







1.什么是git
这个去google一下可以搜出一大堆,git就是一个软件管理器,不同一般的是它是分布式的,不仅有一个中心的服务器控制最新版本代码,而且每个开发者自己还有个本地仓库,所以在开发过程中都是先将代码提交到本地仓库再推送到中心服务器上的,这样的好处就是每个人都依赖于中心服务器来实现交互,但又不会被中心服务器限制,就算中心服务器挂了,也能很容易的找到最新版本的代码,而且我自己的工作依然可以顺利进行,提交到本地仓库,当中心服务器修复之后,再将自己仓库的东西推送到中心服务器。当然它还有很多的不同点,以后再来比较git和svn。
2.自己的git仓库
我们要进行开发,提交代码和中心服务器进行交互,首先我们要有自己的一个开发基地,也就是我们自己的git仓库。拥有自己的git仓库的方式有两种,一就是在自己已有的目录里初始化自己的git仓库然后和中心服务器建立连接,更新最新代码到自己的git仓库。二就是将一个已经存在的项目克隆到自己的目录成为自己的git仓库。
执行git init命令,就会创建并初始化git仓库,这个时候在该目录下会产生一个.git的隐藏文件夹,而该目录就是你的工作目录,你的一切行为都是在这个目录里,而这个.git文件夹就是你的本地仓库,当你进行了一些文件操作之后,认为可以提交了那么首先你就是提交到本地仓库也就是这个.git中,然后再推送到中心服务器。或者直接克隆一个仓库到本地作为git仓库,也是一样的。当你进入到这个.git目录中,会发现里面还有很多的子目录和文件,有的是很重要的,这里说几个,config文件,这是你项目的配置文件,里面有中心服务器的信息和分支信息,HEAD文件指向当前的分支,index文件是暂存区的相关信息,logs目录中都是相关操作产生的日志,这个很重要,因为日志是我们操作的唯一证据,我们本地的版本控制也靠它,objects目录里面存储的就是所有 的数据,也就是快照,refs目录里是存储指向数据提交对象的指针。
乍看之下不知道说的什么,主要是里面的很多名字不知道是什么东西,下面再来看看一些名字概念,分支和提交对象以后再讲这个涉及版本的控制,我们先看最基本的。
3.git的分层结构
刚开始学习git的时候,总是一头雾水,又是什么工作目录,又是什么暂存区,又是什么本地仓库,又是什么远程仓库,还尼玛快照,看的我头晕眼花的。但是只要把这几个概念弄清楚,那么最基本的开发就不是问题了。先来看看我所理解的git的分层结构:
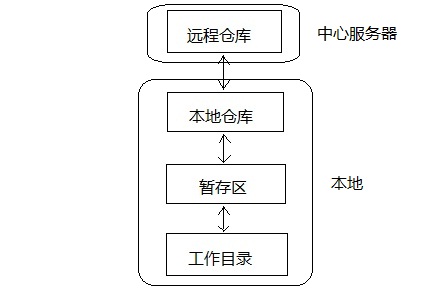
