







要理解索引,⾸先我们必须理解索引的概念。
什么是索引?
索引,它是一种数据结构,⽤来快速定位一个数据集合中的某一个记录。现实的实例:新华字典,就是一个用索引思想来进⾏查询操作的典型实例。
那么,索引是什么样的数据结构呢?
Hash索引
B+树索引
在数据库中,B+树索引是最常见的⼀种索引。基本所有的关系数据库都支持它, 例如MySQL,Oracle,MS SQLServer,Postgre等等。
什么是B+树?B+树是
a)⼀种树形的数据结构,
b)用于快速查询,
b)专门⽤于硬盘存储。除了数据库常用B+树索引之外,操作系统中的文件系统也采⽤它来作为元数据索引。
B+树的特点是:
1) 数据有序
2) 插入、修改和查询的时间复杂度都是lgN
要理解B+树,⾸先介绍一下平衡⼆叉查找树。
平衡二叉查找树
先看看⼆叉查找树的定义:
1) 任意⼀个节点,都最多只有两个子节点(⼆叉的含义)
2) 如果左子树不为空,那么左子树的所有节点都小于或等于根节点的值
3) 如果右子树不为空,那么右子树的所有节点都大于或等于根节点的值
4) 左⼦树和右⼦树都是二叉查找树
例如:
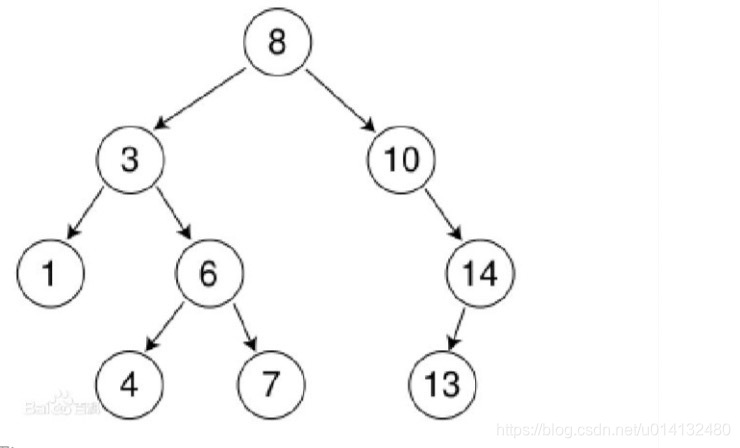
⼀个最优的二叉查找树,查询的时间复杂度一般都是lgN,但最坏的情况下二叉查找树的性能可能会退化成线性:
平衡⼆叉查找树,就是一个特殊的二叉查找树,此外,还需要满足:
1) 对应B树的任意节点,它的左子树和右子树的高度差最大是1
对于平衡二叉查找树,可以保证查询的时间复杂度是O(lgN)。但平衡⼆叉查找树有一些问题:
1. 一个节点最多只有两个子节点,当数据量大的时候,树的高度很高
2. 在文件系统或者数据库中,数据量很大,不可能全部放到内存中,只能是放在硬盘上。如果用平衡二叉查找树来存储数据,当树的高度很高时,会导致多次的随机的I/O操作
3. 不支持顺序的读取数据 这就决定了平衡二叉查找树不适合硬盘存储,更多用于内存操作的场景。
B树(B-树)
正如上文提到,平衡⼆叉查找树,并不适合大量数据的查找。问题主要出在“二叉”这个特性上。那么很自然,我们就把树发展成“多叉”,这样可以显著降低树的高度。此外,树的每个节点都存储多条数据(二叉树是⼀个节点对应一条数据),尽可能减少随机的I/O。
B树,⼜称多路(多叉)平衡查找树,是满⾜上述需求的一种树形数据结构。⼀个m阶的B树的定义如下:
每个节点都最多拥有m个⼦节点
每个非叶节点(除了根节点外)⾄少拥有⌈m/2⌉(取上整)个⼦节点。结合第⼀点,每个非叶节点的子节点的数量量在闭区间 [⌈m/2⌉, m] 中。
当根节点是叶节点时,意味着数据量很小,一个根节点就能存储下,此时数 据的数量小于或等于(m-1)
当根节点不是叶节点时,根节点⾄至少拥有2个⼦子节点,结合第⼀点,即 [2,m]
⾮叶节点的子节点数量为k时,它拥有(k-1)个关键字key。结合第一点和第二点,可以看到每个⾮非叶节点的关键字key的数量量在闭区间 [⌈m/2⌉-1, m-1] 中。
所有的叶节点都在树的同⼀层,允许拥有的关键字数量同样也是在闭区间 [⌈m/2⌉-1, m-1] 中,但叶节点没有⼦节点(同时也没有指向子节点的指针)
