







直接先操作再解说:
1、通过 hive 命令进入hive shell
hive> show databases;
2、show databases;
3、show tables;
4、create table ...
eg:
hive> create table test(year string,month int,num int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';表创建成功后会在hadoop的该目录下生成对应的文件目录,
在hadoop中的路径为:/user/hive/warehouse/test
当往该目录上传文件时,只要文件格式符合test表结构就可以通过Hql查询。假如文本中数据如下
2017,1,2,2 当运行查询sql时只会查询出前三列。
5、按新建的test表结构新建test.txt广本,内容如下

hdfs dfs -put test.txt /user/hive/warehouse/test
6、运行查询语句:
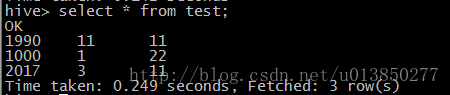
7、如果将多个文件 put 到 /user/hive/warehouse/test 目录,put 完之后直接运行查询语句结果如下:
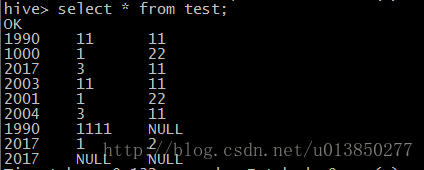
/user/hive/warehouse/test 目录下文件内容分别如下所示:
test.txt
1990,11,11
1000,1,22
2017,03,11
test1.txt
2003,11,11
2001,1,22
2004,3,11
test2.txt
1990,1111
2017,1,2,2
2017通过上述我们可以发现,当我们动态地往/user/hive/warehouse/test 目录下添加文件时是不需要对test表进行任何处理便可直接通过类sql 语句查询出该目录中的所有文件(当然得是符合test表结构的数据);
8、desc test;
hive> desc test;
year string
month int
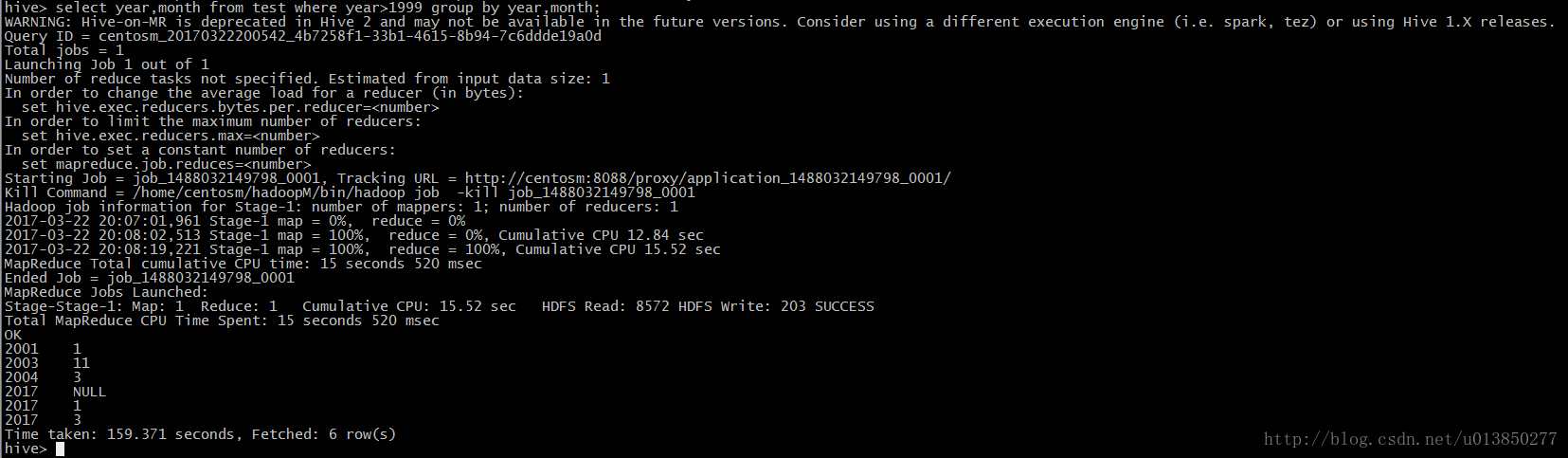
num int 9、select year,month from test where year>1999 group by year,month;
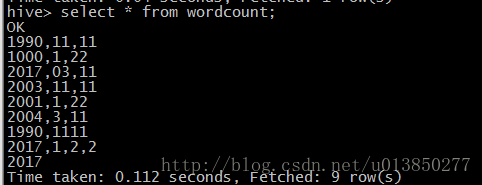