git的工作总共分四层,其中三层是在自己本地也就是前面说的git仓库,包括了工作目录,暂存区和本地仓库,工作目录就是我们执行命令git init时所在的地方,也就是我们执行一切文件操作的地方,暂存区和本地仓库都是在.git目录,因为它们只是用来存数据的。远程仓库在中心服务器,也就是我们做好工作之后推送到远程仓库,或者从远程仓库更新下来最新代码到我们的git仓库。git所存储的都是一系列的文件快照,然后git来跟踪这些文件快照,发现哪个文件快照有变化它就会提示你需要添加到暂存区或是提交到本地仓库来保证你的工作目录是干净的。
这个怎么理解呢,git中的文件有两种状态,一种是被跟踪的,也就是提交到本地仓库的文件,因为本地仓库要保管它们当然得跟踪他们,对它们负责,还有一种就是未被跟踪的。那么当我们添加新的文件时,它不是被跟踪的,因为本地仓库里面没有这个文件,它是外来的,本地仓库目前还不需要对他们负责。但是如果是对仓库已经存在的文件进行修改,那么这些文件就是被跟踪的文件,就可以通过git status查看他们的状态来进行相应的操作。当然我们也可以生成一个.gitignore文件,里面指定要忽略的文件类型,然后这些文件就不会被跟踪,不管怎么改变它们,git status都不会提示你需要做什么操作的。
所以当我们在工作目录中进行文件操作后,要先添加到暂存区,然后再将暂存区中刚添加的文件快照提交到本地仓库,然后再将本地仓库的最新版本文件快照推送到远程仓库。这个文件快照其实就是各个文件的在被添加到暂存区时的状态,就和照相一样的,留下每个不同时刻的快照,方便以后查询,而git存储的就是这些一系列的快照。说到这个快照就要说说git的对象了。
4.git的对象
从根本上讲,git是一套内容寻址的文件系统,它存储的也是key-value键值对,然后根据key值来查找value的,说到寻址就会想到指针吧,不错,git也是根据指针来寻址的,这些指针就存储在git的对象中。git一共有3种对象,commit对象,tree对象和blob对象。下面便是这3个对象:
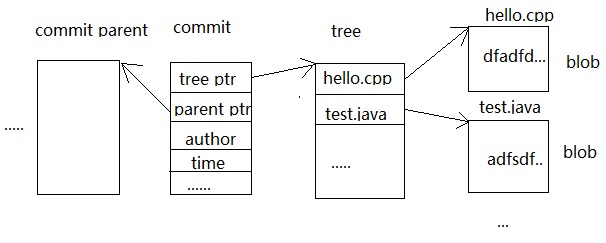
这个blob对象对应的就是文件快照中那些发生变化的文件内容,而tree对象则记录了文件快照中各个目录和文件的结构关系,它指向了被跟踪的快照,commit对象则记录了每次提交到本地仓库的文件快照,从上图看出其中有两个指针,一个指向tree对象,一个则指向上一个commit对象。这个怎么理解呢,怎么还有上一个commit对象,在开发过程中,我们会提交很多次文件快照,那么第一次提交的内容会用一个commit来记录,这个commit没有指针指向上一个commit对象,因为没有上一个commit,它是第一个,当第二次提交时,又会有另外一个commit对象来记录,那么这次commit对象中就会有一个指针指向上一次提交后的commit对象,经过很多次提交后就会有很多的commit对象,它们组成了一个链表,当我们要恢复哪个版本的时候,只要找到这个commit对象就能恢复那个版本的文件不是吗。而我们所谓的HEAD对象其实就指向最近一个提交的commit对象,也就是最后一个commit对象。
