







Kmeans算法是在机器学习中常用的聚类算法,能够对一些杂乱无章的数据进行聚类,从而形成一个个比较近似的群体。本文主要介绍Kmeans的基本原理以及实现方法。
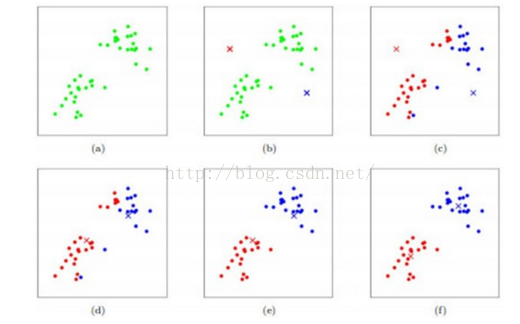
上图a中是一系列杂乱无章的数据,目的是对这些数据可以进行聚类,根据距离得到距离较近的群体,从图a中就可以用肉眼看出,左下面是一个群体,右上面是一个群体,如果可以通过kmeans算法分出肉眼的结果,那么该kmeans算法是比较令人满意的。
图b中随机选取了两个点,这两个数量就是kmeans中的k,这个k的选取需要进行评估,该k的选取对聚类后的效果影响较大,因为杂乱无章的数据能够分为多少个群体是没法得知的,可以通过抽取样本集等方法来进行人为评估和校验。这里也可以通过一些实际特征来划分,比如要对收入对所有用户进行分群,比如月入1万以下一类,1万到两万一类,2万到3万一类,三万以上一类等,这样的划分可以 让结果能符合人们的预期,即便可能最好的分类结果是一千以下是一类,一千到五千是一类,五千以上是一类等。
图c是每个点都跟聚类中心求距离,哪个距离最近,就分到哪一类中,从图中可以看出,以左下和右上的对角线对数据进行了划分,分为了两类。
图d是对分好的类进行类内部求平均值,也就是kmeans算法的means过程,求到平均值后,平均值就是新的聚类中心。迭代图b和图c的过程。
图e是得到的新的聚类结果。
多次迭代以后,发现聚类中心已经不再变化了,形成了一个收敛的状态,那么就完成了一个聚类过程。














 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









