







核心思想
现在要找一个直线,如何将这两个类最大限度的分开,直观的如果找一个投影法相,就像下面两个图,右边的结果更好:
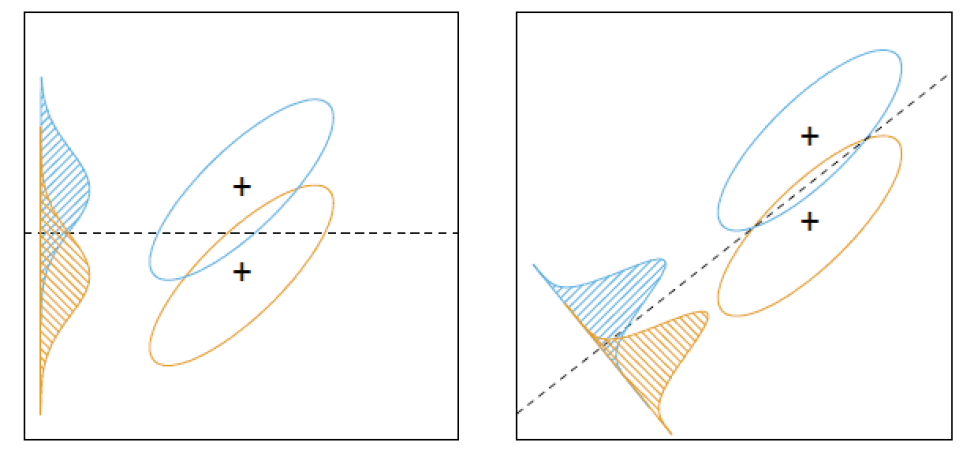
它阐述了一个怎样的准则:
类内最小
在一个类中来说,每一个样本要尽可能地靠近类地中心,类的中心在哪?
mi=1Ni∑xj∈Xi
现在要找一个直线,如何将这两个类最大限度的分开,直观的如果找一个投影法相,就像下面两个图,右边的结果更好:
它阐述了一个怎样的准则:
在一个类中来说,每一个样本要尽可能地靠近类地中心,类的中心在哪?
 9425
3万+
9425
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