5.git的基本操作
上面说了这么多东西,也该看看基本操作了,基本上的操作无非是文件的增删改和版本的提交更新回溯。当把上面的内容弄清楚之后,这些基本操作根本就是小草一碟:
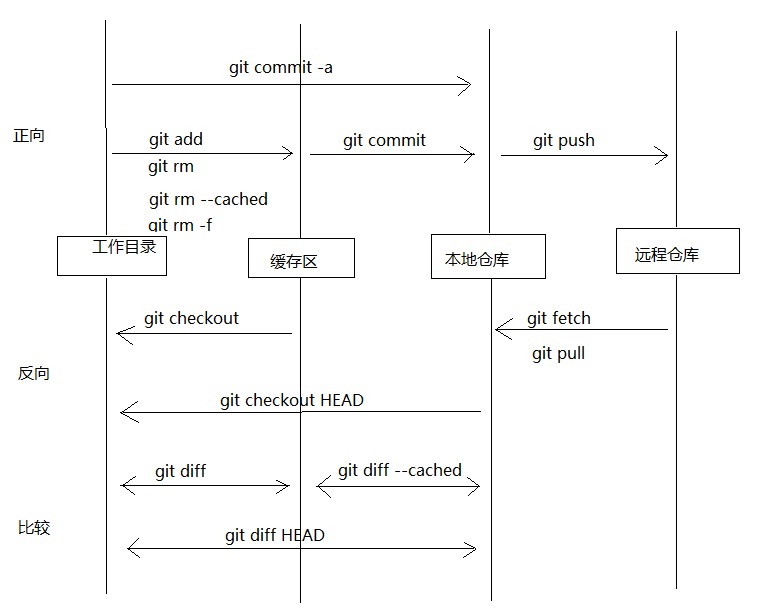
上面列出了基本上能用到的所有命令,当然还没涉及到分支,这个概念后面再说,基本的用法google一下一大堆,这里不用多说,还有就是要经常用到git status这个命令,它可以指引你该干嘛干嘛,确定你的工作目录是否干净。干净的意思就是和暂存区还有本地仓库保持一致。还有一个命令也是经常用到的,那就是git log,这个命令会列出你的操作产生的日志,有很多的信息,还有提交后的commit对象的id,这个checkout版本的时候用处很大。
6.学习感受
以前在用svn的时候,基本两条命令就可以搞定,svn up,svn ci,svn di更新,提交和比较,就知道哦svn up是将服务器的代码更新到本地,哦svn ci是将本地代码提交到服务器,有冲突哦svn di解决冲突了再提交。根本不知道其结构式怎样,这些会导致什么结果,用起来总是小心翼翼,生怕把服务器搞挂了。学习就是要知其所以然,用起来才会顺手,基本原理弄懂之后,操作这些就是相关命令多用用自然搞定。我也是个git初学者。推荐一篇文章,这篇文章很深入的分析了git内部原理,以至于我都没看懂多少,惭愧:http://www.open-open.com/lib/view/open1328070620202.html
1.git的分支是什么
顾名思义,分支就是从主线上分离出来进行另外的操作,而又不影响主线,主线又可以继续干它的事,是不是有点像线程,最后分支做完事后合并到主线上而分支的任务完成可以删掉了。这样是不是很方便,主线继续做它的事,分支用来解决临时需求,二者互不相干。
git的分支功能特别的强大,它不需要将所有数据进行复制,只要重新创建一个分支的指针指向你需要从哪里开始创建分支的提交对象(commit),然后进行修改再提交,那么新分支的指针就会指向你最新提交的这个commit对象,而原来分支的指针则指向你原来开发的位置,当你在哪个分支开发,HEAD就指向那个分支的最新提交对象commt。没弄清楚没关系,先有这么一个概念,后面慢慢就会弄清的。
2.分支的新建与合并