10、运用hive 进行wordCount 统计
场景将/user/hive/warehouse/test 目录下的文件进行wordCount统计。统计前如下所示:
create table wordcount(text string);
select explode(split(word,’[,]’)) word from wordcount;
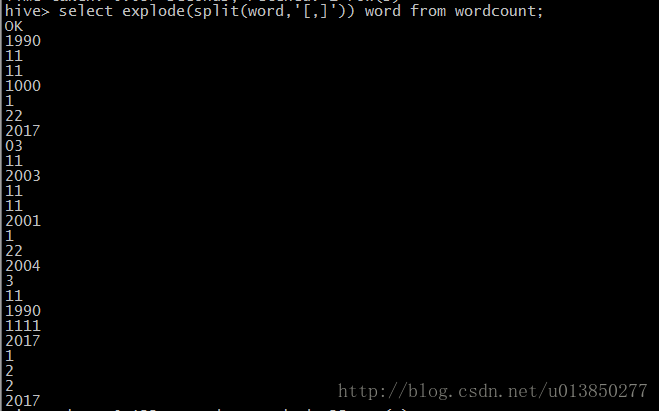
create table result(word string);
insert overwrite table result select explode(split(word,’[,]’)) word from wordcount;
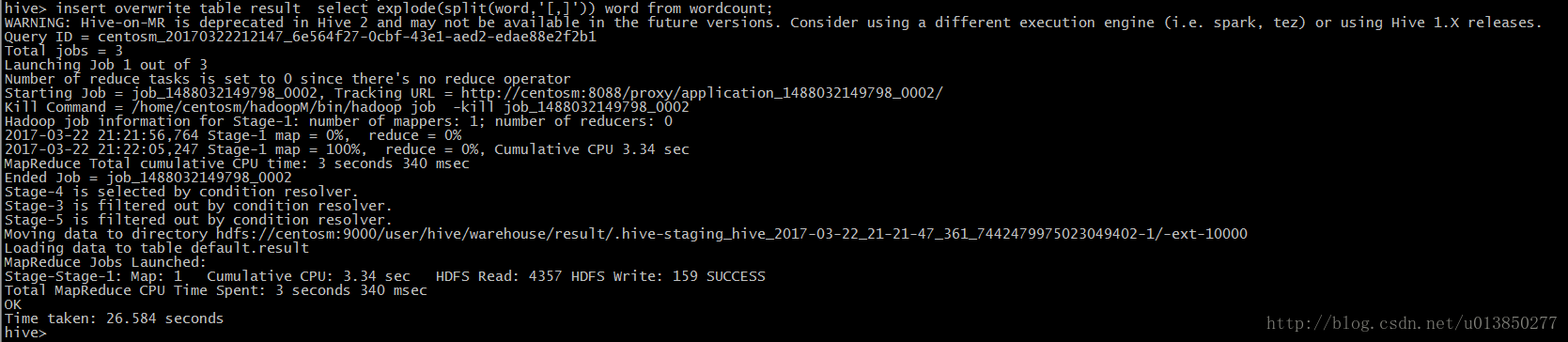
统计后的结果如下所示:
select word,count(1) from result group by word;
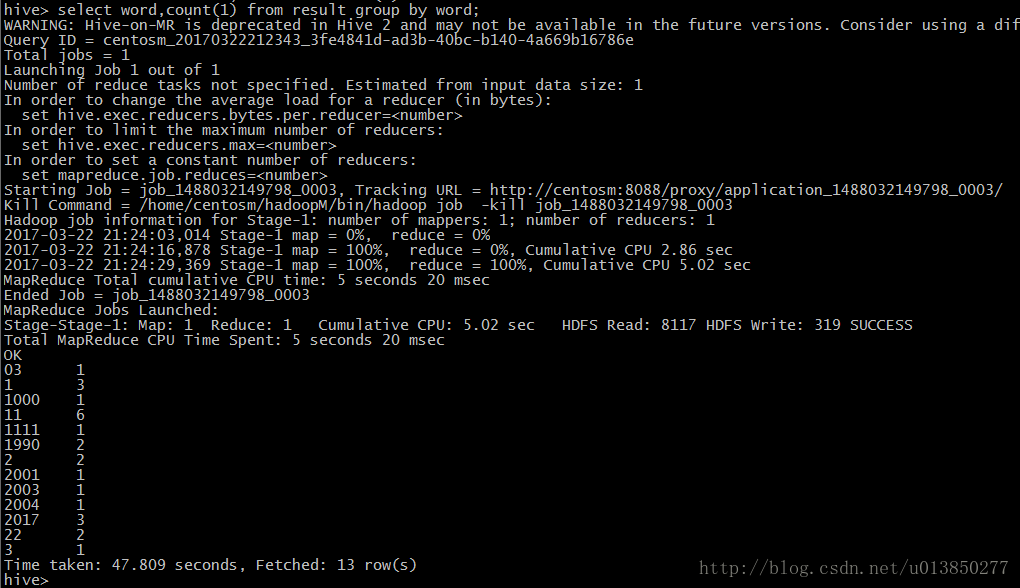
11、show create table tableName;
可查看table在hdfs上的存储路径
二、数据定义语句(DDL)
Create/Drop/Alter Database
Create/Drop/Truncate Table
Alter Table/Partition/Column
Create/Drop/Alter View
Create/Drop/Alter Index
Create/Drop Function
Create/Drop/Grant/Revoke Roles and Privileges
Show
Describe
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
(col_name data_type, ...)
[PARTITIONED BY (col_name data_type, ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY
(col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...)]
[ [ROW FORMAT row_format] [STORED AS file_format] ]
[LOCATION hdfs_path]
eg:

ROW FORMAT DELIMITED :保留关键字
FIELDS TERMINATED BY :列分隔符
COLLECTION ITEMS TERMINATED BY :元素间分隔符
MAP KEYS TERMINATED BY :key/value 对间的分隔符
LINES TERMINATED BY : 行分隔符
支持的数据类型
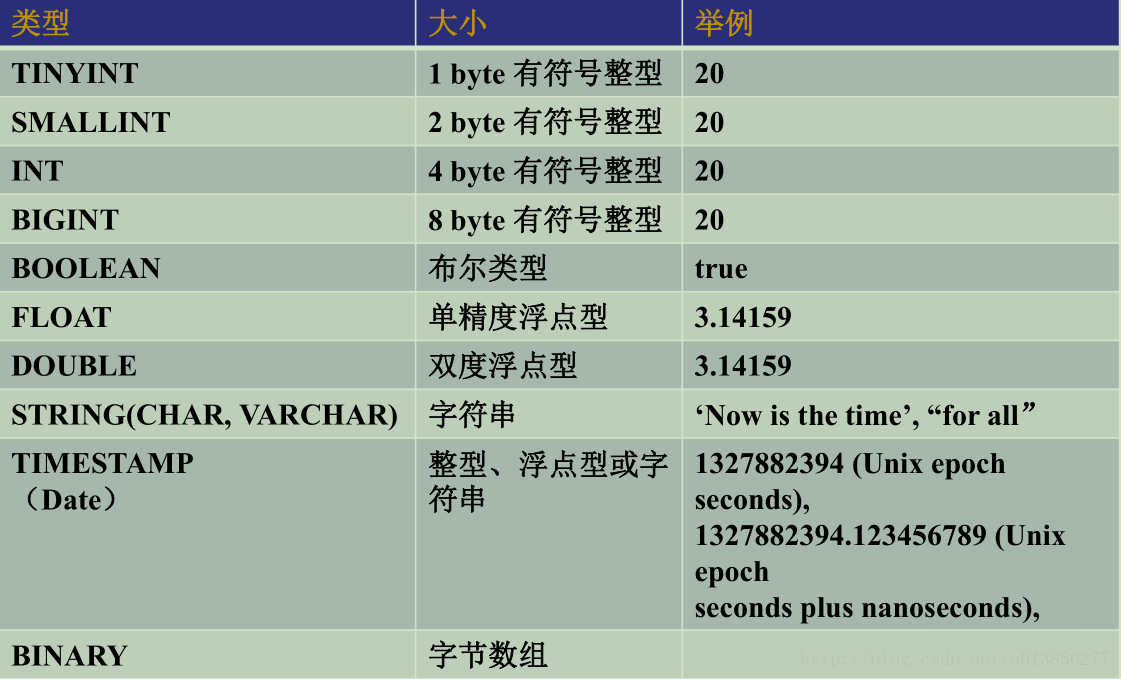

数据操作语句(DML)
数据加载与插入语句
LOAD
INSERT
数据查询语句
SELECT
查看HQL执行计划
explain
表/分区导入导出
Export/Import
数据加载与插入语句
Load data
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename[PARTITION(partcol1=val1, partcol2=val2 ...)]
Insert
INSERT OVERWRITE TABLE tablename[PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement FROM from_statement
Multiple insert
FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION...)] select_statement1 [INSERT OVERWRITE TABLE tablename2 [PARTITION ...] select_statement2] ...
数据加载与插入语句
Load data
当数据被加载至表中时,不会对数据进行任何转换。
Load 操作只是将数据复制/ 移动至 Hive 表对应的位置。
默认每个表一个目录,比如数据库dbtest中,表名为tbtest ,则数据存放位置为:${metastore.warehouse.dir}/dbtest.db/tbtest
metastore.warehouse.dir 默认值是/user/hive/warehouse
三、修改表属性
Alter Table 语句
它是在Hive中用来修改的表。
语法
声明接受任意属性,我们希望在一个表中修改以下语法。
ALTER TABLE name RENAME TO new_name
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
ALTER TABLE name DROP [COLUMN] column_name
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])













 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









