







一、Scala安装
- 下载scala安装包,地址:http://www.scala-lang.org/download/
配置环境变量
下载完成后,解压到指定的目录下,在/etc/profile文件中配置环境变量:export SCALA_HOME=/usr/local/jiang/scala-2.10.6 export PATH=$PATH:$SCALA_HOME/bin验证scala的安装
[root@logsrv03 etc]# scala -version Scala code runner version 2.10.6 -- Copyright 2002-2013, LAMP/EPFL
二、安装spark
- 下载spark安装包,地址:http://spark.apache.org/downloads.html
下载完成后,拷贝到指定的目录下:/usr/local/jiang/,然后解压:
tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz解压后在配置中添加java环境变量、scala环境变量、hadoop环境变量等conf/spark-env.sh
# set scala environment export SCALA_HOME=/usr/local/jiang/scala-2.10.6 # set java environment export JAVA_HOME=/usr/local/jdk1.7.0_71 # set hadoop export HADOOP_HOME=/usr/local/jiang/hadoop-2.7.1 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop # set spark SPARK_MASTER_IP=logsrv03 SPARK_LOCAL_DIRS=/usr/local/jiang/spark-1.6.0 SPARK_DRIVER_MEMORY=1G配置从机conf/slaves
logsrv02 logsrv04当然这里配置的是主机名,所以在/etc/hosts中一定要添加主机名和ip的映射,不然没法识别的:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.17.6.141 logsrv01 172.17.6.142 logsrv02 172.17.6.149 logsrv04 172.17.6.148 logsrv03 172.17.6.150 logsrv05 172.17.6.159 logsrv08 172.17.6.160 logsrv09 172.17.6.161 logsrv10 172.17.6.164 logtest01 172.17.6.165 logtest02 172.17.6.166 logtest03 172.30.2.193 devops172302193 172.30.2.194 devops172302194 172.30.2.195 devops172302195将配置好的spark-1.6.0-bin-hadoop2.6文件远程拷贝到相对应的从机中:
[root@logsrv03 jiang]# scp -r spark-1.6.0-bin-hadoop2.6 root@logsrv02:/usr/local/jiang/ [root@logsrv03 jiang]# scp -r spark-1.6.0-bin-hadoop2.6 root@logsrv04:/usr/local/jiang/启动集群
