







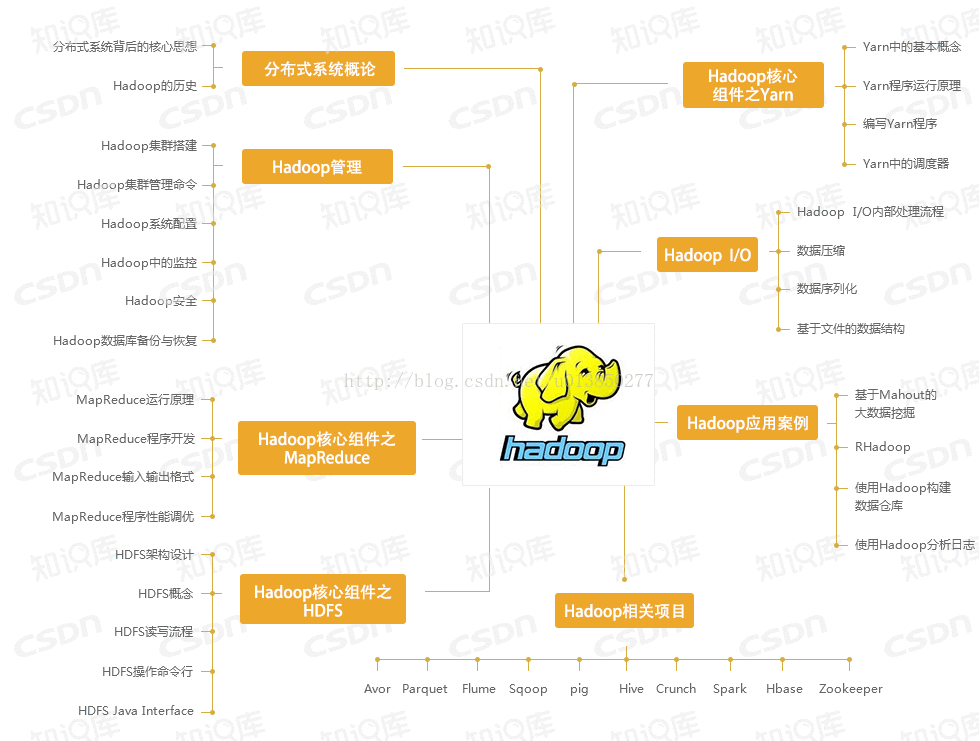
一. Hadoop的知识架构图如下所示:
二、MapReduce 的基本概念
1)MapReduce是什么?
a、MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
b、相对于Hadoop框架来说,其最核心设计就是:HDFS和MapReduce。
HDFS提供了海量数据的存储,MapReduce提供了对数据的计算。
c、MapReduce把任务分为 map(映射)阶段和reduce(化简)。
d、源自于Google 的MapReduce 论文发表于2004年12月。
Hadoop MapReduce 是Google MapReduce的克隆版。
通俗的说法如下:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。
我们人越多,数书就更快。现在我们到一起,把所有人的统计数加在一起。这就是reduce。
三、MapReduce的特点
特点:
1、易于编程(MapReduce最大的亮点)
2、良好的扩展性
3、高容错性
4、适合PB 级以上海量离线数据处理
针对上述几个特点的解析:
1、易于编程:
MapReduce提供了一种抽象机制将程序员与系统层细节隔离开来,程序员仅需描述需要计算什么(what to compute),
而具体怎么去做(how to compute)就交由系统的执行框架处理,这样程序员可从系统层细节中解放出来,而致力于其应用本身计算问题的算法设计。
例如软件工程实践指南中,专业程序员认为之所以写程序困难,
