






CNN
作者:叶 虎
编辑:李文臣
ShuffleNet是旷视科技最近提出的一种计算高效的CNN模型,其和MobileNet和SqueezeNet等一样主要是想应用在移动端。所以,ShuffleNet的设计目标也是如何利用有限的计算资源来达到最好的模型精度,这需要很好地在速度和精度之间做平衡。ShuffleNet的核心是采用了两种操作:pointwise group convolution和channle shuffle,这在保持精度的同时大大降低了模型的计算量。目前移动端CNN模型主要设计思路主要是两个方面:模型结构设计和模型压缩。ShuffleNet和MobileNet一样属于前者,都是通过设计更高效的网络结构来实现模型变小和变快,而不是对一个训练好的大模型做压缩或者迁移。下面我们将详细讲述ShuffleNet的设计思路,网络结构及模型效果,最后使用Pytorch来实现ShuffleNet网络。
,总通道数为g x n,首先你将通道那个维度拆分为(g x n)个维度,然后将这两个维度转置变成(n x g),最后重新reshape成一个维度。如果你不太理解这个操作,你可以试着动手去试一下,发现仅需要简单的维度操作和转置就可以实现均匀的shuffle。利用channle shuffle就可以充分发挥group convolution的优点,而避免其缺点。
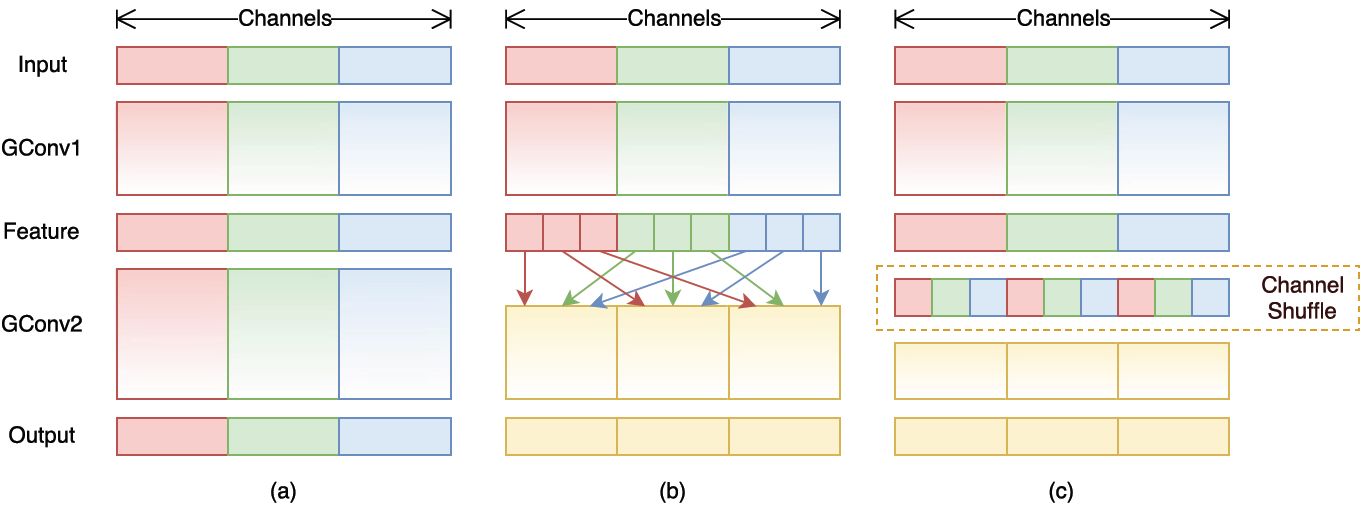
图1 使用channle shuffle后的group convolution
3
基于上面的设计理念,首先来构造ShuffleNet的基本单元,如图2所示。ShuffleNet的基本单元是在一个残差单元的基础上改进而成的。如图2-a所示,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),这里的3x3卷积是瓶颈层(bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。现在,进行如下的改进:将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个channle shuffle操作。值得注意的是3x3卷积后面没有增加channle shuffle,按paper的意思,对于这样一个残差单元,一个channle shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。改进之后如图2-b所示。对于残差单元,如果stride=1时,此时输入与输出shape一致可以直接相加,而当stride=2时,通道数增加,而特征图大小减小,此时输入与输出不匹配。一般情况下可以采用一个1x1卷积将输入映射成和输出一样的shape。但是在ShuffleNet中,却采用了不一样的策略,如图2-c所示:对原输入采用stride=2的3x3 avg pool,这样得到和输出一样大小的特征图,然后将得到特征图与输出进行连接(concat),而不是相加。这样做的目的主要是降低计算量与参数大小。
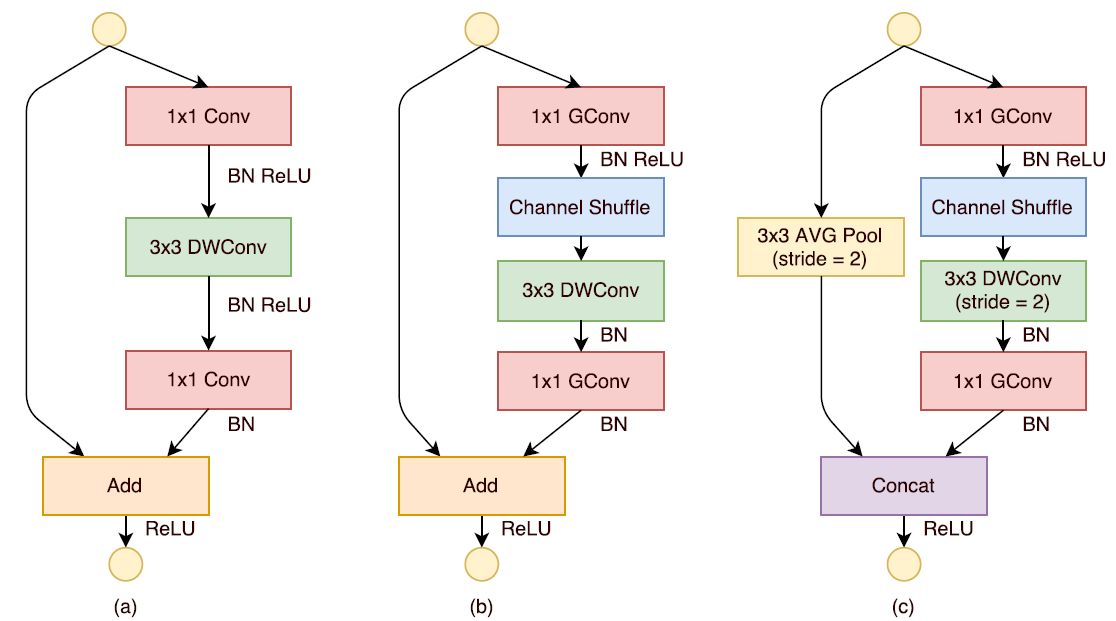
图2 ShuffleNet的基本单元
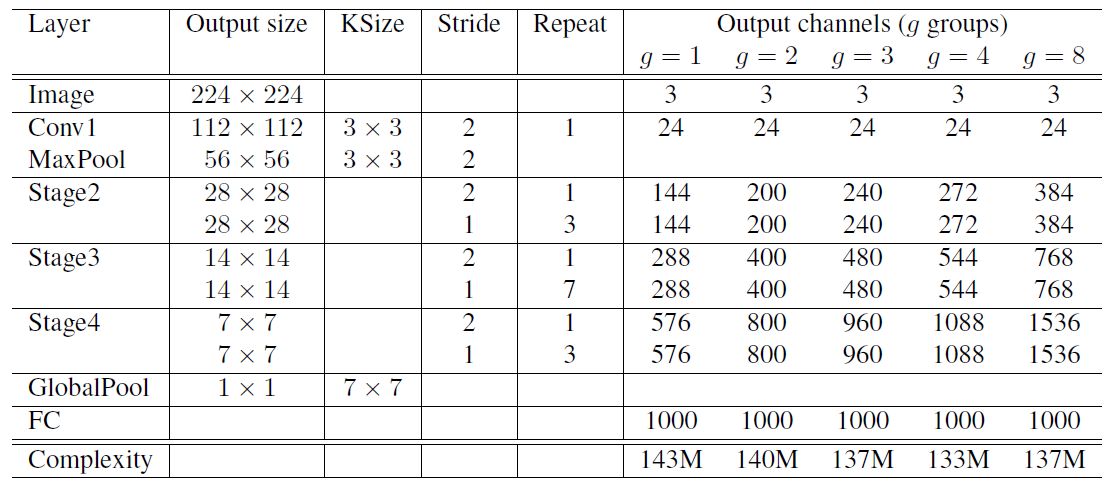
制了group convolution中的分组数,分组越多,在相同计算资源下,可以使用更多的通道数,所以g越大时,采用了更多的卷积核。这里给个例子,当g=3时,对于第一阶段的第一个基本单元,其输入通道数为24,输出通道数为240,但是其stride=2,那么由于原输入通过avg pool可以贡献24个通道,所以相当于左支只需要产生240-24=216通道,中间瓶颈层的通道数就为216/4=54。其他的可以以此类推。当完成三阶段后,采用global pool将特征图大小降为1x1,最后是输出类别预测值的全连接层。
