







一、无心之谈
项目需要,需要使用Oracle NoSQL数据库,才开始了Oracle NoSQL摸索之旅。
Oracle NoSQL很年轻,目前才更新到3.2.5版本,其功能尚不完全,官方帮助文档简略,尤其是开发API的文档。使得博主在项目进行中尝尝遇到很多问题,又不能很方便的找到解决方案。所以,这些都促使我每次有点收获的时候总想记下来,一方面可以供自己以后学习,另一方面可以供后来人参考.
目前,使用Oracle NoSQL遇到不明白的地方,最好的求助方法就是去官网论坛上发帖,Oracle NoSQL内部人士会热心详细解答,官方论坛
二、一点点心得
1)multiGet() method

2)索引问题
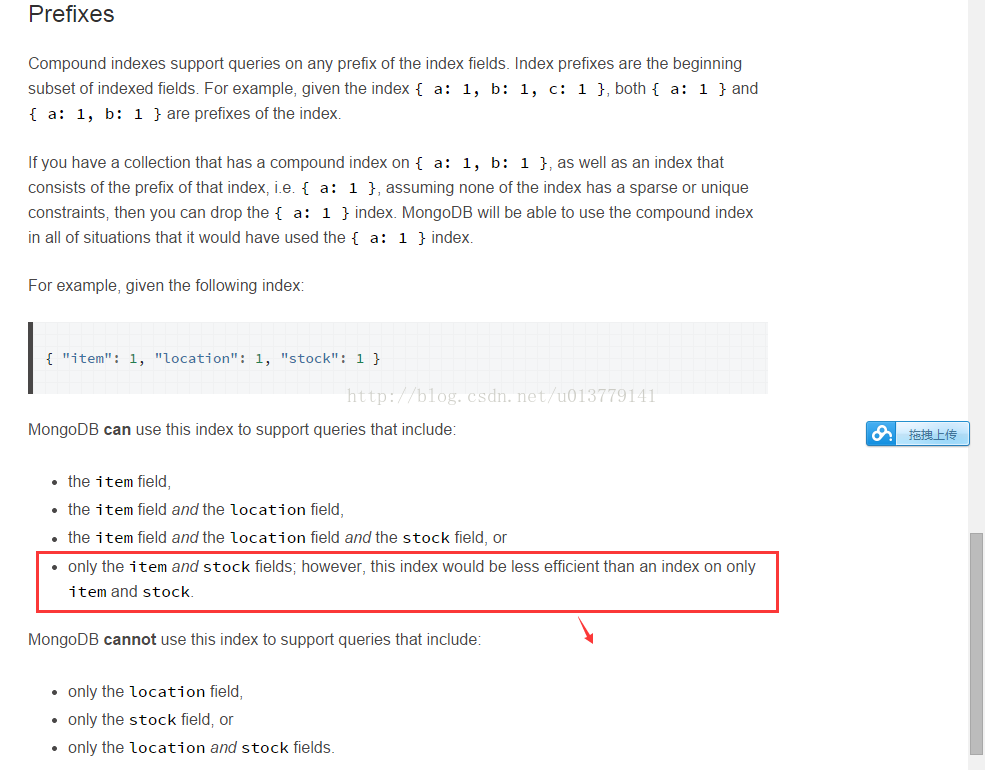
1.Array index
2.multi-Index
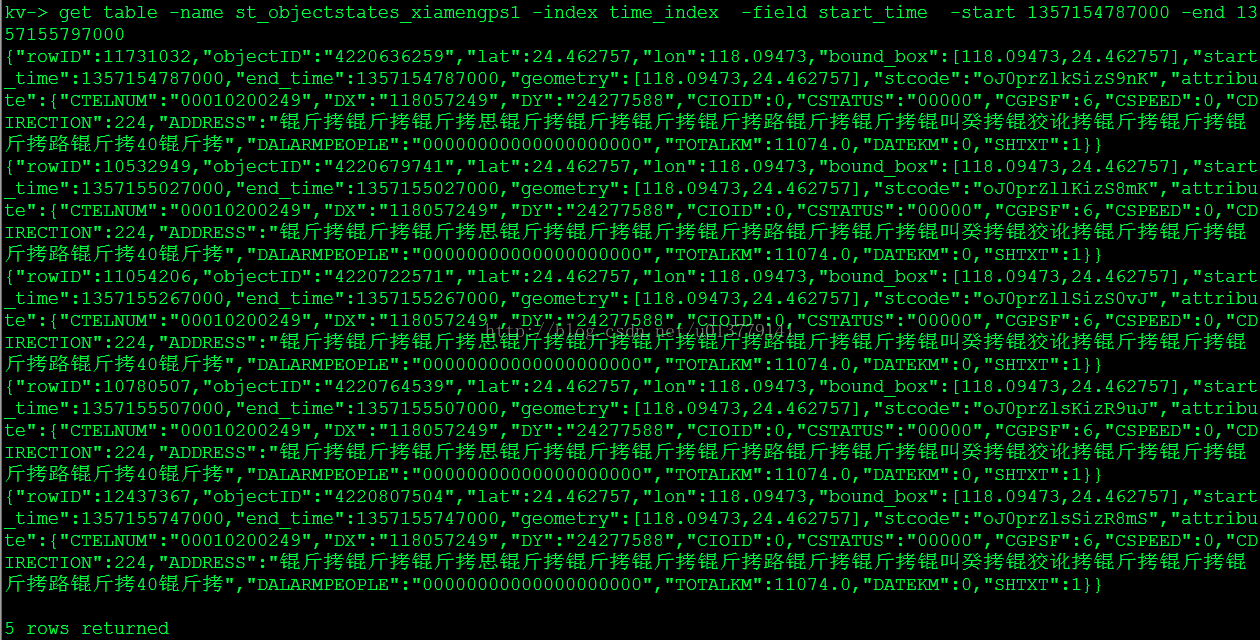