对于阶数m,很容易理解:m即每个节点所能拥有的最⼤的子节点数量,(m-1) 也是每个节点所能拥有的最大的关键字数量。很⾃然,m不能无限制的大,否则⼀棵树就只有一个或寥寥⼏个根节点了,退化成一个大数组了,⽽一个磁盘块的⼤小也是有限制的,无法放下太多的记录;但也不能太小,当m=2时,就是一棵二叉树了;另外,一个节点里也不能太空,所以要求至少得有(⌈m/2⌉-1)个关键字,否则每个节点都只有一个关键字,这实质上又成了一棵二叉树了。
以下是一个3阶B树的实例图:
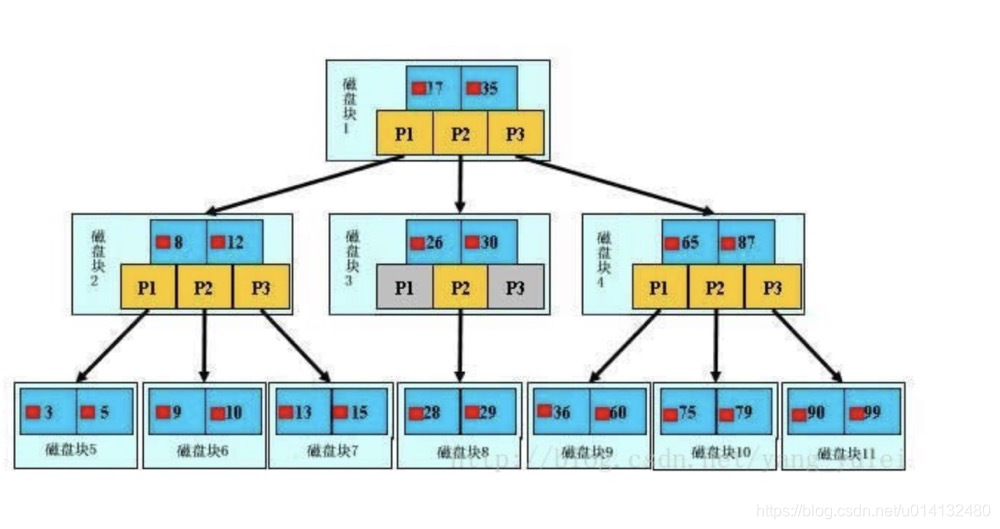
需要注意的是,B树中的每个节点都是⼀个磁盘块,在MySQL中称为一个page, ⼤小一般是16KB。每个节点中除了存储关键字外,还包含了其他的数据信息。换句话说,即B树中每个节点,除了包含索引列之外,还包含了其它列。
与上述的平衡二叉查找树⽐较,因为B树是多叉的,所以B树的高度会⽐二叉树低很多。通常在数据库中,B树的m值会大于100,甚⾄1000,这样,1亿条记录,构成的B树也就是3-4层。
另外,每个节点即⼀个磁盘块,存放了多条数据,一次I/O操作就可以把多条数据读取到内存中,从⽽减少了大量的随机I/O操作。
虽然B树解决了查找时磁盘IO的性能问题,但B树也有一些缺点:
1. B树的内部节点除了包含索引列外,也包含其他列,所以很难将整颗B树的内部节点都放在内存中,在查找时,如果要查找的记录不在内存中,那就需要进⾏I/O操作。
2. B树很难顺序遍历所有的节点,对于一些基于范围的查询,效率很低
3. 因为B树的特点(内部节点除了包含索引列外,也包含其他列),会导致即使逻辑上相近的记录,可能也会被存储在距离很远的节点上。
为了解决以上问题,B+树应运⽽生。
B+树
B+树是B树的一个变体,⼀颗m阶的B+树与B树的差异在: 非叶节点只保存关键字(索引列,索引信息),不包含其它数据(其他列列, 数据信息) 叶节点保存了所有的信息(所有的列),包括索引信息和数据信息。当然, 保存数据信息的⽅方法也有两种:
1) 直接在叶节点上保存;
2) 只保存一个指针,直接或间接指向真正存储数据的磁盘块。
叶节点⽤一个链表的形式连接起来
以下是⼀个4阶的B+树示例图:
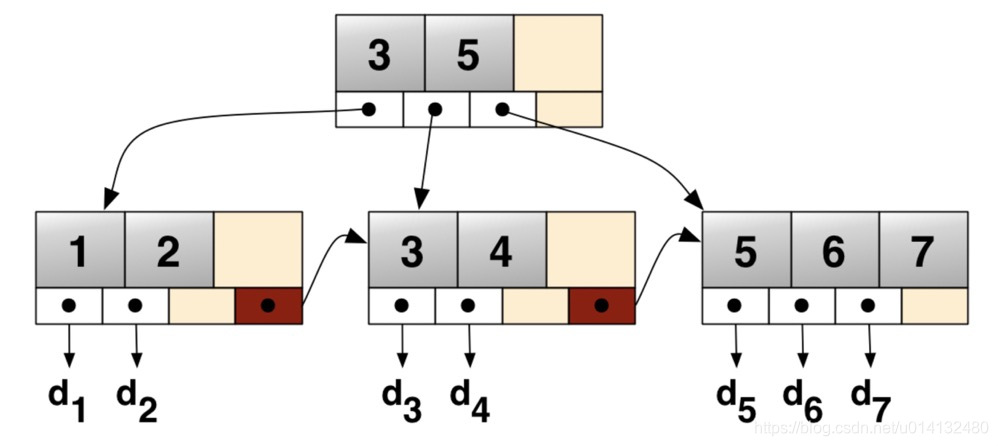
与B树相⽐,B+树的非叶节点仅仅起到了索引的作用,并不存储数据信息,所以B+树的索引节点更容易放在内存⾥,减少了硬盘的I/O操作。另外,因为B+树的索引节点不存储数据信息,所以一节点里允许的阶数m的最⼤值要比B树的更大, 这也有效的减少了B+树的高度。 更重要的是,因为叶节点之间是⼀个链表的结构,所以B+树允许从叶节点遍历所有的数据,特别适合数据库中基于范围的查询。
前⾯提到了一些B树和B+树的区别,令⼈人印象深刻的是B树中的每⼀个节点(包括非叶节点和叶子节点)都包括key和value,而B+树中只有叶节点才包含value。
那么,可以想象,在B树中,查找某个关键字,可能在⾮叶节点中就命中了;⽽在B+树中,只有在叶节点中才能命中。
因此,如果不注重范围查询的话,我们可以采⽤B树索引,并且将经常访问的元素提到离根节点更近的地方,这样,查询的效率将会⼤大提高。
