







一、实验背景
每年的12月底,由于接近年底,手机通讯会比较频繁,通过登录移动网上营业厅以后大家可以知道自己这一个月的语音详单如何,但是望着密密麻麻的数据,有几个人静得下心去仔细看看每一条通讯记录的详情,所以在这个背景下博主花了点时间写了一个账单分析的脚本代码,当是练练手吧,主要的目的是打印下这个月内通讯排名前三的是哪几个号码。本文提供仅一个简单实例。
二、实验准备
- Python语言
- 移动网上营业厅(浙江)当月语音详单
三、实验过程
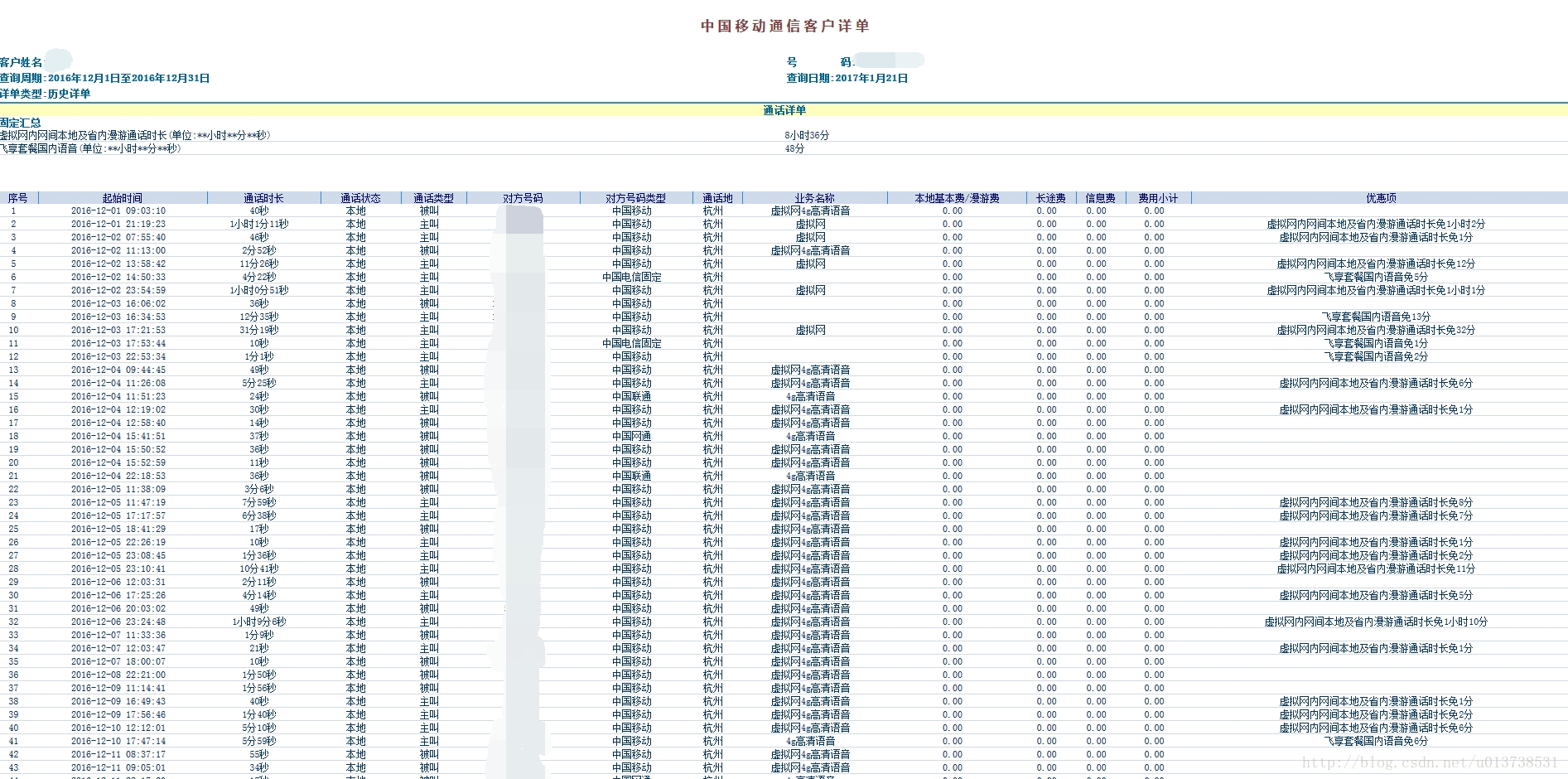
首先是准备数据,也就是当月的移动语音详单,通过登录移动网上营业厅,找到查询业务,下载选定月份的语音详单,这里需要注意一下,博主所在的浙江移动下载下来的详单为html文件,假如大家有人下载的是Excel文件或者csv文件(不知道会不会有这种类型的文件),也可以通过自己动手去实现相关读取功能。废话不多说,移动详单如下所示:
通过Firefox的web控制台查看html的标签信息,确定了需要抓取的内容格式:
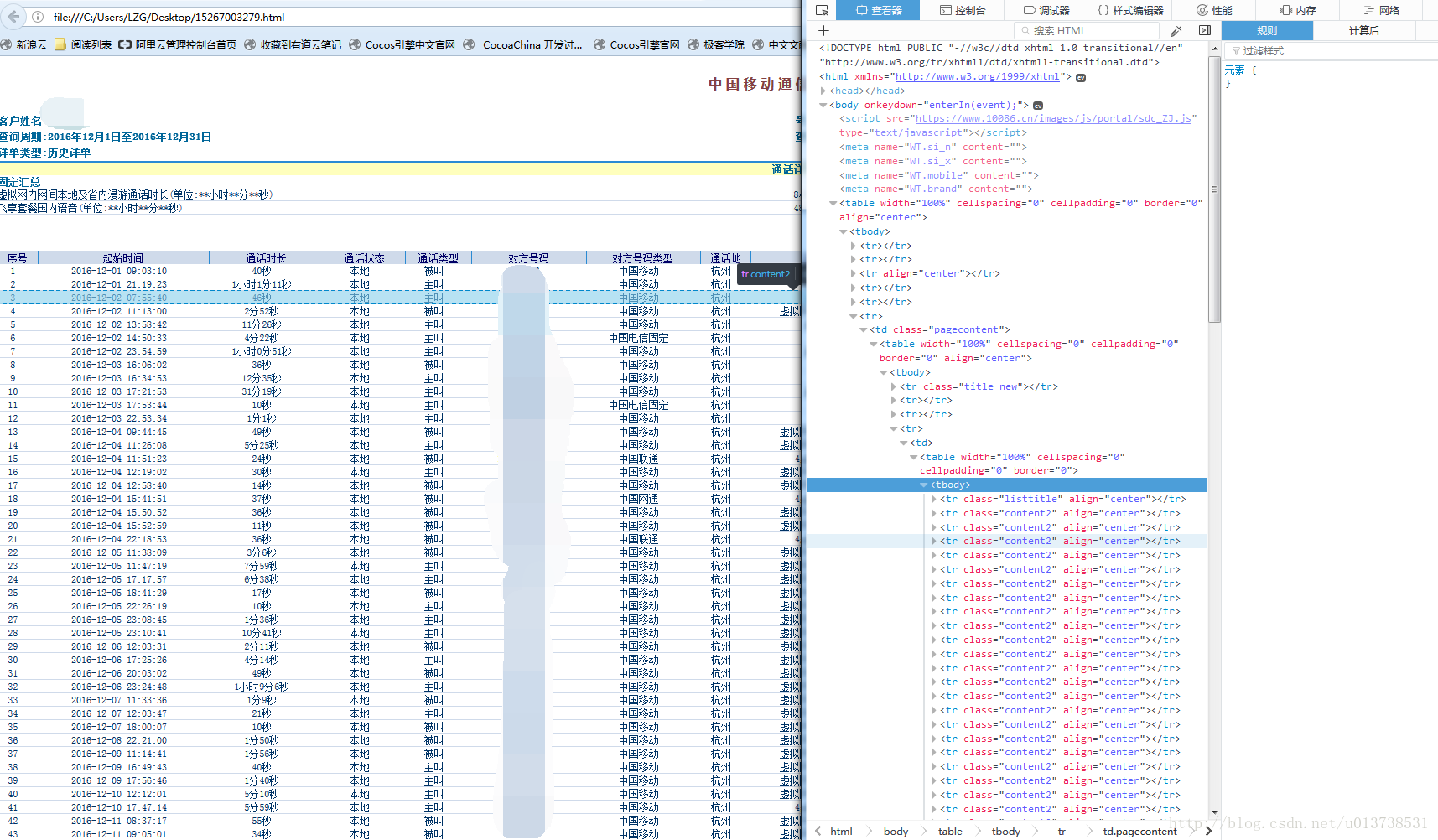
之后通过Python的beautifulsoup模块来对文件内容进行解析和重要数据的提取
Python代码的第一个函数主要是对html文件读取以后解析相关的数据,以电话号码为key构造一个dict对象来存储数据,这里需要提取的是对于指定号码的主叫和被叫时间的记录,所以选择了一个list来保存数据,list对象的第一位存下主叫时间,第二位存下被叫时间,代码一角如下:
#!/usr/bin/python
#coding:utf-8
from bs4 import BeautifulSoup
'''import sys
reload(sys)
sys.setdefaultencoding('utf-8')'''
#解析账单html文件,返回信息dict对象,key为电话号码,value为一个list对象,第一位是主叫时间,第二位是被叫时间
def parseHTML(filename):
soup = BeautifulSoup(open(filename),'lxml')
soup1 = BeautifulSoup("<td>主叫 </td>",'lxml')