表1 ShuffleNet网络结构
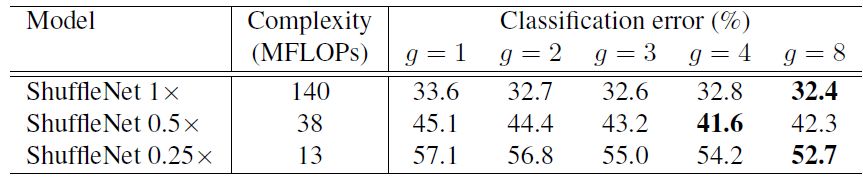
的ShuffleNet在ImageNet上的实验结果。可以看到基本上当g越大时,效果越好,这是因为采用更多的分组后,在相同的计算约束下可以使用更多的通道数,或者说特征图数量增加,网络的特征提取能力增强,网络性能得到提升。注意Shuffle 1x是基准模型,而0.5x和0.25x表示的是在基准模型上将通道数缩小为原来的0.5和0.25。
表2 采用不同g值的ShuffleNet的分类误差
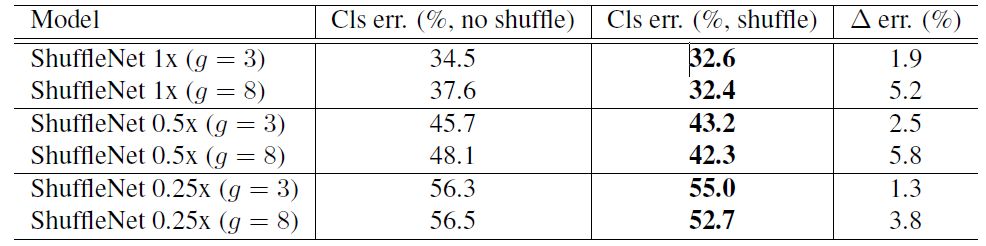
除此之外,作者还对比了不采用channle shuffle和采用之后的网络性能对比,如表3所示。可以清楚的看到,采用channle shuffle之后,网络性能更好,从而证明channle shuffle的有效性。
表3 不采用channle shuffle和采用之后的网络性能对比
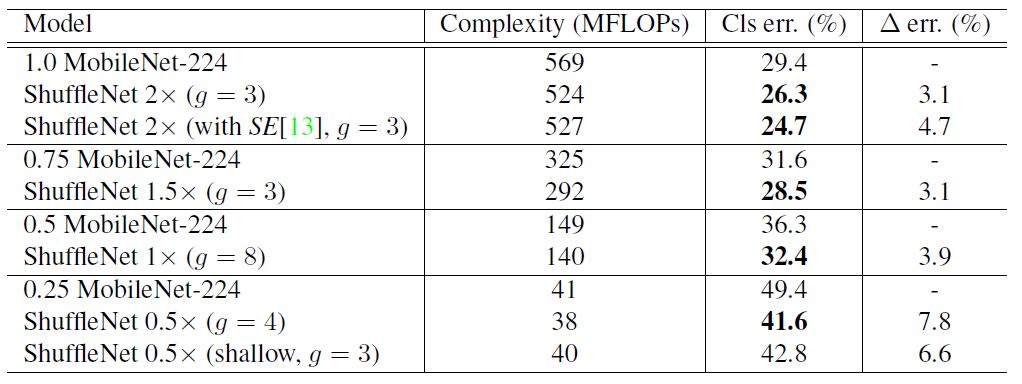
然后是ShuffleNet与MobileNet的对比,如表4所示。可以看到ShuffleNet不仅计算复杂度更低,而且精度更好。
表4 ShuffleNet与MobileNet对比
这里我们使用Pytorch来实现ShuffleNet,Pytorch是Facebook提出的一种深度学习动态框架,之所以采用Pytorch是因为其nn.Conv2d天生支持group convolution,不过尽管TensorFlow不支持直接的group convolution,但是其实可以自己间接地来实现。不过患有懒癌的我还是使用Pytorch吧。
首先我们来实现channle shuffle操作,就按照前面讲述的思路来实现:
def shuffle_channels(x, groups):
"""shuffle channels of a 4-D Tensor"""
batch_size, channels, height, width = x.size()
assert channels % groups == 0
channels_per_group = channels // groups
# split into groups
x = x.view(batch_size, groups, channels_per_group,
height, width)
# transpose 1, 2 axis
x = x.transpose(1, 2).contiguous()
# reshape into orignal
x = x.view(batch_size, channels, height, width)
return x然后我们实现ShuffleNet中stride=1的基本单元:
class ShuffleNetUnitA(nn.Module):
"""ShuffleNet unit for stride=1"""
def __init__(self, in_channels, out_channels, groups=3):
super(ShuffleNetUnitA, self).__init__()
assert in_channels == out_channels
assert out_channels % 4 == 0
bottleneck_channels = out_channels // 4
self.groups = groups
self.group_conv1 = nn.Conv2d(in_channels, bottleneck_channels,