问题:B+树的叶节点是顺序存储数据的么?很多⽂文章会说B+树的叶⼦子节点是按照物理顺序来存储数据的。但实际上,这是不 可能的,因为随着数据量的动态增加,叶子节点满了以后会分裂,如果按照物理顺序来存储数据,代价是⾮常大的——例如中间某个节点分裂成两个节点了,如果要一定保证物理理顺序,那么必须把该节点之后的所有数据的存储位置都往后挪。
所以,B+树的叶节点的存储通常只能是尽量保证物理理顺序——一⽅面,每个节点代表一个磁盘块,而多条数据都存放在同⼀个节点中;另⼀⽅面,相邻的叶节点也尽量是物理上相邻。
InnoDB中,B+树索引是最常⽤的索引。在InnoDB中创建一个B+树索引的SQL语句有:
1. Alter table t add index
2. create index on table t
3. 在create table中指定index
B+树索引可以分成聚集索引(clustered index)和⼆级索引(secondary index)。聚集索引和二级索引都是B+树索引,区别主要在于聚集索引中的叶节点存放了一整行的数据,⽽二级索引则存放了部分数据。
聚集索引
InnoDB的存储引擎表是索引组织表。什么意思?即是说表中的数据是按主键顺序来存放的,表的数据也是索引的⼀部分,存放在索引中的叶⼦节点中。
在这⾥,说⼀下InnoDB中表的主键:InnoDB中的每个表都有一个主键的,如果创建表时没有指定主键,InnoDB首先会尝试将表的非空唯一索引作为主键,如果没有合适的唯一索引,那么InnoDB会使⽤一个递增的隐藏字段作为表的主键。
主键的索引就是聚集索引,聚集的含义是指数据按顺序聚集在一块。很显然,⼀
个表中最多只有⼀个主键,也最多只有一个聚集索引。
因此,可以想象的是,如果是基于主键的排序查找(order by)和范围查询(⼤于/⼩于),速度非常快。
另外,也可以想象的是,如果插入新纪录时,记录的主键是递增的话,那么新纪录将记录在聚集索引中最后一个叶⼦节点上,如果最后⼀个叶子节点满了,那么新建⼀个新的叶子节点即可,不需要非常复杂的操作,并且因为叶子节点之间也是大概率按照物理顺序创建的,因此新记录写入硬盘时也大概率是顺序I/O。综上,插入操作也非常快。
所以,我们在写查询SQL的时候,要尽量使用主键字段作为查询条件。另外,插入新纪录时,也要尽量保证主键是递增的。
二级索引(辅助索引,非聚集索引)
二级索引也是一个B+树索引,但它的叶⼦节点不包含行记录的所有数据。叶节点中的索引⾏除了包含索引的key外,还包含了⾏的主键。通过⼆级索引查询数据时,⾸先根据二级索引找到对应的索引行,然后根据索引行中的主键去聚集索引中查找对应的⾏记录。
举例说,如果在一个⾼度为3的二级索引树中查找数据,那首先需要对这颗二级索引树查找3次,找到指定的主键,如果聚集索引树的⾼度也是3,那么还需要对聚集索引树进行3次查找,最终找到行数据所在的数据页。整个过程⼀共需要6次逻辑IO访问。
因为⼆级索引不影响数据的存储组织,所以⼀个表中可以有多个二级索引。
组合索引
组合索引即索引由多个列组成。
