







多线程实际上CUP没有同时执行这些线程,而是多个线程中高速的切换执行,感觉上像一起在执行。这个在后面会用到。。。。
程序目的:
在当前目录中分类存储淘女郎图片,如图:
爬虫的入口选择:
刚开始我将https://mm.taobao.com/search_tstar_model.htm?spm=719.1001036.1998606017.2.zXhBZ8做为爬虫的入口,后来发现页面总会自动跳转到淘宝登录页面,但模拟淘宝登录比较复杂,只能使用https://mm.taobao.com/json/request_top_list.htm?page=1(简单就是美~~!)
获取女郎主页:
打开https://mm.taobao.com/json/request_top_list.htm?page=1,右击鼠标–>审查元素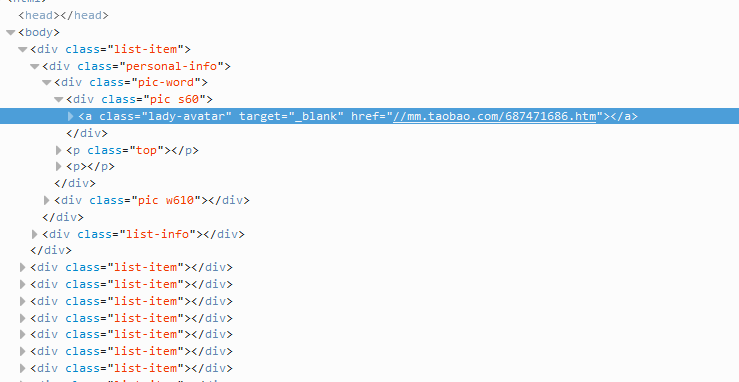
这里我使用BeautifulSoup筛选(也可以使用正则表达式)需要的信息,关于BeautifulSoup的使用可以查看http://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
import threading
import time
import urllib
import urllib.request
import os,queue,re
from bs4 import BeautifulSoup
hostUrls=queue.Queue()
girlsUrls=queue.Queue()
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
try:
hostUrl=hostUrls.get(timeout=2)
except queue.Empty:
print("queue empty")
return
request=urllib.request.Request(hostUrl,headers=headers)
response=urllib.request.urlopen(request)
data=response.read().decode('gbk')
soup=BeautifulSoup(data)
tag_lady=soup.find_all("a",attrs={"class":"lady-avatar"})
for tag_href in tag_lady:
girlsUrls.put("https:"+tag_href['href'])
print("录入:https:"+tag_href['href'])获取淘女郎图片:
打开任意淘女郎主页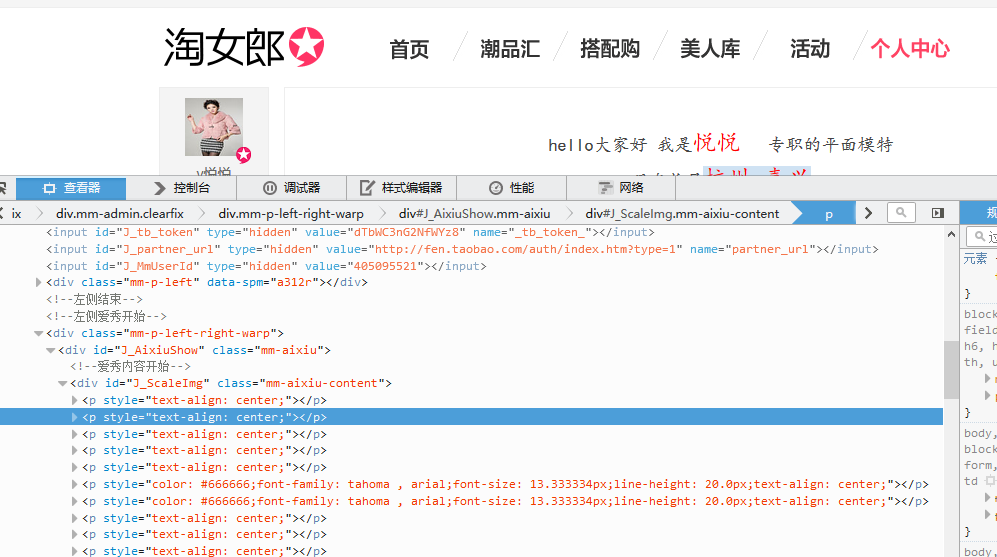
抓取”爱秀内容“中的图片,并将图片保存本地。由于上一步抓取的链接需要登录淘宝才能正常浏览,没办法只能再次更换链接。。。。囧!百度淘女郎,发现不需要登录也能正常浏览,所以我们将其id更好成已经抓取的主页id。
user_agent ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240'
headers={'User-Agent':user_agent}
try:
ur=girlsUrls.get(timeout=5)
except queue.Empty:
print(name+" imgqueue empty")
return
pattern=re.compile(r"/(\d+).htm")
items=pattern.findall(ur)
girlUrl="https://mm.taobao.com/self/aiShow.htm?userId="+ite````
s[0]
接下来终于可以抓取美女图片了^^,点击审查元素可以看到”爱秀内容开始“在一个class=”mm-aixiu-content”的div中,我们只需找出这部分中的img元素就行。
request=urllib.request.Request(girlUrl,headers=headers)
response=urllib.request.urlopen(request)
data=response.read()
soup=BeautifulSoup(data)
fileName=soup.head.title.contents
fileName[0]=fileName[0].rstrip()
tag_div=soup.find('div',attrs={"class":"mm-aixiu-content"})
imgs=tag_div.find_all("img",attrs={})然后从imgs中得到src链接:
for img in imgs:
link=img.get('src')
if link:
s="http:"+str(link)
最后只剩下存储了!!!使用os.getcwd()得到程序运行的当前目录,os.makedirs(path)创建目录,open(pathfile,’wb’)新建文件并写二进制数据。
cdir=os.getcwd()
path=cdir+'/'+str(fileName[0])
if not os.path.exists(path):
os.makedirs(path)
n=0
for img in imgs:
n=n+1
link=img.get('src')
if link:
s="http:"+str(link)
i=link[link.rfind('.'):] #分离文件扩展名
try:
request=urllib.request.Request(s)
response=urllib.request.urlopen(request)
imgData=response.read()
pathfile=path+r'/'+str(n)+i
with open(pathfile,'wb') as f:
f.write(imgData)
f.close()
print" write:"+pathfile)
except:
print("write false:"+s)以下是全部代码:
import threading
import time
