







要求:
写一个程序,分析一个文本文件(英文文本)中各个词出现的频率,并且把频率最高的10个词打印出来。
解决步骤:
1. 读取 txt 文本文件;
2. 统计文本中每个词出现的次数;
3. 进行排序,打印频率最高的10个词;
4. 将结果写入txt文件。
实现思路:
1. 利用输入流和输出流实现对文件内容的输入输出;
2. 将文件内容存入StringBuffer中;
3. 利用String的split()方法将字符串分隔,并将其存入数组中;
4. 遍历数组将其存入Map<String, Integer>中
5. 利用Collections的sort()方法对TreeMap的value进行排序(很多时候TreeMap是根据key的值来进行排序的,但是有时我们需要根据TreeMap的value来进行排序。对value排序我们就需要借助于Collections的sort(List<T> list, Comparator<? super T> c)方法,该方法根据指定比较器产生的顺序对指定列表进行排序。TreeMap默认是升序的,如果我们需要改变排序方式,则需要使用比较器:Comparator。Comparator可以对集合对象或者数组进行排序的比较器接口,实现该接口的public compare
(T o1,T o2)方法即可实现排序,该方法主要是根据第一个参数o1,小于、等于或者大于o2分别返回负整数、0或者正整数。但是有一个前提条件,那就是所有的元素都必须能够根据所提供的比较器来进行比较。)
编程语言 :
java
编译环境:
JDK 1.7 Eclipse 4.3
操作系统:Win7
体系结构:x86 32bit
测试文本 :
E:\java\test.txt 大小:637 KB (652,386 字节)
代码实现:
import java.io.*;
import java.util.*;
import java.util.Map.Entry;
public class CountOccurrenceOfWords {
public static void main(String[] args) {
long t1 = System.currentTimeMillis();
String s;
String fileName1 = "e:/java/test.txt";
String fileName2 = "e:/java/result.txt";
try {
BufferedReader br = new BufferedReader(new FileReader(fileName1));
BufferedWriter bw = new BufferedWriter(new FileWriter(fileName2));
StringBuffer sb = new StringBuffer();
//将文件内容存入StringBuffer中
while((s = br.readLine()) != null) {
sb.append(s);
}
String str = sb.toString().toLowerCase();
//分隔字符串并存入数组
String[] elements = str.split("[^a-zA-Z0-9]+");
int count = 0;
Map<String, Integer> myTreeMap = new TreeMap<String, Integer>();
//遍历数组将其存入Map<String, Integer>中
for(int i = 0; i < elements.length; i++) {
if(myTreeMap.containsKey(elements[i])) {
count = myTreeMap.get(elements[i]);
myTreeMap.put(elements[i], count + 1);
}
else {
myTreeMap.put(elements[i], 1);
}
}
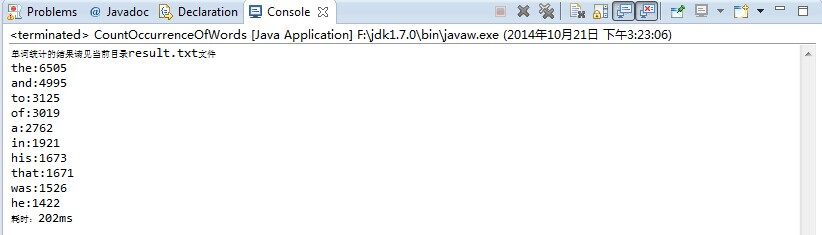
System.out.println("单词统计的结果请见当前目录result.txt文件");
//将map.entrySet()转换成list
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(myTreeMap.entrySet());
//通过比较器实现排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
//降序排序
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
return o2.getValue().compareTo(o1.getValue());
}
});
int num = 1;
//将结果写入文件
for(Map.Entry<String, Integer> map : list) {
if(num <= 10) {
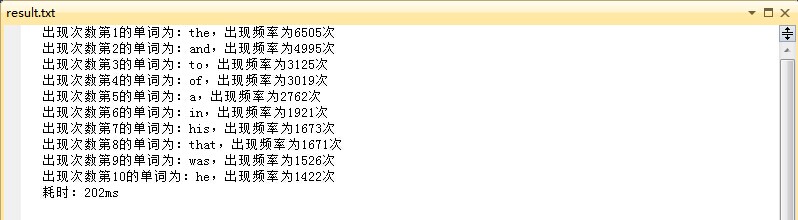
bw.write("出现次数第" + num + "的单词为:" + map.getKey() + ",出现频率为" + map.getValue() + "次");
bw.newLine();
System.out.println(map.getKey() + ":" + map.getValue());
num++;
}
else break;
}
bw.write("耗时:" + (System.currentTimeMillis() - t1) + "ms");
br.close();
bw.close();
System.out.println("耗时:" + (System.currentTimeMillis() - t1) + "ms");
} catch (FileNotFoundException e) {
System.out.println("找不到指定文件!");
} catch (IOException e) {
System.out.println("文件读取错误!");
}
}
}
性能测试:VisualVM
程序运行前:
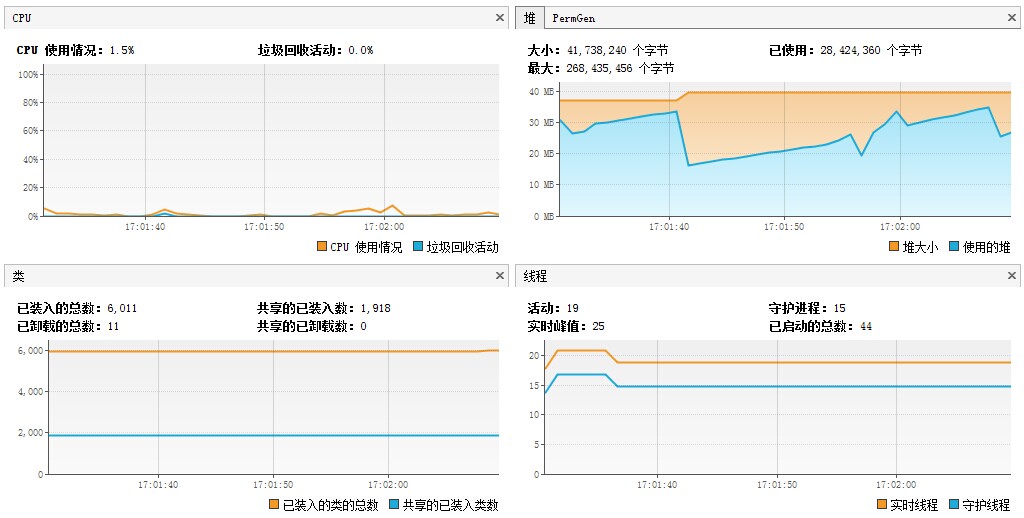
程序运行后:

心得:(1) 程序使用java正则表达式来分隔英文单词,若需要匹配所有的中文字符,就可以利用[\\u0041-\\u0056]形式(因为所有中文字符的Unicode值是连续的,只要找出所有中文字符中最小,最大的Unicode值,就可以利用这种形式来匹配所有的中文字符)。(2) 如果文本很大可以将文本分成多个小文本,采用多线程来处理文本文件。















 2253
2253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