对于⼀个组合索引,需要记住的是:只有它的左前缀的列组合才能⽤于加速检索数据。假设表tbl_name有一个组合索引(col1, col2, col3),能起到索引作用的组合包括(col1), (col1, col2), (col1, col2, col3),⽽组合(col2), (col3), (col2,col3)则不能起作用。当然,组合(col1, col3)也能起到作⽤,但它所起的作用等价 于 (col1)。
某个列组合是否能起到索引作⽤,主要是看这些列能否在B+树上缩⼩检索节点的范围。什么意思?我们先看例子。假设表t中有⼀一个组合索引(a, b, c),那么该 组合索引的B+树简化后类似下图所示:
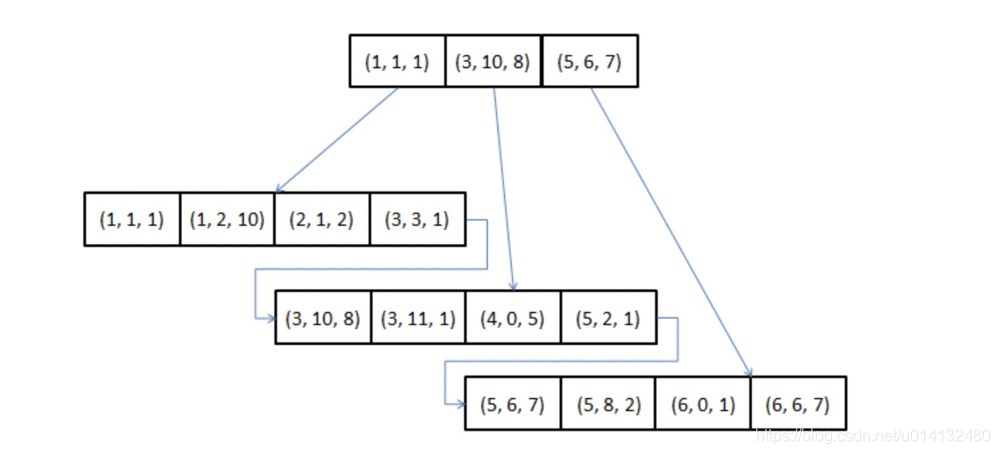
问题:以下哪些语句用到了索引(a, b, c)?如果⽤到了索引,那该语句⽤到了哪个列呢?
select * from t where a = val1;
select * from t where a = val1 and b = val2;
select * from t where a = val1 or b = val2;
select * from t where a = val1 or b <= val2;
select * from t where a = val1 and c = val3;
select * from t where a = val1 and b <= val2;
select * from t where a <= val1 and b >= val2;
select * from t where a = val1 and b <= val2 and c > val3;select * from t where b = val2;
select * from t where b = val2 and c = val3;
分析:
语句select * from t where a = val1; 等同于从区间 (val1, -inf, -inf) < (a, b, c) <(val1, +inf, +inf)中查询,可以缩小检索的节点数,所以该语句⽤到了索引,但只利用到了列a。
语句select * from t where a = val1 and b = val2; 等价于从区间 (val1, val2, -inf)< (a, b, c) < (val1, val2, +inf)中查询,利用到了列a和列b的信息。
语句select * from t where a = val1 or b = val2; ⽆法缩小查询的范围,即⽆法利用到索引
语句select * from t where a = val1 or b <= val2; 同样无法缩小查询的范围,即⽆法利用到索引
语句select * from t where a = val1 and c = val3; 等同于从区间 (val1, -inf, -inf)< (a, b, c) < (val1, +inf, +inf)中查询,利用到了列a的信息。这里需要注意,并没有利用到c的信息,因为列c相关的条件并没有缩小查询的区间。