import urllib
import urllib.request
import os,queue,re
from bs4 import BeautifulSoup
def getUrl(name,hostUrls,girlsUrls,flag):
while not flag.isSet():
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
try:
hostUrl=hostUrls.get(timeout=2)
except queue.Empty:
print("queue empty")
return
request=urllib.request.Request(hostUrl,headers=headers)
response=urllib.request.urlopen(request)
data=response.read().decode('gbk')
soup=BeautifulSoup(data)
tag_lady=soup.find_all("a",attrs={"class":"lady-avatar"})
for tag_href in tag_lady:
girlsUrls.put("https:"+tag_href['href'])
print("录入:https:"+tag_href['href'])
hostUrls.task_done()
print("getUrl is working")
def getImg(name,girlsUrls,flag):
while not flag.isSet():
user_agent ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240'
headers={'User-Agent':user_agent}
try:
ur=girlsUrls.get(timeout=5)
except queue.Empty:
print(name+" imgqueue empty")
return
pattern=re.compile(r"/(\d+).htm")
items=pattern.findall(ur)
girlUrl="https://mm.taobao.com/self/aiShow.htm?userId="+items[0]
request=urllib.request.Request(girlUrl,headers=headers)
response=urllib.request.urlopen(request)
data=response.read()
soup=BeautifulSoup(data)
fileName=soup.head.title.contents
fileName[0]=fileName[0].rstrip()
tag_div=soup.find('div',attrs={"class":"mm-aixiu-content"})
imgs=tag_div.find_all("img",attrs={})
if len(imgs)==0:
girlsUrls.task_done()
return
path=cdir+'/'+str(fileName[0])
if not os.path.exists(path):
os.makedirs(path)
n=0
for img in imgs:
n=n+1
link=img.get('src')
if link:
s="http:"+str(link)
i=link[link.rfind('.'):]
try:
request=urllib.request.Request(s)
response=urllib.request.urlopen(request)
imgData=response.read()
pathfile=path+r'/'+str(n)+i
with open(pathfile,'wb') as f:
f.write(imgData)
f.close()
print("thread "+name+" write:"+pathfile)
except:
print(str(name)+" thread write false:"+s)
girlsUrls.task_done()
#start=time.time()
if __name__=='__main__':
start=time.time()
hostUrls=queue.Queue()
girlsUrls=queue.Queue()
cdir=os.getcwd()
url='https://mm.taobao.com/json/request_top_list.htm?page='
flag_girl=threading.Event()
flag_img=threading.Event()
for i in range(1,3):
u=url+str(i)
hostUrls.put(u)
threads_girl = threading.Thread(target=getUrl, args=(str(1), hostUrls,girlsUrls,flag_girl))
threads_img = [threading.Thread(target=getImg, args=(str(i+1), girlsUrls,flag_img))
for i in range(8)]
threads_girl.start()
while(girlsUrls.empty()):
print("wait..")
time.sleep(0.1)
for t in threads_img:
t.start()
hostUrls.join()
flag_girl.set()
girlsUrls.join()
flag_img.set()
for t in threads_img:
t.join()
end=time.time()
print("run time:"+str(end-start))














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