1, groups=groups, stride=1)
self.bn2 = nn.BatchNorm2d(bottleneck_channels)
self.depthwise_conv3 = nn.Conv2d(bottleneck_channels,
bottleneck_channels,3, padding=1, stride=1,
groups=bottleneck_channels)
self.bn4 = nn.BatchNorm2d(bottleneck_channels)
self.group_conv5 = nn.Conv2d(bottleneck_channels, out_channels,
1, stride=1, groups=groups)
self.bn6 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.group_conv1(x)
out = F.relu(self.bn2(out))
out = shuffle_channels(out, groups=self.groups)
out = self.depthwise_conv3(out)
out = self.bn4(out)
out = self.group_conv5(out)
out = self.bn6(out)
out = F.relu(x + out)然后是中stride=2的基本单元:
class ShuffleNetUnitB(nn.Module):
"""ShuffleNet unit for stride=2"""
def __init__(self, in_channels, out_channels, groups=3):
super(ShuffleNetUnitB, self).__init__()
out_channels -= in_channels
assert out_channels % 4 == 0
bottleneck_channels = out_channels // 4
self.groups = groups
self.group_conv1 = nn.Conv2d(in_channels, bottleneck_channels,
1, groups=groups, stride=1)
self.bn2 = nn.BatchNorm2d(bottleneck_channels)
self.depthwise_conv3 = nn.Conv2d(bottleneck_channels,
bottleneck_channels,3, padding=1, stride=2,groups=bottleneck_channels)
self.bn4 = nn.BatchNorm2d(bottleneck_channels)
self.group_conv5 = nn.Conv2d(bottleneck_channels, out_channels,
1, stride=1, groups=groups)
self.bn6 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.group_conv1(x)
out = F.relu(self.bn2(out))
out = shuffle_channels(out, groups=self.groups)
out = self.depthwise_conv3(out)
out = self.bn4(out)
out = self.group_conv5(out)
out = self.bn6(out)
x = F.avg_pool2d(x, 3, stride=2, padding=1)
