







Massive Exploration of Neural Machine Translation Architectures, Google Brain2017
该文章主要做了大量的实验,可做为overview读。
总结点:
1. encoder比decoder更难优化;LSTM比GRU效果好;beam search很重要;data preprocessing对结果影响很大,该文章直接用的是Moses做的清洗数据和tokenize[1],learn shared subword units using Byte Pair Encoding (BPE)[2];
2. 开源出一个基于tensorflow的seq2seq工具包;
Experiment Results:
1. the embedding layer在2.5M steps训练内影响不大;??
ref:
[1].https://github.com/moses-smt/mosesdecoder/
[2].Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016b. Neural machine translation of rare words with subword units. In ACL.
Convolutional Sequence to Sequence Learning, facebook AI Research 2017
注:该篇论文与下篇论文为同一作者,同一系列,放一起看
创新点:
1. seq2seq架构中放弃RNN,完全用CNN + Gated linear units + Residual connections + Attention,convolution只能表达固定长度的文本,但是堆积多层可以使得可表达的文本长度变大,通过这种方式可以精确地控制目标依赖的源文本长度。
2. CNN网络的计算不像RNN会依赖于前一时刻的状态,所以可以允许在序列中的每一元素上并行。
3. Multi-layer CNN获取长时/长距离依赖时,所提供的path比RNN提供的更短,因为RNN是链式的。e.g. n个words的representation,CNN 卷积运算复杂度为O(n/k) ,k为窗口长度,RNN线性复杂度O(n).
A convolutional encoder model for neural machine translation, facebook AI Research 2017
创新点:将CNN成功的用在了NMT任务上,并对比Bi-LSTM获得了最好的BLEU结果,且速度提高。
1.Recurrent Neural Machine Translation
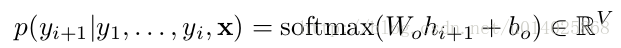
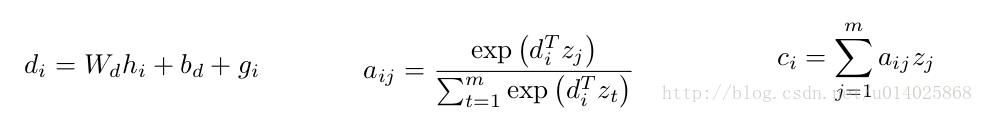
结论及任务列表:
该论文给出MLP attention方法并没有得到更好的BLEU或PPL,待读文章:Neural machine translation by jointly
learning to align and translate, 2015
2.Non-recurrent Encoders: pooling encoder
poolong model (Ranzato et al. (2015)), 首先将word(j)进行embedding得w(j),然后将k个连续的embeded word vecotors(w(j)~w(j+k-1))求平均。
问题:该方法不包括位置信息,并且input中的word vectors在一定程度上很接近
解决方案:在embed的时候加入位置信息,即position embedding得到的l(j), k = 5
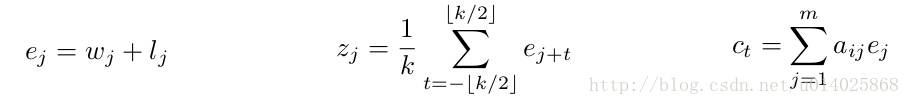
任务列表:
position embedding在QA及语言模型中也是有效果的(Sukhbaatar et al., 2015),待读文章:End-to-end Memory Net-works. Sainbayar Sukhbaatar2015
3.Non-recurrent Encoders:Convolutional Encoder

Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
该论文要解决的三个问题:
1. train和inference速度慢
提出GNMT,8层encoder+8层decoder,encoder和decoder之间的链接利用residual connection和attention connection,同时利用低精度算法加快训练。
2. NMT systems lack robustness,particularly when input sentences contain rare words. OOV/UNK/rare word
sub-word units (“wordpieces”)
3. 翻译结果coverage不全,即有部分词未翻译/解码
length penalty 和 coverage penalty














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