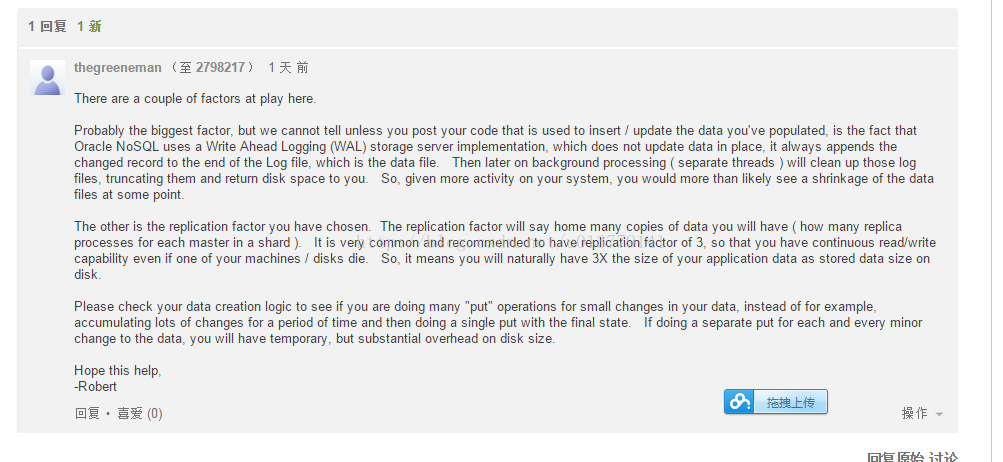
3)数据膨胀问题

4)有ChildTable的数据写入问题
5) tableIterator方法与multiGet方法对比
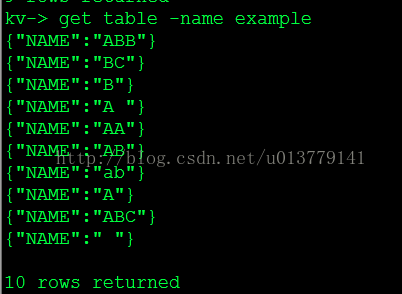
6)范围查询(FieldRange)
Oracle NoSQL DB supports range queries. You could implement regex()-type pattern matching in your client to filter out the rows that you don't want. Regex style and other pattern matching expressions will be supported in the future.
Here's an example of using either the Shard Key within a Primary Key index or using a Secondary Key index to index and fetch a range of values using the KV CLI shell:
exec "create table example1 (ID integer, NAME STRING, Primary Key (NAME))"
put table -name example1 -json '{"ID":1,"NAME":"ABCDEF"}'
put table -name example1 -json '{"ID":2,"NAME":"ABCD"}'
put table -name example1 -json '{"ID":3,"NAME":"ABCDDFR"}'
put table -name example1 -json '{"ID":4,"NAME":"AGRGE"}'
put table -name example1 -json '{"ID":5,"NAME":"DJIJOFKO"}'
put table -name example1 -json '{"ID":6,"NAME":"ABCDLLL"}'
get table -name example1 # non-ordered results of table scan #
{"ID":3,"NAME":"ABCDDFR"}
{"ID":6,"NAME":"ABCDLLL"}
{"ID":2,"NAME":"ABCD"}
{"ID":5,"NAME":"DJIJOFKO"}
{"ID":1,"NAME":"ABCDEF"}
{"ID":4,"NAME":"AGRGE"}
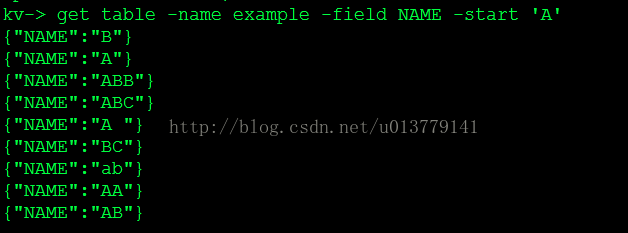
get table -name example1 -field NAME -end "ABCDZ" # Specify the highest value to be returned #
{"ID":1,"NAME":"ABCDEF"}
{"ID":6,"NAME":"ABCDLLL"}
{"ID":2,"NAME":"ABCD"}
{"ID":3,"NAME":"ABCDDFR"}
put table -name example1 -json '{"ID":7,"NAME":"AB"}' # Add another value #
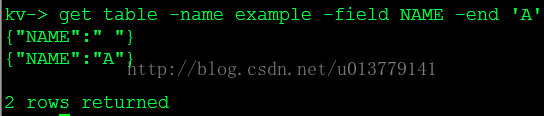
get table -name example1 -field NAME -start "ABCD" -end "ABCDZ" # Specific range of values to be returned #
{"ID":2,"NAME":"ABCD"}
{"ID":3,"NAME":"ABCDDFR"}