语句select * from t where a = val1 and b <= val2; 等同于从区间(val1, -inf, -inf)< (a, b, c) < (val1, val2, +inf),利用到了列a和列b的信息。
语句 select * from t where a <= val1 and b >= val2; 等同于从区间(-inf, -inf, - inf) < (a, b, c) < (val1, +inf, +inf),利用到了列a的信息。这⾥需要注意,并没有利用到列b的信息,因为列b相关的条件并没有缩小查询的区间。
语句select * from t where a = val1 and b <= val2 and c > val3;等同于从区间 (val1, -inf, -inf) < (a, b, c) < (val1, val2, +inf),利用到了列a和列b的信息。这里需要注意,并没有利用到列c的信息,因为列c相关的条件并没有缩小查询的区间。
最后两个语句select * from t where b = val2;和select * from t where b = val2 and c = val3也很明显,⽆法缩小查询的范围,即⽆法利用到索引。
除了可以缩小数据查询的范围外,组合索引还有⼀个优势:当a确定时,b的值已经排序好了;当a和b都确定时,c的值也已经排序好了。这么一来,对某些需要排序的查询,省去了一次排序的过程。例如语句 select * from t where a = val1 order by b; 或者 select * from t where a = val1 and b = val2 order by c;,上述两个语句分别免去了一次b的排序和c的排序。
而对于 select * from t where a = val1 order by c;,就无法避免要对c进行排序。
结论:
如果发现业务中某个SQL的where或order by⼦句要⽤用到表的多个列,那么可以考虑在这些列上建⽴组合索引。
覆盖索引
覆盖索引,即从⼆级索引中就能查询的记录,不需要再次从聚集索引中查询。使用覆盖索引,不需要整行的信息,查询的结果完全从⼆级索引中获取,这就⼤大减少了IO操作,并且结果的⼤小也⼤大减小,所以查询速度非常快。
之前提过,⼆级索引中的叶⼦节点除了包含索引列的信息之外,还包含主键列的信息。假设⼆级索引的列是(key1, key2),主键是(pk1, pk2),那么以下的查询语句可以使用到覆盖索引:
select key2 from t where key1 = xxx;
select pk1, key2 from t where key1 = xxx;
select pk2, key2 from t where key1 = xxx;
select pk1, pk2, key2 from t where key1 = xxx;
另外,当查询语句是⽤来统计的话,也可以利用上覆盖索引:
select count(*) from t; (这个语句,会优先使用⼆级索引;没有的话,再使用聚集索引,即全表扫描)