是因为程序员需要记住太多的编程细节(从变量名到复杂算法的边界情况处理),
这对大脑记忆是一个巨大的认知负担,需要高度集中注意力而并行程序编写有更多困难,
如需要考虑多线程中诸如同步等复杂繁琐的细节,由于并发执行中的不可预测性,程序的调试查错也十分困难;
大规模数据处理时程序员需要考虑诸如数据分布存储管理、数据分发、数据通信和同步、计算结果收集等诸多细节问题。
2、良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3、高容错性:
MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,
这就要求它具有很高的容错性。
比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上面上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,
而完全是由 Hadoop 内部完成的。
4、PB 级以上海量数据的离线处理
这里加上离线处理,说明它适合离线处理而不适合在线处理。比如像毫秒级别的返回一个结果,MapReduce 很难做到。
MapReduce 的特色— 不擅长的方面
1、实时计算
像MySQL 一样,在毫秒级或者秒级内返回结果
2、流式计算
MapReduce 的输入数据集是静态的,不能动态变化
MapReduce 自身的设计特点决定了数据源必须是静态的
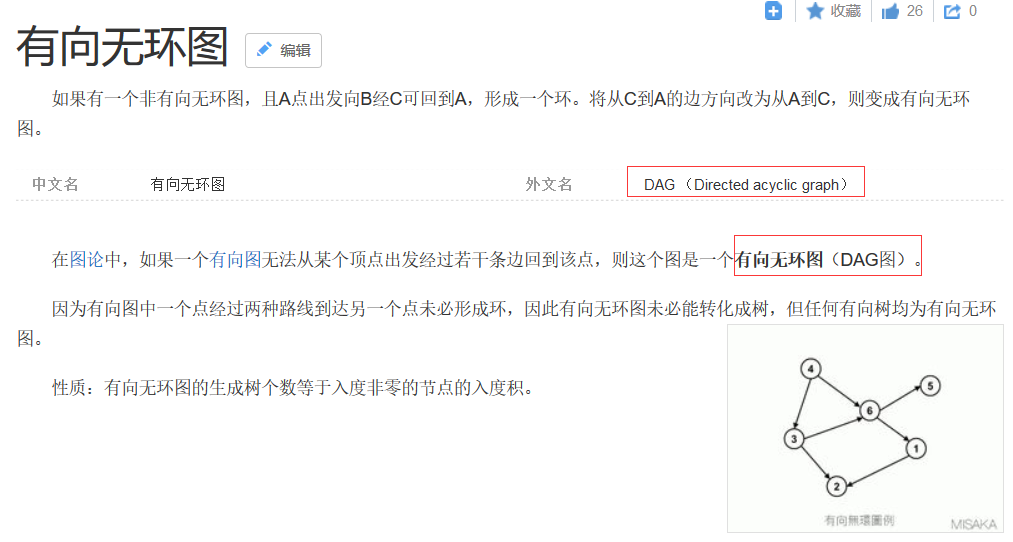
3、DAG 计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出