{"ID":1,"NAME":"ABCDEF"}
{"ID":6,"NAME":"ABCDLLL"}
Same example, using a Secondary Index:
exec "create table example (ID integer, NAME STRING, Primary Key (ID))"
exec "create index example_idx on example (NAME)"
put table -name example -json '{"ID":1,"NAME":"ABCDEF"}'
put table -name example -json '{"ID":2,"NAME":"ABCD"}'
put table -name example -json '{"ID":3,"NAME":"ABCDDFR"}'
put table -name example -json '{"ID":4,"NAME":"AGRGE"}'
put table -name example -json '{"ID":5,"NAME":"DJIJOFKO"}'
put table -name example -json '{"ID":6,"NAME":"ABCDLLL"}'
get table -name example # non-ordered results of table scan #
{"ID":4,"NAME":"AGRGE"}
{"ID":6,"NAME":"ABCDLLL"}
{"ID":2,"NAME":"ABCD"}
{"ID":5,"NAME":"DJIJOFKO"}
{"ID":3,"NAME":"ABCDDFR"}
{"ID":1,"NAME":"ABCDEF"}
get table -name example -index example_idx # ordered results of secondary index scan #
{"ID":2,"NAME":"ABCD"}
{"ID":3,"NAME":"ABCDDFR"}
{"ID":1,"NAME":"ABCDEF"}
{"ID":6,"NAME":"ABCDLLL"}
{"ID":4,"NAME":"AGRGE"}
{"ID":5,"NAME":"DJIJOFKO"}
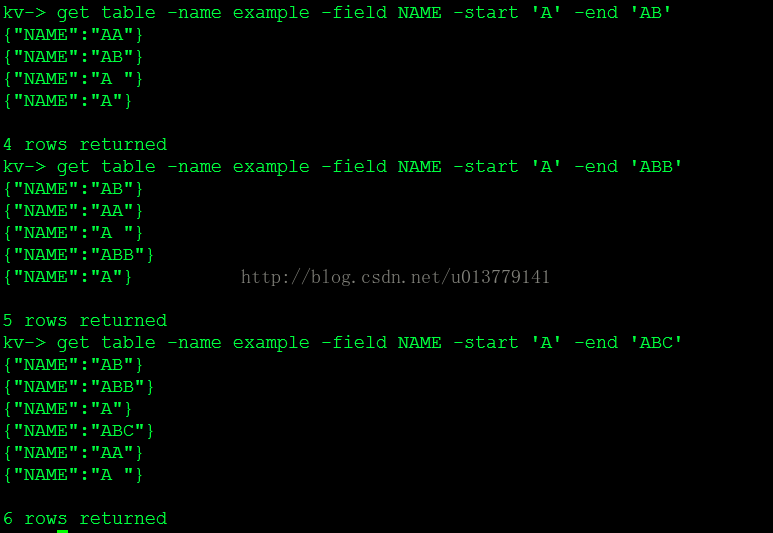
get table -name example -index example_idx -field NAME -end "ABCDZ"
{"ID":2,"NAME":"ABCD"}
{"ID":3,"NAME":"ABCDDFR"}
{"ID":1,"NAME":"ABCDEF"}
{"ID":6,"NAME":"ABCDLLL"}
put table -name example -json '{"ID":7,"NAME":"AB"}'
get table -name example -index example_idx -field NAME -start "ABCD" -end "ABCDZ"
{"ID":2,"NAME":"ABCD"}
{"ID":3,"NAME":"ABCDDFR"}
{"ID":1,"NAME":"ABCDEF"}
{"ID":6,"NAME":"ABCDLLL"}
I hope that helps. From the Java API you would use the FieldRange class to specify the start/stop points.
备注:
字母的ascii值:
space(空格)为32;
A为65,此后字母递增;
















 1245
1245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