select count(*) from t where key2 > xxx; (即使key2并非左前缀,但⼀样使⽤二级索引)
优化器选择不使用索引
当我们设置了⼀个二级索引后,并写出符合索引规范的查询语句,就一定能利用到索引么?答案是不一定的!当MySQL的查询优化器发现,通过⼆级索引,查找出的数据量很大时(例如占据了整个表行数的20%左右),优化器就会抛弃这个二级索引,转而使⽤聚集索引来扫描整个表。
为什么?
但如果数据库放在了SSD硬盘上呢?SSD硬盘的随机读写很快,而且经过测试,我们又确认了使⽤用二级索引可以带来更好的提升,那么我们可以通过关键字FORCE INDEX来强制优化器使⽤用指定的索引:
select * from user FORCE INDEX(mobile)
where mobileno > 13700000000 and mobileno < 13899999999;
索引条件下推(不常用)
要理理解索引条件下推(Index Condition Pushdown,ICP),⾸首先要明⽩白MySQL中的层次概念:
MySQL⼀般可以分成Server层和存储引擎层。
ICP的思想是:假设有⼀个列在⼆级索引中,并且在where子句中有与该列相关的条件,但这个列⼜不能⽤于索引数据,那么就把这个条件下推到存储引擎中,在存储引擎中,根据二级索引中存储的值排除掉不满⾜足here条件的行。
ICP的⽬的是减少⽆谓的IO操作。为加深理理解,分别描述一下关闭或打开ICP时,MySQL是如何扫描索引的:
1. 关闭ICP:
1) 存储引擎层通过索引,读取到符合索引条件的行,把整行的数据返回到Server层
2) 在Server层检查返回的⾏是否符合其余的where条件,如果不符合,抛弃它
2. 打开ICP:
1) 存储引擎层通过索引,读取到二级索引中的索引行(不是整⾏数据)
2) 存储引擎层检查where条件中属于⼆级索引一部分、但不能⽤于索引数据的列的相关条件:如果不符合,则直接抛弃该行,继⽽检查下⼀行
3) 如果符合,则根据该索引行读取到整⾏的数据,返回到Server层
4) 在Server层,再继续检查返回的行是否符合其余的where条件
如果某个查询语句使用ICP,则在explain时输出Using index condition
参考自:
http://blog.csdn.net/yang_yulei/article/details/26066409
http://blog.csdn.net/yang_yulei/article/details/26104921
https://en.wikipedia.org/wiki/B-tree http://www.differencebetween.info/difference-between-b-tree-and-b-plus- tree
http://stackoverflow.com/questions/870218/differences-between-b-trees- and-b-trees














 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