我们可以用命令git branch来查看我们的git仓库有几个分支,而我们目前工作处于那个分支,前面有个*号的就为我们目前所处的分支。我们可以通过命令git branch name来创建分支,而这个分支的指针就指向最新的commit对象,也就和HEAD指向同一对象。我们可以通过命令git checkout name来切换到目的分支,我们默认的主分支为master。在分支的创建和切换,其实只是简单的创建指针找指针而已,而根据找到的指针找到所指向的commit对象,然后将工作空间恢复成该commit对象所指的文件快照让我们来工作。当提交一次,指针就重新指向这个最新提交的对象,特别的简单。
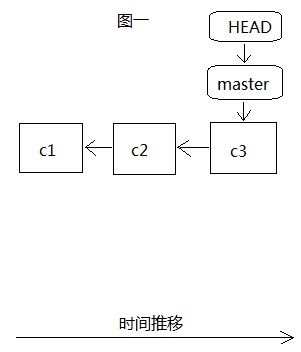
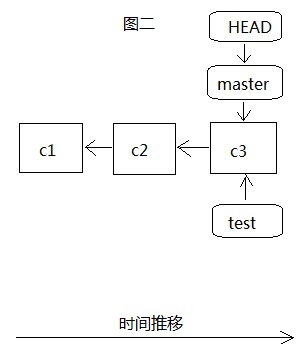
当我们建立分支teset之前,只有master一个主分支,如图一,我们所有的开发都是在这个分支上,而且HEAD是指向最近一次提交的commit对象c3,c3以前还有两次提交c1和c2,这时我们通过git branch test创建test分支,如图二,这时HEAD还是指向master分支最近一次提交的c3,当git checkout test切换到test分支后,HEAD就指向test分支的最近一次提交c3,这个时候其实在.git里面都是指向同样一份数据c3。
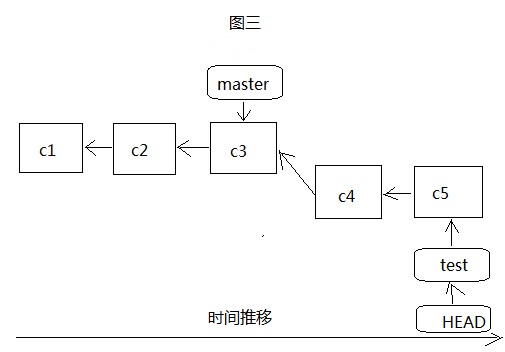
这个时候,当我们在test分支上进行了几次开发提交了c4和c5两个版本后,那么test和HEAD都指向test分支的最近一次提交c5,如图三,而master此时还没有变化,任然指向的是c3,如果这个时候将test分支合并到master分支,那么git根本不用做什么,只要将master移动,指向c5就可以了,这个过程称之为Fast-forward快进。如果此时test的任务完成,我们就可以通过git branch -d test将它删除掉,继续在主分支master上进行开发。如果是这样的话,那么test分支就白建了。
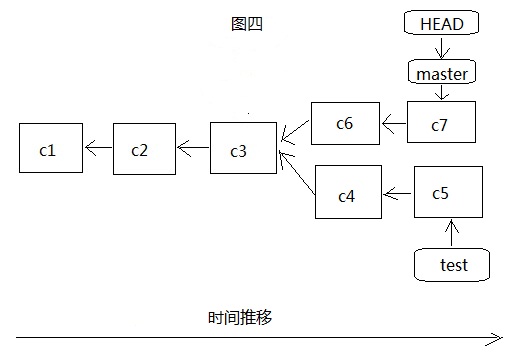
那么如果此时master分支上又进行另外的开发,提交了两个版本c6和c7,那么此时的master和HEAD指针都指向的是c7,如图四,可以看出在哪个分支上开发,那么HEAD就指向的是哪个分支上的commit,这个时候合并两个分支的话,就如下。
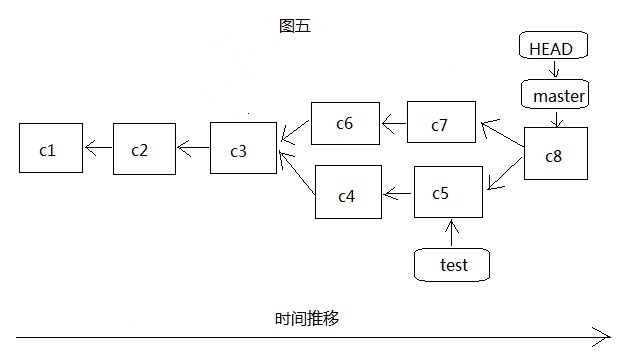