也就是说用MapReduce来处理的数据集(或任务)必须具备这样的特点:
待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
解说:DAG
四. MapReduce的架构
和HDFS一样,MapReduce也是采用Master/Slave的架构,其架构图如下所示。这里分别整理出MapReduce1.0与2.0的架构图
MapReduce 1.0 的架构图:
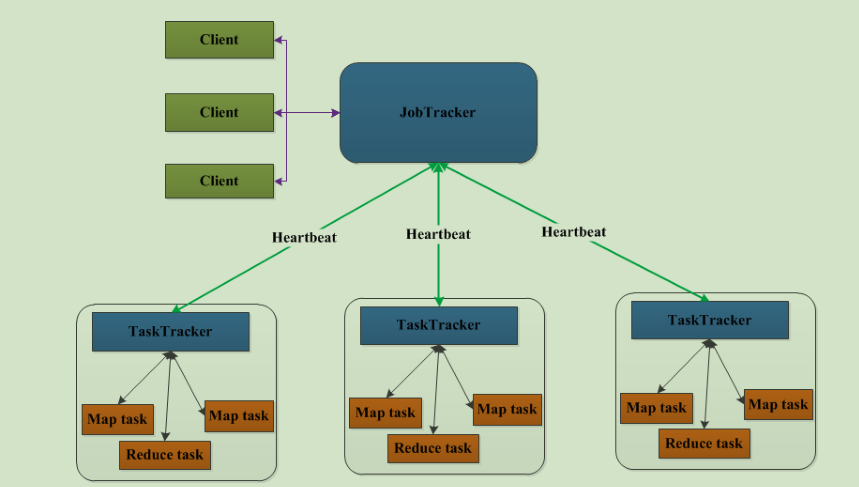
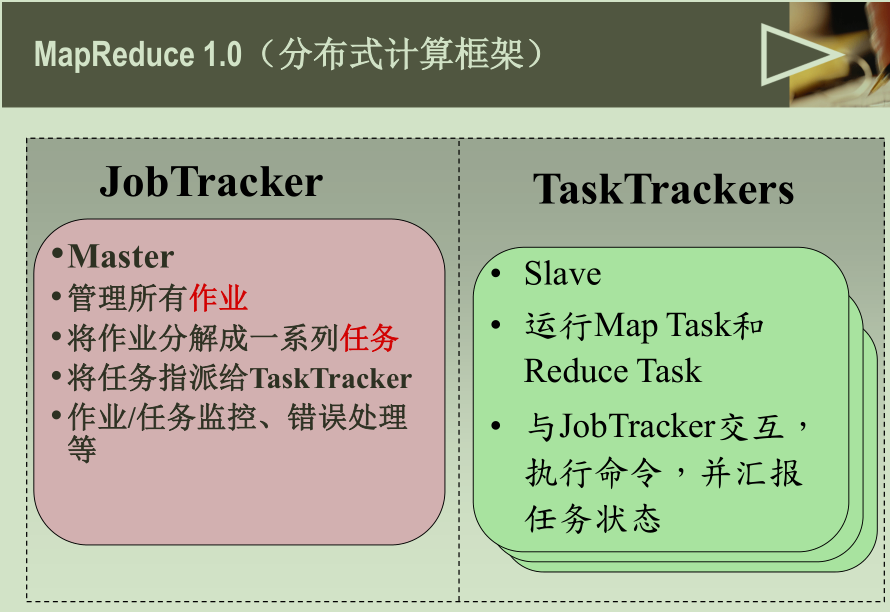
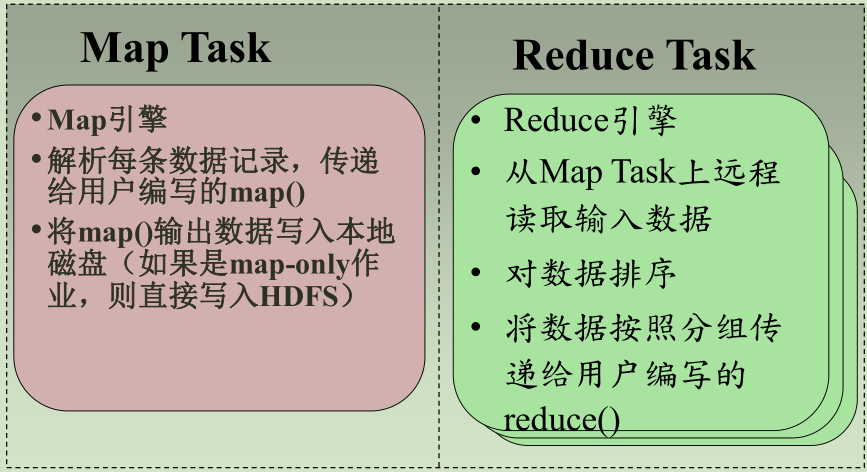
架构图解说 :
MapReduce 2.0 的架构图: (重点理解2.0的)
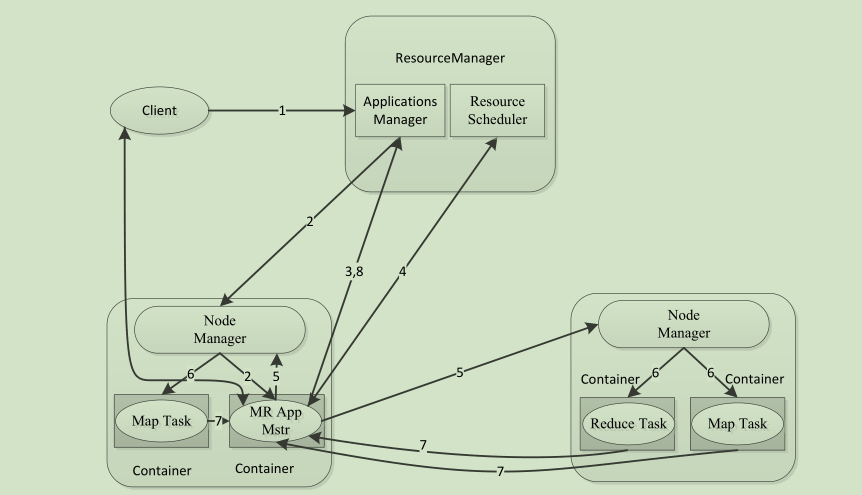
架构图解说 :
a、Client
与MapReduce 1.0 的Client类似,用户通过Client与YARN交互,提交MapReduce作业,查询作业运行状态,管理作业等。
b、MRAppMaster
功能类似于 1.0 中的JobTracker ,但不负责资源管理;
功能包括:任务划分、资源申请并将之二次分配个Map Task和Reduce Task。
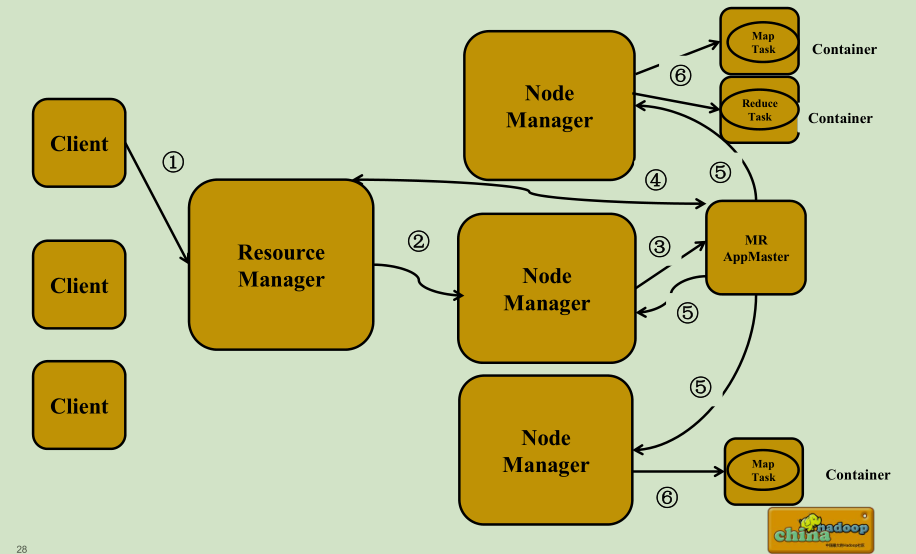
MapReduce 2.0 的运行流程
MapReduce 2.0 容错性
a、MRAppMaster 容错性