out = F.relu(torch.cat([x, out], dim=1))
return out最ShuffleNet的实现:
class ShuffleNet(nn.Module):
"""ShuffleNet for groups=3"""
def __init__(self, groups=3, in_channels=3, num_classes=1000):
super(ShuffleNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 24, 3, stride=2, padding=1)
stage2_seq = [ShuffleNetUnitB(24, 240, groups=3)] +
[ShuffleNetUnitA(240, 240, groups=3) for i in range(3)]
self.stage2 = nn.Sequential(*stage2_seq)
stage3_seq = [ShuffleNetUnitB(240, 480, groups=3)] +
[ShuffleNetUnitA(480, 480, groups=3) for i in range(7)]
self.stage3 = nn.Sequential(*stage3_seq)
stage4_seq = [ShuffleNetUnitB(480, 960, groups=3)] +
[ShuffleNetUnitA(960, 960, groups=3) for i in range(3)]
self.stage4 = nn.Sequential(*stage4_seq)
self.fc = nn.Linear(960, num_classes)
def forward(self, x):
net = self.conv1(x)
net = F.max_pool2d(net, 3, stride=2, padding=1)
net = self.stage2(net)
net = self.stage3(net)
net = self.stage4(net)
net = F.avg_pool2d(net, 7)
net = net.view(net.size(0), -1)
net = self.fc(net)
logits = F.softmax(net)
return logits完整实现可以参见GitHub(https://github.com/xiaohu2015/DeepLearning_tutorials/blob/master/CNNs/ShuffleNet.py)。
本文主要介绍了ShuffleNet的核心设计思路以及网络架构,最后使用Pytorch来实现。说点题外话,在之前计算力不足时,CNN模型有时会采用group convolution,而随着计算力的提升,目前大部分的CNN采用dense channle connections,但是现在一些研究又转向了group convolution来提升速度,这有点戏剧化。不过ShuffleNet通过channle shuffle这一个trick解决了group convolution的一个副作用,还是值得称赞的。
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices(https://arxiv.org/pdf/1707.01083.pdf)
机器学习算法全栈工程师
一个用心的公众号


进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助














 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