如图五,我们先切换到master分支,然后通过git merge test将test分支合并到master分支,这个时候,git就不是简单的移动指针了,因为两边都有开发,所以git就要对于两个分支的最新提交c5和c7还有两个分支共同的祖先commit对象c3来进行一次简单的三方合并,产生新的文件快照并用新的commit对象c8记录,这个合并的过程不需要太在意,如果产生了冲突,也就是两个分支对同一个文件进行了修改,那么git就会停下合并操作,让你处理好冲突后,再提交(c8),然后再进行合并。这时master和HEAD都指向c8,但是test是没有移动的,此时还可以在test上继续开发,再合并到master,如果test已经没有利用价值了就可以删掉了。
3.本地分支,追踪分支和远程分支
这里有三个概念,本地分支就是我们可以通过git branch查看到的分支,也就是我们自己git仓库所拥有的分支,我们都可以利用。远程分支是对远程仓库的分支的索引,它其实也是本地分支,只是我们无法移动它,必须要在和中心服务器交互根据服务器更新到本地来的代码移动的,远程分支的作用就是我们上次和中心服务器交互更新得到的最新版本,它也是个指针。追踪分支比较难理解,它也是一个本地分支,只是它对应了一个远程分支,如果我们本地的某个分支对应了一个特定的远程分支,那么它就是追踪分支,比如我们最初的master分支就是一个追踪分支,它对应远程分支origin/master,这里origin是远程仓库名,当我们在master分支里执行更新(fetch,pull)或是推送(push),在不指定分支的情况下,默认就是从origin/master分支更新来或者提交到origin/mster分支。
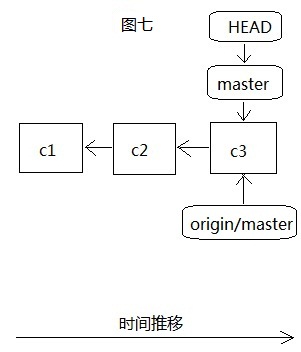
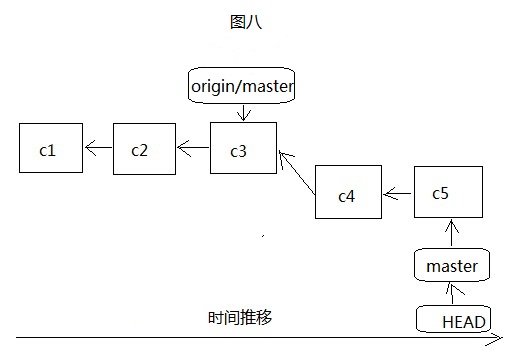
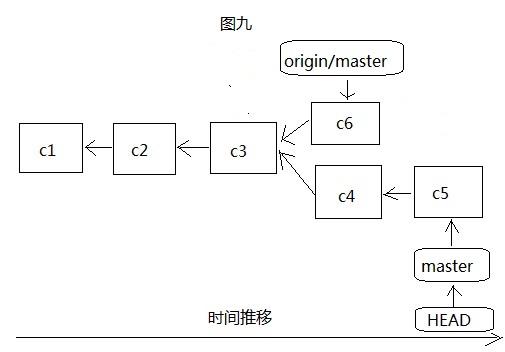
从图七和图八很容易看出来,和我们本地创建分支很相似,只是origin/master远程分支只有在连接服务器并更新服务器代码到本地后才会移动,如下图九:
更新远程代码到本地有两个命令,fetch和pull,fetch是将远程代码更新到本地,但是不会执行合并操作,需要自己查看,解决冲突什么的,然后自己再执行merge将更新来的代码合并到我们自己制定的分支,但是pull就将这两个操作合成了一步,直接更新服务器代码更新并合并到到本地指定分支,当然遇到冲突也必须要自己解决。所以我们一般都使用fetch来实现更新,虽然麻烦了点,但是不容易出问题。