一旦运行失败,由YARN 的ResourceManager 负责重新启动,最多重启次数可由用户设置,默认是2 次。一旦超过最高重启次数,则作业运行失败。
b、Map Task/Reduce Task
Task 周期性向MRAppMaster 汇报心跳;
一旦Task 挂掉,则MRAppMaster 将为之重新申请资源,并运行之。最多重新运行次数可由用户设置,默认4 次。
MapReduce 计算框架— 推测执行机制
1、作业完成时间取决于最慢的任务完成时间
一个作业由若干个Map 任务和Reduce 任务构成
因硬件老化、软件Bug 等,某些任务可能运行非常慢
典型案例:系统中有99%的Map任务都完成了,只有少数几个Map老是进度很慢,完不成,怎么办?
2、推测执行机制:
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度
为拖后腿任务启动一个备份任务,同时运行
谁先运行完,则采用谁的结果
3、不能启用推测执行机制
任务间存在严重的负载倾斜
特殊任务,比如任务向数据库中写数据
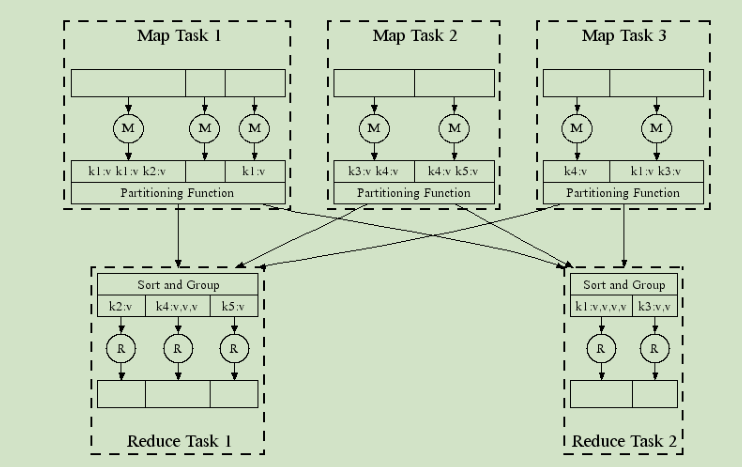
MapReduce 计算框架— 任务并行执行
五、常见MapReduce 应用场景
1、 简单的数据统计,比如网站pv 、uv 统计
2、 搜索引擎建索引
3、 海量数据查找
4、 复杂数据分析算法实现
5、 聚类算法
6、 分类算法
7、 推荐算法















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