tmp = soup1.find_all('td')
flag1 = str(unicode(tmp[0].string))
soup2 = BeautifulSoup('<td>被叫 </td>','lxml')
tmp = soup2.find_all('td')
flag2 = str(unicode(tmp[0].string))
tr_tags = soup.find_all('tr',class_='content2')
infos = dict()
for tr_tag in tr_tags:
info_list = list()
td_tags = tr_tag.find_all('td',class_='talbecontent1')
if len(td_tags) <= 3:
continue
for td_tag in td_tags:
info_list.append(unicode(td_tag.string))
tele = str(info_list[5])
call_type = str(info_list[4])
call_time = info_list[2]
times = spliteTime(call_time)
if tele in infos.keys():
if call_type == flag1:
infos[tele][0] += times
else:
infos[tele][1] += times
else:
time_list = list([0,0])
infos[tele] = time_list
if str(call_type) == flag1:
infos[tele][0] = times
else:
infos[tele][1] = times
return infos
#将字符类型的通话时间转换为秒为单位,返回int对象
def spliteTime(time_str):
hour_list = time_str.split('小时')
hour = 0
minute_string = ''
if len(hour_list) == 1:
minute_string = hour_list[0]
else:
minute_string = hour_list[1]
hour = int(hour_list[0])
#print hour
minute_list = minute_string.split('分')
minute = 0
sec_string = ''
if len(minute_list) == 1:
sec_string = minute_list[0]
else:
sec_string = minute_list[1]
minute = int(minute_list[0])
#print minute
sec_list = sec_string.split('秒')
sec = int(sec_list[0])
#print sec
return hour*3600+minute*60+sec上述为代码一角,本着模块化的精神,本项目将重要的功能已函数形式单独整理,主要有如下几个函数:
- def parseHTML(filename): #解析账单html文件,返回信息dict对象,key为电话号码,value为一个list对象,第一位是主叫时间,第二位是被叫时间
- def spliteTime(time_str): #将字符类型的通话时间转换为秒为单位,返回int对象
- def cmnctTime(num_int): #将int对象的数据转换为string对象,返回string对象
- def sortInfos(infos): #将dict对象排序,排序规则为通话时间的升序
- def getTop3Caller(infos): #返回通话时间最多的前三个号码
四、实验结果
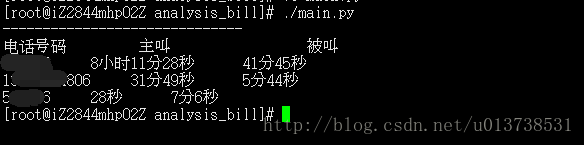
通过执行脚本以后可以看到本月通讯排名前三位的是哪几个号码,这里仅提供一个简单的实例,如果大家有兴趣,可以拿到数据以后做其他方面的分析,最后也可以通过图表形式直观的显示出来,如果有心的话还可以分析每个月的账单,将数据存入自己个人的数据库中,方便以后有需要的时候读取来分析。
博主自己的文件放在github上,地址如下:luuuyi/analysis_bill














 4442
4442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