将本地代码推送到远程仓库,也就是中心服务器,一般我们推送数据都是git push origin master:master,这里指定远程仓库名,本地分支名和远端分支,也就是将我们本地master分支的数据推送到远程仓库origin的master分支。如果本地的master分支是追踪分支,那么在不指定的情况下,它会自己找到远程仓库中对应的分支来推送数据。或者我们直接进行git push origin操作,只指定远程仓库名,那么git会根据我们目前所在分支和它所对应的远程仓库的分支来实现数据推送,前提是我们目前所在分支必须是追踪分支。当然如果是git push origin :master,这里本地分支名是空的,这个操作就是将空分支推送到远程仓库的master分支,结果就是将master分支删除。
既然追踪分支这么好用,那么我们怎么建立追踪分支呢,有两种方式,第一种方式是根绝远程分支创建追踪分支,如果不指定该追踪分支的名字,默认和远程仓库的分支名字一样:git checkout --track origin/test,这样我们就建立了一个名为test的追踪分支,如果重新指定追踪分支的名字:git checkout -b name origin/test,这样我们就创建了一个名为name的追踪分支,它对应远程仓库的test分支。第二种方式是已经存在某个本地分支,要让它来对应某个远程分支来成为追踪分支,也有两个命令可以用,git branch --set-upstream test origin/test 或者git branch -f --track test origin/test 这里我们就让我们本地已经存在的test分支来追踪远程的test分支。
4.git分支管理
git创建分支于合并分支是如此简单快捷,那么在我们的开发过程中可以疯狂的使用分支,而且git的核心玩法之一就是分支,非常提倡使用分支,但是是不是我们可以肆无忌惮的使用分支呢,创建这么多的分支我们要如何来管理呢,分支不在多而在恰到好处,如果分支创建多了,管理起来就麻烦了,所以推荐一种分支的管理策略,git-flow,同时推荐一篇文章来了解这种策略:http://nvie.com/posts/a-successful-git-branching-model/,让你的git使用更加顺手。
1.merge
在上篇介绍分支的时候有简单的说了一下分支的创建和合并,当时合并就是写的merge,这是根据两个不同分支的最后一次提交的commit对象c5,c7和两个分支的交叉点的commit对象c3进行一次简单的三方合并,最终得到一个新的commit来作为最终的提交commit对象c8,指针指向c8,而且c4,c5,c6,c7是存在于本地仓库的历史版本,我们可以通过日志查看找到这两个commit,同样也可以恢复到这两个版本。也就是下面这个图:
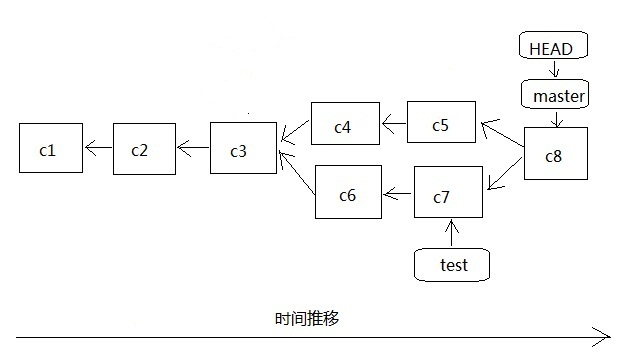