[root@logsrv03 spark-1.6.0-bin-hadoop2.6]# sbin/start-all.sh启动完成后,查看主从机的进程:
主机:[root@logsrv03 spark-1.6.0-bin-hadoop2.6]# jps 25325 NameNode 23973 Master 17643 ResourceManager 25523 SecondaryNameNode 28839 Jps从机:
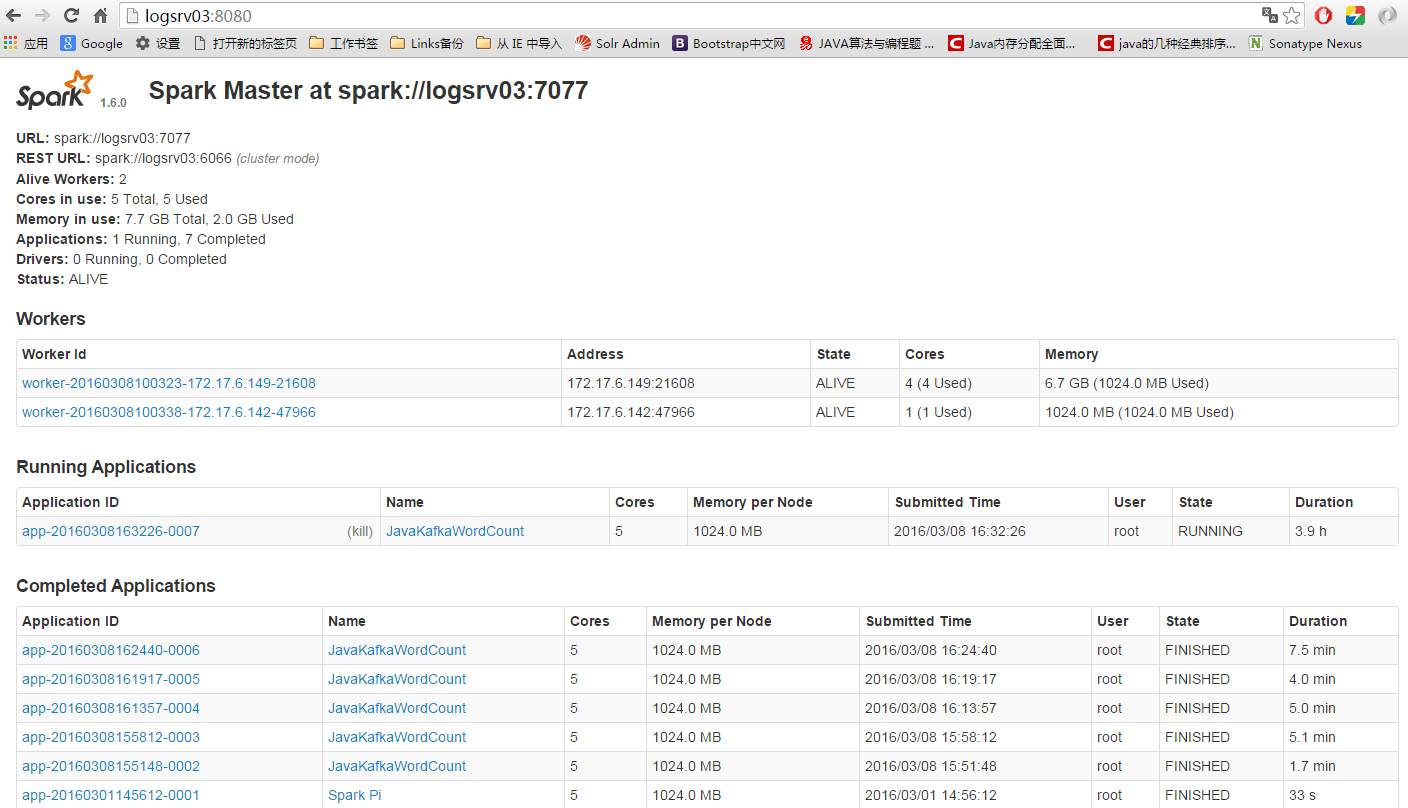
[root@logsrv02 spark-1.6.0-bin-hadoop2.6]# jps 744 Worker 4406 Jps 2057 DataNode 2170 NodeManager三、安装完成后,可以查看spark的UI:
运行wordcout例子:
命令:
./bin/spark-submit \
--name JavaKafkaWordCount \
--master spark://logsrv03:7077 \
--executor-memory 1G \
--class examples.streaming.JavaKafkaWordCount \
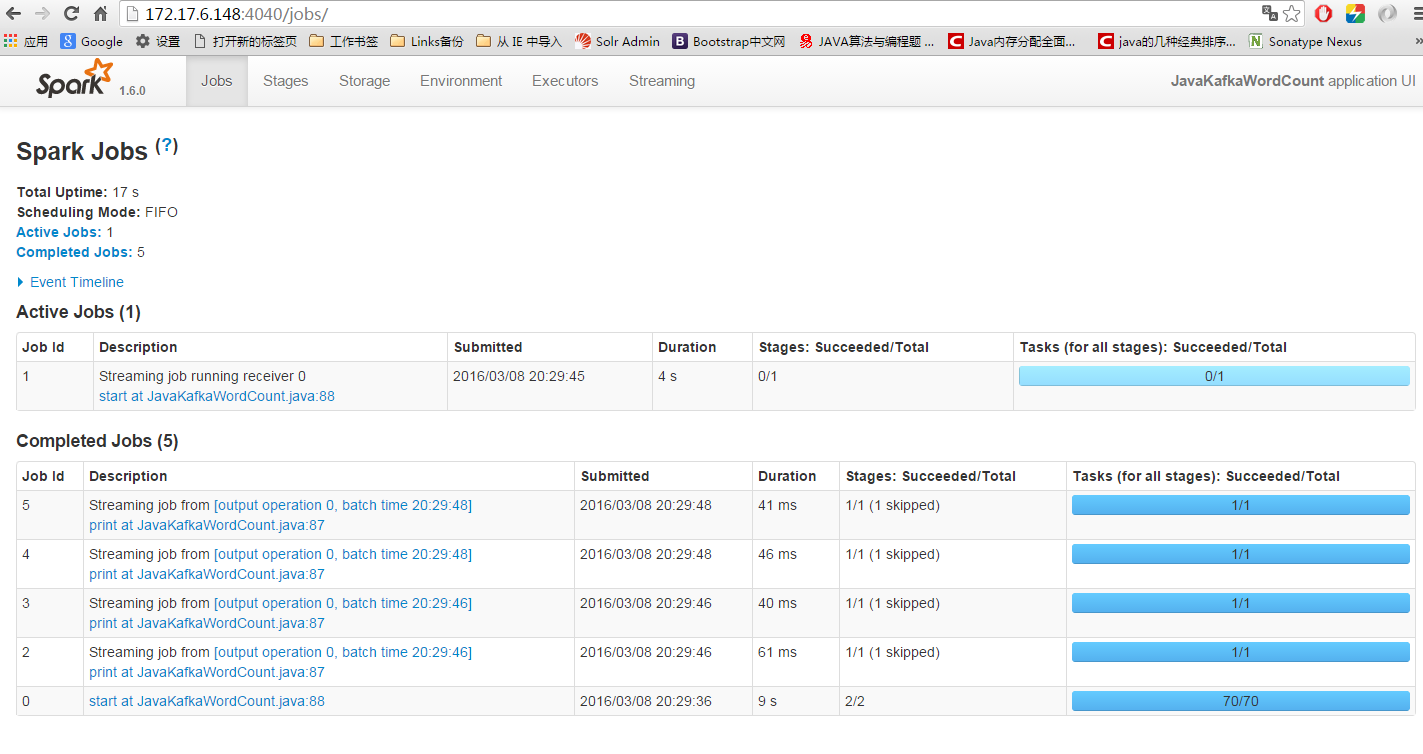
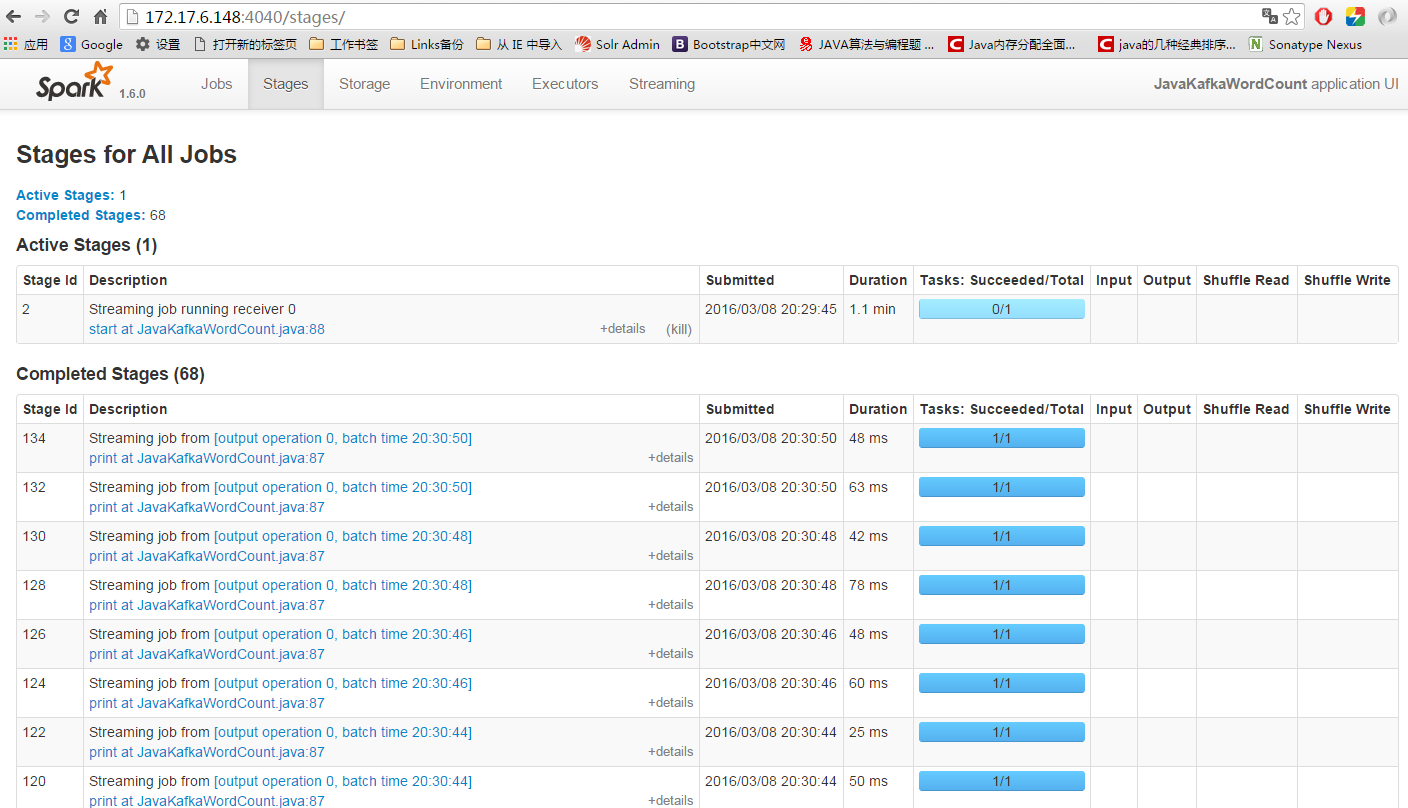
log_spark-0.0.1-SNAPSHOT.jar 172.17.6.142:2181,172.17.6.148:2181,172.17.6.149:2181 11 log-topic 5运行后spark的UI:














 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









