







环境:Win8.1 TensorFlow1.0.1
软件:Anaconda3 (集成Python3及开发环境)
TensorFlow安装:pip install tensorflow (CPU版) pip install tensorflow-gpu (GPU版)
参考:《Tensorflow:实战Google深度学习框架》
1. 前言
在实验室的购书报销活动中,选择了市面上为数不多的 TensorFlow 书籍,一方面是想借助书籍介绍系统地了解深度学习及 TensorFlow 的使用,另一方面参考了知乎和亚马逊上对这几本中文教程的评价,最终选择了才云科技的这本《Tensorflow:实战Google深度学习框架》。以下选取的两个网友点评:
只买了《Tensorflow:实战 Google 深度学习框架》这本,另一本(黄文坚《TensorFlow实战》)没买,个人感觉虽然是国内作者写的,但是相比国内 caffe 书都是水文,这本不仅是良心,讲的内容也不是随便抄抄改改的,是作者自己的心得和理解加上易懂的语言,有些知识点(比如 softmax 的原理公式)我花了好几个小时在网上看懂的知识,在书中介绍十分易懂,可惜是没早点出来这本书,我就可以少走很多路。所以我从初学者和刚入门深度学习有过 caffe 经验的人来看这本书,觉得这是一本内容偏向研发者和初学者的一本书。
(1) 书写风格是读者友好型的:Pyphon 代码完整,注释详尽;章节之间的逻辑关系交代得清楚。
(2) 阅读重点是第6章“卷积神经网络”和第8章”循环神经网络”的内容;第7章“图像数据处理”和深度学习没有直接联系。
(3) 阅读中发现两处瑕疵:1) 第2页,“整理为了…” 应该是“整理成了…”,或“整理为…” 2) 第43页,第一次出现名词”NumPy”未交代含义,实际上它是一个 Pyphon 科学计算工具包。
(4) 本书有一点“私心”,最后部分介绍了作者所在创业公司的私货“CaiCloud”,以运行分布式TensorFlow。可以理解...
(5) 注意到,同一个出版社,在同一时间,以同样的价格,出版了主题相同的另一本书,即黄文坚等的《TensorFlow 实战》。比较了这两本书,感觉黄文坚的书在深度学习原理的介绍方面更加深入,涉及面也更广(还包括自动编码器,Word2Vec,深度强化学习);但郑泽宇的这本书对卷积神经网络和循环神经网络原理的介绍更为清晰,编程实践也更为扎实。
本人用两天的空闲时间阅读了此书的前四章:
- 第一章为深度学习简介,作者介绍了人工智能、机器学习与深度学习的概念,着重解析了它们之间的关系,最后介绍深度学习在四个不同方向上的应用,并引出了 TensorFlow 这一开源计算框架,这一部分为作为机器学习背景知识,适合初学者加深对深度学习兴起的理解;
- 第二章介绍了 TensorFlow 两个主要的依赖包:Protocaol Buffer 和 Bazel,和不同的安装方式,并通过简单实例给出了一个直观认识;
- 第三章介绍了 TensorFlow 的基本概念(计算图、张量和会话),建立简单的神经网络训练解析前向传播框架和反向传播优化的过程;
- 第四章介绍了深层神经网络中的几个重要部分,如激活函数、损失函数、梯度下降、正则化、滑动均值模型,利用这些方法训练更深层的网络结构。
总的来说,前四章对于入门深度学习和 TensorFlow 的初学者有很大的帮助。
2. 笔记
在阅读第四章内容和实现代码时,有不少方法在之前的 TensorFlow 博文中使用过,但作者一些介绍能帮助有更好的理解。
2.1 激活函数(Activation Function)
激活函数实现了模型的去线性化,避免了线性模型的局限性(多层模型等价单层模型),在 TensorFlow 中常用的有 tf.nn.relu、tf.sigmoid、tf.tanh,在之前的模型中我们使用过 ReLu 激活函数,同时也是 AlexNet 中的重要贡献,相比其他两个 Sigmoid 函数和 Tanh 函数,这里我们作出比较:
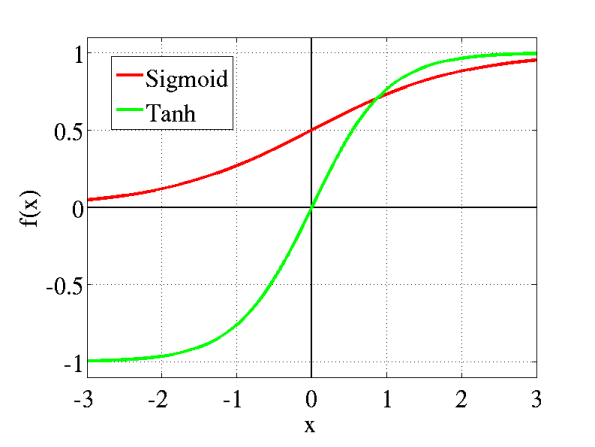
Sigmoid 非线性激活函数的形式是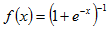
- Sigmoids saturate and kill gradients. Sigmoid 容易饱和,并且当输入非常大或者非常小的时候,神经元的梯度就接近于0了,从图中可以看出梯度的趋势。这就使得我们在反向传播算法中反向传播接近于0的梯度,导致最终权重基本没什么更新,我们就无法递归地学习到输入数据。另外,尤其注意参数的初始值来尽量避免饱和的情况,当初始值很大的话,大部分神经元可能都会处在饱和状态而出现梯度消失,这会导致网络变的很难学习。
- Sigmoid outputs are not zero-centered. Sigmoid 的输出不是0均值的,这是我们不希望的,因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正(e.g. x>0 elementwise in f=wTx+b),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。
Tanh 形式为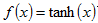
ReLu 的数学表达式为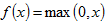