上图是将test分支合并到master分支,然后我们来实现一次,假如现在已经到了c3,我新建一个分支test,然后先用master分支修改我的test.txt文件并提交重复两次,得到c4和c5,然后再切换到test分支同样对test.txt修改并提交两次,得到c6和c7,然后切换到master分支执行合并操作,这时会提示有冲突,最后我们解决冲突了再提交:
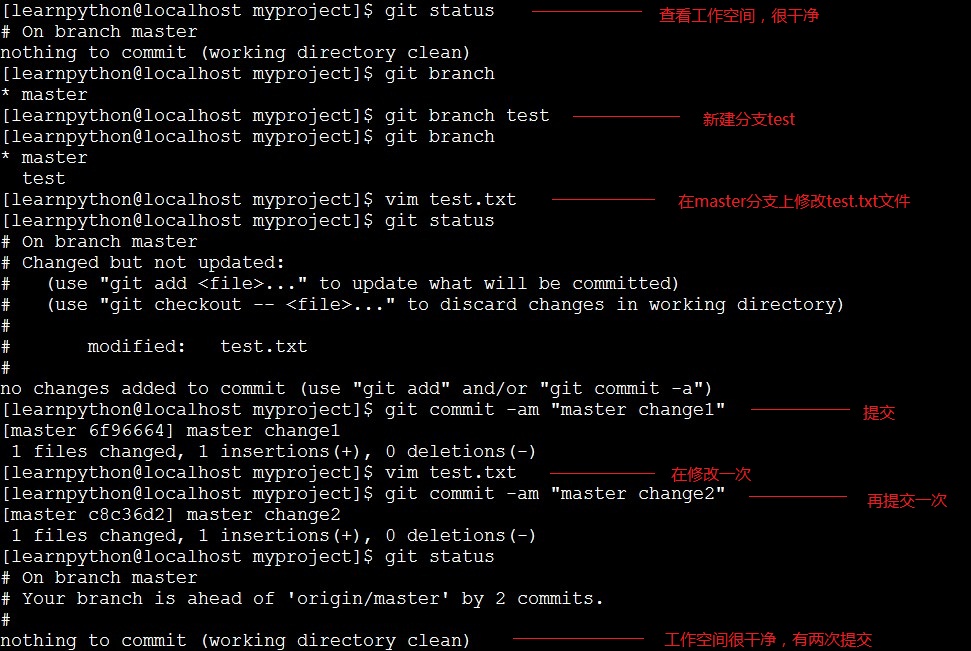
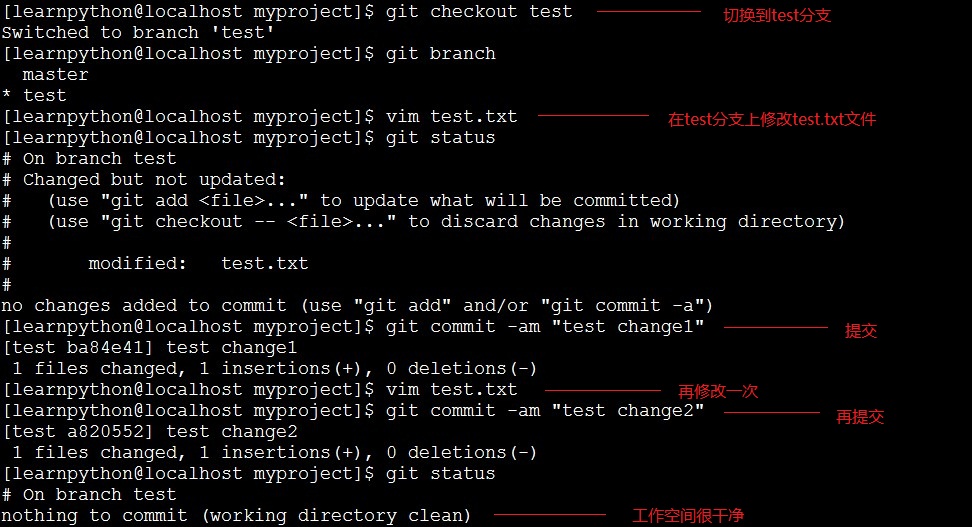
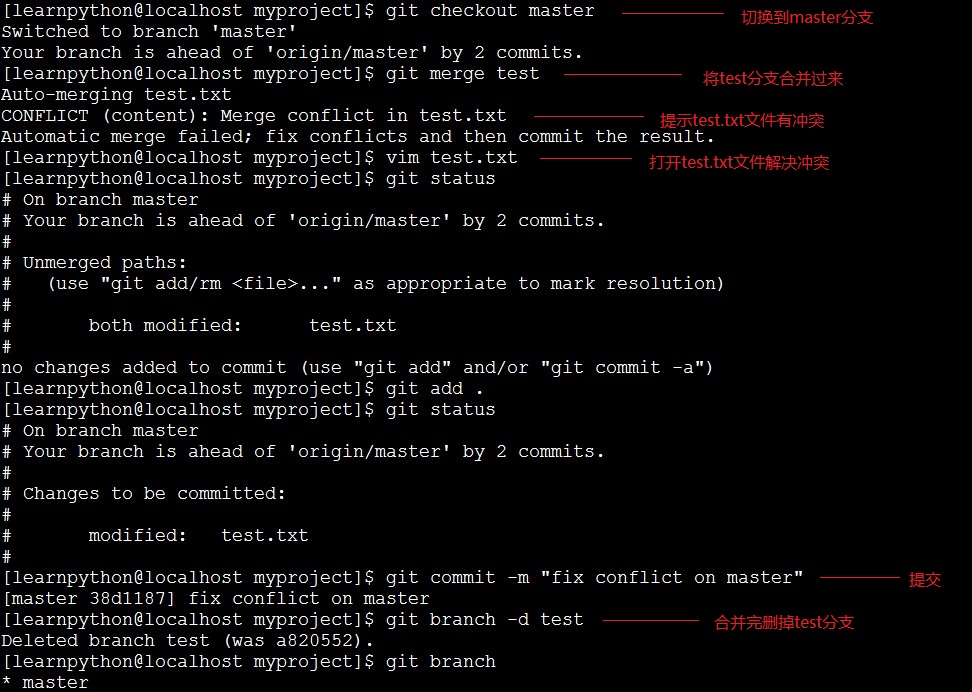
冲突:

日志:
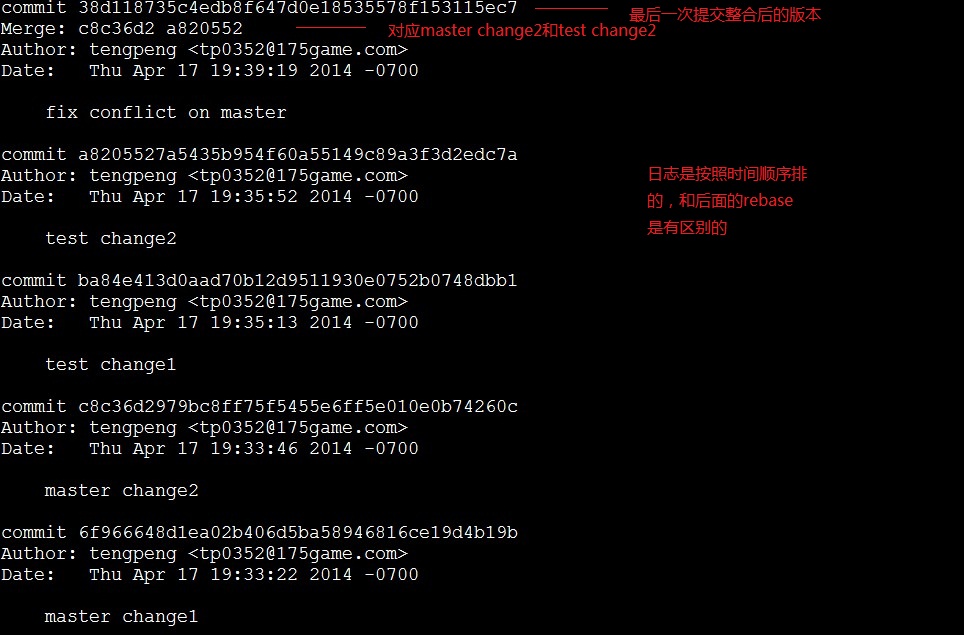
2.rebase
rebase称为衍合,这是个什么概念呢,如下图,当我们把test衍合到master的时候,是将c5,和c6中发生的变化打成补丁然后再c8的基础上做修改的,如果这个时候遇到冲突,就必须要我们自己决绝好冲突之后,添加到暂存区然后再继续合并,c5的变化补丁在c8上发生变化之后得到c5'这个commit对象,而c6的变化补丁再在c5'上修改得到c6',然后指针指向c6',这个过程我们称之为衍合,而且这个过程都是在一个*(no branch)分支上做的,这个后面会说到。而且有一个要注意的地方,如果git执行git gc或者我们手动执行git gc,那么c5和c6就不再存在于我们的本地仓库,我们就再也找不回这两个commit了,这个过程就是一个线性的过程,在test执行完之后,再在test的基础上执行master的操作。以上就是rebase和merge的区别所在。
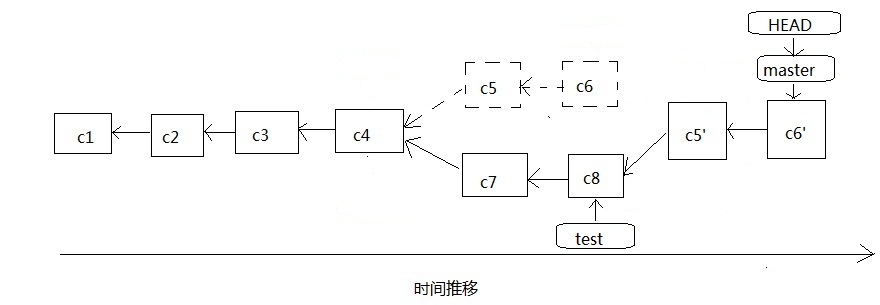
和merge一样,我们实际来做一次,假设现在我们已经在c4了,这时候创建test分支,所有修改操作和merge一样,然后我们用rebase这种方式来把test衍合到master上:
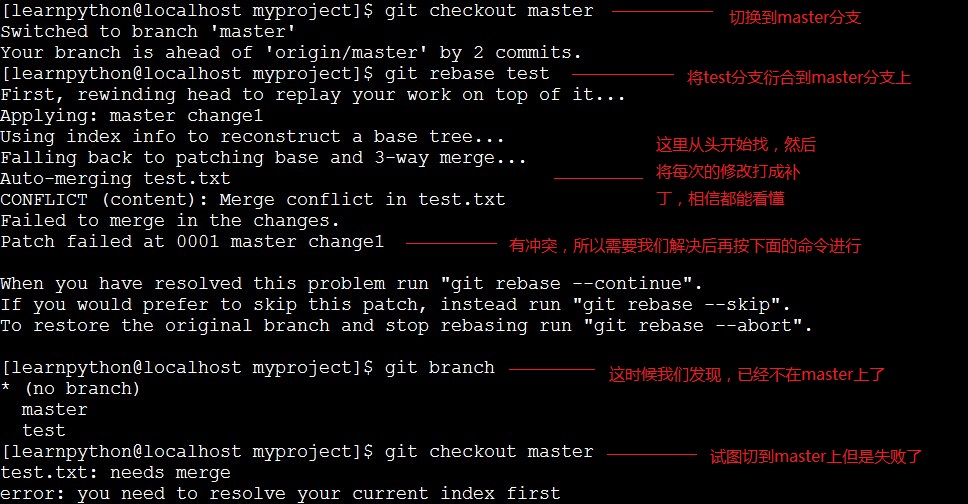
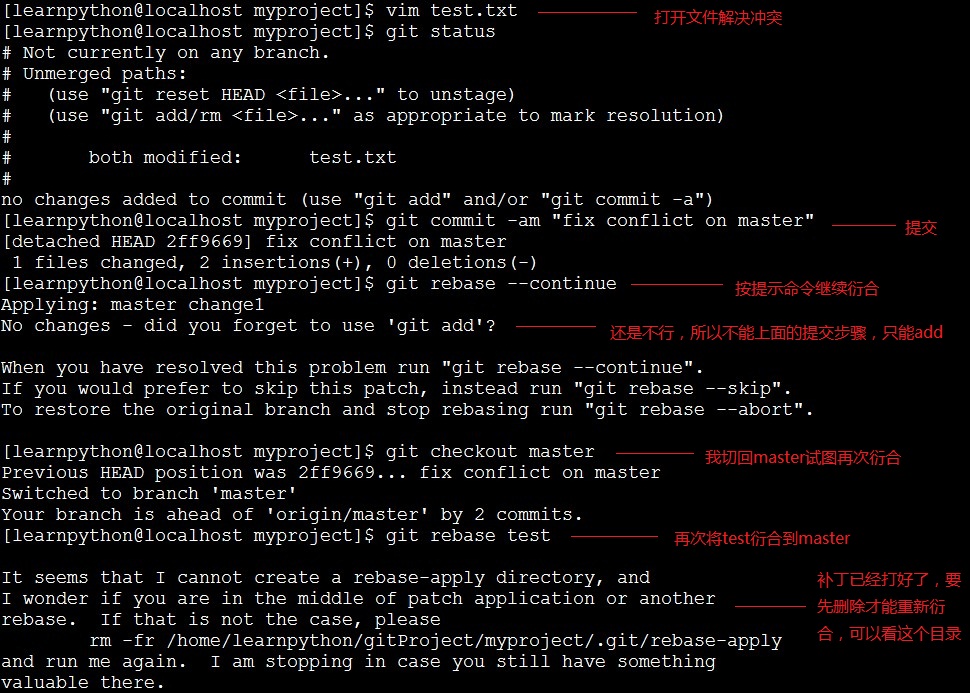
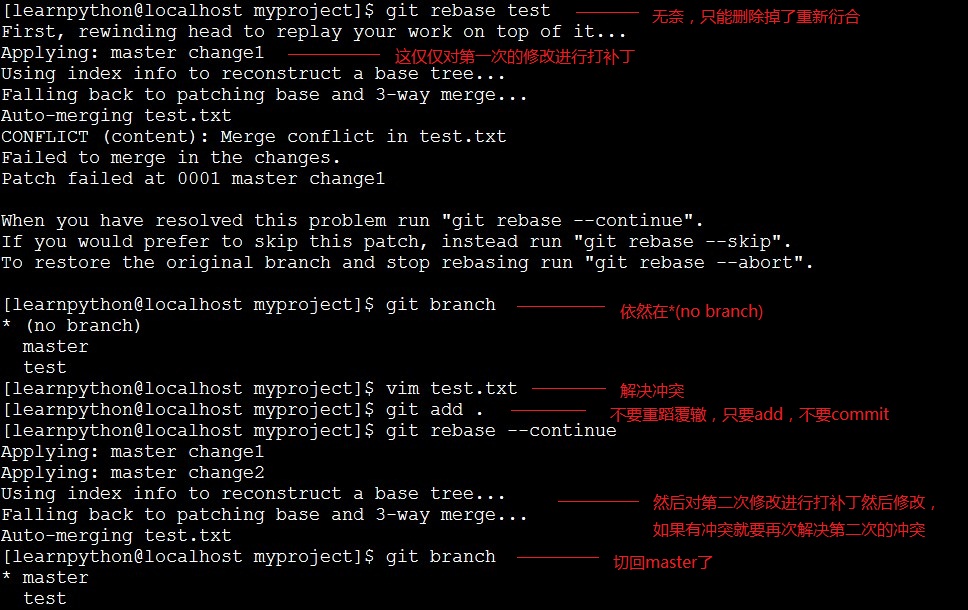
冲突:

日志:
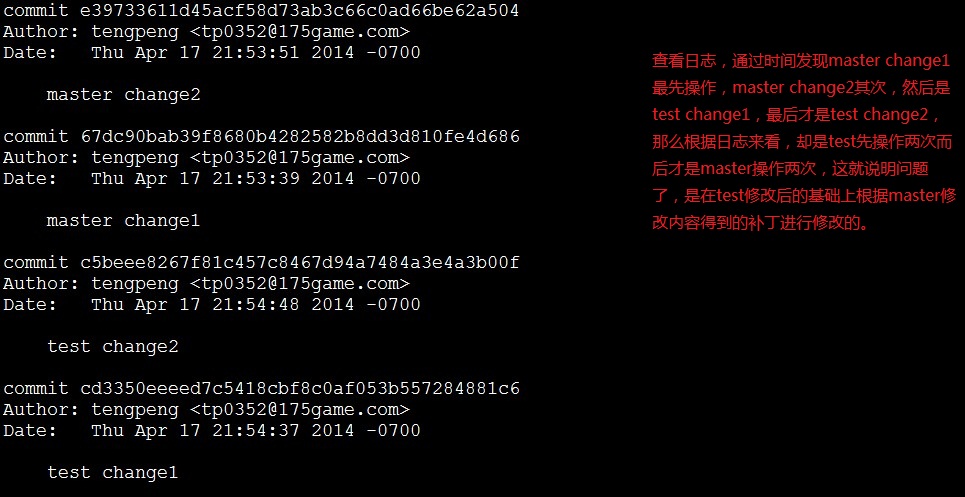
3.*(no branch)
在执行命令git branch查看分支的时候,如果出现*(no branch),则表示不在任何分支上进行工作。出现这种情况我也是在几次不经意之间,用git checkou回溯版本的时候,用git pull或者merge和rebase的时候会出现*(no branch)。目前我在rebase的时候都是在*(no branch)上进行的,当衍合完成后自动切到master上,我觉得这是个正常现象,但是其他几种方式就不正常了,具体原因我也不是很清楚。
