







用python OCR库pytesseract 写的一个OCR识别身份证程序:https://github.com/iChenwin/pytesseractID
先用中文做个示例:
- 拿到一张
chi.pingfang.exp0.jpg:
- 将它转化为
tif:http://image.online-convert.com/convert-to-tiff - 拿到
chi.pingfang.exp0.tif之后,开始训练。

第一步,生成box文件。
//由tif图片生成box文件
tesseract chi.pingfang.exp0.tif chi.pingfang.exp0 -l chi_sim batch.nochop makebox
这样就得到一个 “chi.pingfang.exp0.box” 文件,它在tif图片文件上用方框标注了它识别出的汉字。
它的识别不能保证100%对,要手动纠错,用的是 “JTessBoxEditor”。
修正完之后
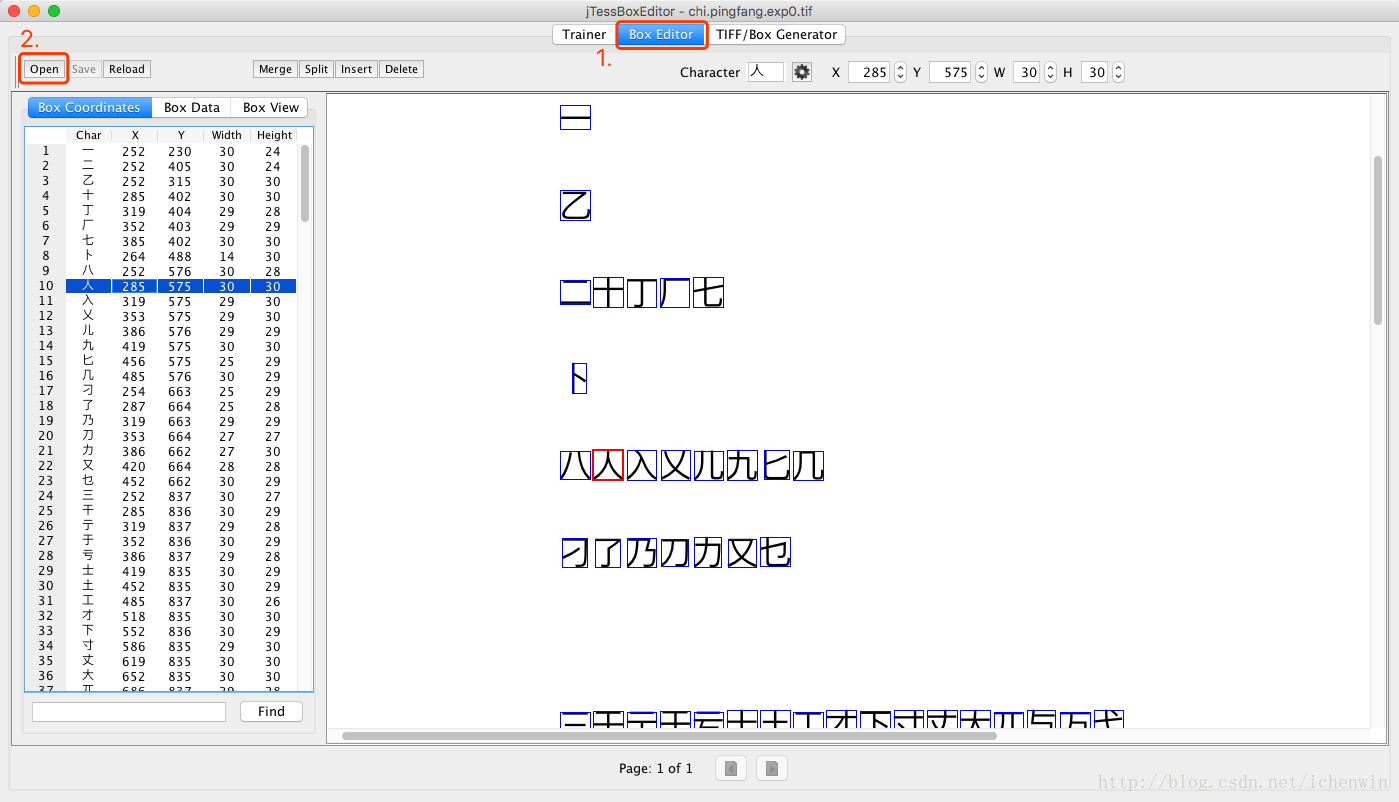
第二步,训练,生成特征文件。
tesseract chi.pingfang.exp0.tif chi.pingfang.exp0 nobatch box.train
unicharset_extractor chi.pingfang.exp0.box
第三步,聚集
新建一个 font_properties 文件,内容是PingFang 0 0 0 0 0 (5个零表示:斜体, 粗体, 无衬线体, 衬线体, 哥特体)
上一步的特征文件生成后,需要将同样文字的不同字体的特征聚集到一起来产生该文字的一个原型 ,这一步需要执行三个命令:
shapeclustering -F font_properties -U unicharset chi.pingfang.exp0.tr
这一步将会生成一个名为 shapetable 的文件。
mftraining -F font_properties -U unicharset -O chi.unicharset chi.pingfang.exp0.tr
这一步将会生成一个名为 inttemp 的文件和一个名为 pffmtable 的文件。
cntraining chi.pingfang.exp0.tr
这一步将会生成一个名为 normproto 的文件。
上述命令将生成名为 chi.pingfang.exp0.tr 的特征文件。对每一张生成的 TIF 图像,都要进行该步骤以生成特征文件。
第四步,打包
在上述步骤都完成后,将要打包入资源文件的那些文件加上一个统一的前缀,该前缀即是待生成的资源文件的名称,这里假定我们要生成 chi.traineddata 这样一个资源文件,那么我们的可能操作就是:
mv unicharset chi.unicharset
mv shapetable chi.shapetable
mv inttemp chi.inttemp
mv pffmtable chi.pffmtable
mv normproto chi.normproto
combine_tessdata chi
至此,一个简单的训练过程结束。
参考:Tesseract-OCR识别中文与训练字库实例
Tesseract:训练
Tesseract-OCR 验证码识别服务
开源OCR引擎Tesseract















 2643
2643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









