起来,因为htmlunit利用了javax中的类实现的解析,android不支持javax,所以就跑不起来。
不过pc还是ok的
package com.yasin;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.List;
import org.junit.Test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlPasswordInput;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class AutoLogin {
String url = "http://172.16.10.3/";
@Test
public void run(){
try{
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage(url);
List<HtmlForm> forms = page.getForms();
HtmlForm form = forms.get(0);
HtmlTextInput name = form.getInputByName("DDDDD");
name.setValueAttribute("/*填写你的账号*/");
HtmlPasswordInput pass = form.getInputByName("upass");
pass.setValueAttribute("/*你的密码*/");
HtmlSubmitInput ok = form.getInputByName("0MKKey");
System.out.println(pass.toString());
ok.click();
}catch(Exception e){
System.out.println(e.toString());
}
}
}
于是接着调研,发现利用jsoup可以在android运行起来,不过这个库能抓取网页中的内容,也能进行赋值操作,但不支持模拟点击事件,网上有好多例子,是利用第一次访问获取cookie,然后把账号密码再给Post到服务器,完成模拟登陆。可以我们的校网竟然没有使用cookie,于是我只能抓包看看post的data有什么,然后把data直接通过post发送,不过不知道我们校网密码的加密的方式,所以填写密码需要先去抓包,抓到自己账号的密文,然后放到data中直接发送。成功了!
核心代码:
public void login() throws IOException{
Map<String,String> datas = new HashMap<String,String>();
Connection con = Jsoup.connect("http://172.16.10.3/");
con.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");//配置模拟浏览器
Response rs= con.execute();//获取响应
Document doc = Jsoup.parse(rs.body());
datas.put("DDDDD", "/*自己的账号*/");
datas.put("upass", "/*自己密码的密文,需抓包获取*/");
datas.put("R1", "0");
datas.put("R2", "1");
datas.put("0MMKey", "123456");
System.out.println(datas.toString());
Connection con2=Jsoup.connect("http://172.16.10.3/");
con2.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");
//设置cookie和post上面的map数据.cookies(rs.cookies())
Response login=con2.ignoreContentType(true).method(Method.POST).data(datas).execute();
Message msg = new Message();
msg.what = 1;
mHandler.sendMessage(msg);
}抓包方式:
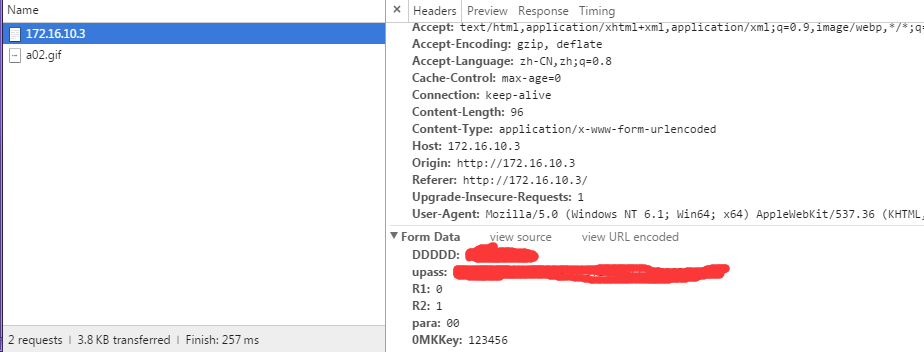
点击登录后快速停止监听,获取form data,然后把data中的值填上就好了。
———————————分割———————————————
总的来说,如果只是单纯抓取网页内容android这一块利用jsoup还是能实现的,但不支持按钮的点击操作;Htmlunit API更好用,也能模拟点击事件,不过javax android并不支持,但服务器还是可以用来抓取数据的。















 1754
1754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