- Krizhevsky et al. 发现使用 ReLu 得到的 SGD 的收敛速度会比 Sigmoid/Tanh 快很多,由于非饱和特性;
- 相比于 Sigmoid/Tanh需要计算指数等,计算复杂度高,ReLu 只需要一个阈值就可以得到激活值;
- ReLu 在训练的时候很”脆弱“,一不小心有可能导致神经元”坏死”,例如 ReLu 在x<0时梯度为0,这样就导致负的梯度在这个 ReLu 被置零,而且这个神经元有可能再也不会被任何数据激活。实际操作中,当 learning rate 很大,网络中的绝大部分神经元将会坏死。当设置一个合适的 lr 时,ReLu 为网络引入了大量的特征稀疏性,加速了复杂特征解离。
2.2 损失函数(Loss Function)
作者介绍了交叉熵(Cross entropy)与均方误差(MSE,mean squared error)及自定义损失函数。其中交叉熵为常用的损失函数,回忆之前利用交叉熵计算 loss 的方法:
cross_entropy = tf.reduce_sum(-y_*tf.log(y_conv)) 此处 y_conv 是通过 tf.nn.softmax 后的 logits 值(属于每个类别的概率值),shape 为 [batch_size, num_classes],每个样本的 logit 向量元素和为1;y_ 是onehot encoding 后的 labels 值,shape 为 [batch_size, num_classes],每个样本的 label 元素中只有一个为1,其余为0。
TensorFlow 在后面的版本中,提供了更加便捷的 API,合并了 softmax 和 cross entropy 的计算:
cross_entropy_loss = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv) cross_entropy_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels, name='xentropy') 此外在我们之前的实例中还有 噪声比对损失(nce_loss),详见上一篇 Word2Vec 的实现。
BP 和 GD 使得神经网络的所有参数根据定义好的损失函数能高效地优化取值,需要注意的是 只有当损失函数为凸函数的时候,梯度下降算法才能保证达到全局最优解。除了不一定能达到全局最优值外,GD 的另一个问题是 计算时间太长,因为损失函数定义在所有训练数据上。为了加速训练过程,可以使用 随机梯度下降(SGD,stochastic gradient descent),在每一轮迭代中随机优化每一条数据上的损失函数,但有可能得到的神经网络甚至无法达到局部最优。为了综合梯度下降和随机梯度下降的优缺点,TensorFlow 每次计算一小部分训练数据的损失函数,称为一个 batch,大大减少收敛需要的迭代次数,且优化了计算量,在实际的使用中,我们通常定义一个 batch_size 的样本用于一次迭代训练。
2.4 正则化(Regularization)
在之前的 CIFAR-10 的实例中,我们将卷积层的 W 通过 tf.nn.l2_loss 进行正则化并通过 tf.add_to_collection 加入最终的模型损失中:
weight_decay = tf.multiply(tf.nn.l2_loss(var), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)
正则化的思想是在损失函数中加入刻画模型复杂程度的指标,通常有 L1正则化和 L2正则化,L1正则化会让参数变得更加稀疏,即更加的参数变为0,达到类似特征选取的功能,而 L2正则化的不会让参数变得稀疏同时能限制权重的大小,且公式可导便于损失函数的求导。
2.5 滑动均值(Moving Average)
在测试数据上要使模型更加鲁棒的方法可以采用滑动平均模型,在采用随机梯度下降算法训练神经网络时,维护训练参数的滑动均值是有好处的,在测试过程中使用滑动参数比最终训练的参数值本身,会提高模型的实际性能即准确率。apply() 方法会添加 trained variables 的 影子变量(shadow copies),average() 方法可以访问 shadow variables,在创建 evaluation model 时非常有用。滑动均值是通过指数衰减计算得到的,shadow variable 的初始化值和 trained variables 相同,其更新公式为 shadow_variable = decay * shadow_variable + (1 - decay) * variable,decay 为定义的衰减率,控制模型更新的速度。
3. 总结
通过前四章的阅读,可以了解到 TensorFlow 下深度学习的基本组成:
- 激活函数和多层网络组成的深层网络结构;
- 网络的优化目标——损失函数;
- 使用 batch 的随机梯度下降算法;
- 指数衰减学习率加速训练,稳定损失函数收敛;
- 正则化解决过拟合问题;
- 滑动平均模型让最后的模型在其他测试数据上更加鲁棒。














 6481
6481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