由于*(no branch)表示不在任何分支上进行,而有时我们不知道自己是在*(no branch)上进行操作的,而且可能我们已经进行很久的开发工作了,已经提交好几个版本的代码了,突然执行git branch发现在*(no branch)上,是不是一件很恐怖的事啊。
当然经过提交的版本数据都会以快照的方式被记录在commit对象存在.git目录的objects子目录里,那么当我们发现是在*(no branch)时应该怎么解决呢。有两种情况。
第一种情况是我们还没离开*(no branch),这个时候,我们可以执行git checkout -b mybranch命令,这个时候会创建新分支mybranch,并将*(no branch)里面的数据都checkout到mybranch分支上,然后我们再在mybranch上开发,最终合并到master上。
第二种情况就不乐观了,我们已经离开*(no branch)了,然后发现用git log都找不到之前的提交了,当然了,在*(no branch)上提交的,在别的分支上怎么找的到在它上面提交的数据呢。不过也许还有救,如果git还没有执行git gc,那么我们可以通过执行git reflog找到在*(no branch)上提交的数据,然后根据找到的commit的id来恢复该数据,这也是最后唯一的希望了,如果git已经执行了git gc或者你手贱自己执行了git gc,那么就真的不能在一起愉快的玩耍了。
所以在执行过git checkout恢复过以前的数据或者是做过合并分支的操作,那么不要吝啬你们的git branch,敲这个命令又不要钱,却能让你之后的提交高枕无忧。
4.总结
merge的合并是三方合并,而且历史版本都在本地方库中,但是却比较繁琐,而且开发的过程是个网状结构,如果创建的分支比较多,进行的merge也比较多,那么就算我们在纸上画它的提交历史都会画的手疼,但是rebase就不一样,它是根据另外一个分支的修改内容进行打补丁然后在前一个分支的最后提交上进行修改,而且将另外一个分支的提交历史删除,这样就是一个线性的过程,很清晰。所以在推送到远程仓库之前尽量多用rebase来衍合分支,但是如果将一个commit推送到远程仓库之后,就不要再对它进行衍合操作了,因为这样的话,它很可能在你的某次衍合过程中被删除,那么再推送到远程仓库就会造成很大的损失。切记,rebase虽好可不要贪杯。















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









