







一.提升方法boosting
如果我有写过集成方法的话[没有的话看这篇集成学习理论],集成方法的一大类就是boosting,其基本思想就是不断地在迭代过程中训练BaseModel,并增加误分样本的权重,直到达到停止条件后,组合BaseModel。从集成学习的理论我们知道boosting在组合过程中会增大模型的variance,所以BaseModel必须是低bias但低variance的弱模型,这样才不至于最终导致过拟合。
二.AdaBoost算法
上述的框架有两个基本问题,1)如何改变误分类样本的权重;2)如何组合BaseModel得到最终的分类器。AdaBoost回答了这个问题,所以AdaBoost是属于boosting的,但是AdaBoost没有指定BaseModel,所以其本质仍然是一个框架。
AdaBoost的工作流程如下:
1)初始化权值相同(都为1/N)的样本权值分布D1;
2)对m∈[1,M]:
a)使用权值分布Dm的训练集训练得到基本分类器;
b)更新权值分布,计算该基本分类器的加权权值(计算公式我不列出来了,可以去书中找~重点在于思想啊思想!)
3)组合(加权相加)得到最终的分类器。
三.AdaBoost原理解释
只想说每次看到给了一堆计算公式就会很想知道其内部的原因啊,我为什么要这么更新权重啊对吧,所以往下看!~
AdaBoost本质可以理解成模型为加法模型,损失函数为指数函数(策略为检验风险极小化),学习算法为前向分步算法的二类学习分类方法。
加法模型,指数函数什么的都好理解,但是问题来了,什么是前向分步算法呢?因为我们要优化的目标是加法模型,可以通过从前向后,每一步值优化一个基函数及其系数,来降低优化复杂度。其实有发现吗,前向分步算法本质是一个贪心算法呐~
通过这种方式,就可以得到第二部分的AdaBoost过程中具体的公式和求解方法啦~
延伸:
这时候我们就想啊,boosting一般都是加法模型加上前向分步算法,那么可以改变的就是损失函数了,所以其实根据损失函数的不同,会有不同名字/效果的算法,如下图:
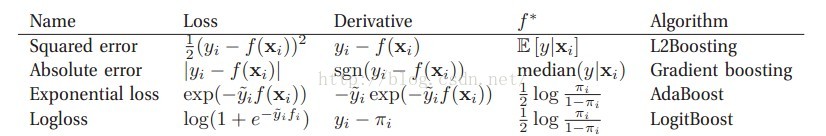
四.AdaBoost的误差分析
AdaBoost最基本的性质是它能在学习过程中不断减少训练误差。直观来看,每次提高误分类样本的权值,当然会减少训练误差啦(注意是训练误差),这也对应了上述提到的AdaBoost属于boosting方法,而boosting方法是会提高model的variance的,就是容易过拟合,这也很直观。
关于AdaBoost的训练误差界是以指数速率下降的,这也是有理论证明的。
【注:本文不写公式,为了更注重其理论思想(因为懒...),具体公式请参见<<统计学习方法>>】














 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









