







1.领域分析
1.1引言
随着信息时代的来临,基于PDF格式的学术论文与期刊文献的数量猛然增长,给科研人员提供了丰富的参考资料的同时,也迫使科研人员将更多的时间和精力投入到对科技文献的检索与阅读中。如何对文献进行有效筛选与管理,成为当前研究的关键性问题[1]。
本次课题所设计的引文集成辅助阅读系统利用的是一种线性阅读与非线性阅读结合的方式,针对的用户是缺乏完整的知识体系的本科生和研究生,通过线性阅读引导用户阅读的逻辑思维,而超文本阅读作为一种主要的非线性阅读方式,可以激发读者的联想思维,提高用户获取大量信息的可行性。
我们的系统目标是满足用户在阅读施引论文的同时希望能够阅读被引论文的需求,从而帮助提升用户的检索与阅读效率,减轻用户的认知负载问题,借助被引论文的阅读让用户理解施引文献变得更加轻松、简便。
1.2系统新颖性
1.2.1国内外研究现状
国内在辅助阅读系统上的研究相对较少,目前主要通过对文献进行信息抽取、自动标引、文本可视化技术等构建辅助阅读系统,达到帮助读者在海量文本信息中快速且准确地获取个人所需的信息、更好地理解所阅读的内容的目的。
国外关于文献辅助阅读系统的研究相对更加成熟,集中在在线协作、文本可视化技术、用户与系统的交互等方向,着重于对用户行为和动机的研究,以完善辅助阅读系统的用户体验,从而帮助用户投入到阅读文本中,快速理解文本。
因此,本文以参考文献辅助阅读系统、文献注释辅助阅读系统、文本可视化辅助阅读统为例探讨科研人员在进行这类辅助阅读系统开发的研究方法和思路。
(1)参考文献辅助阅读系统
文献的相关信息包括文献的题录信息、参考文献信息等。艾华等人[2]建立了一个基于 PDF 的文献管理软件,能帮助科研工作者者有效利用信息资源,检索、管理和阅读个人文献,从而形成完全个性化的知识环境。该系统通过对参考文献格式标准的确定以及文献题录信息的抽取,创建、管理、存储和输出个人用户的文献题录资料,极大的方便了用户的检索管理以及阅读研究。
Maria D. D. Collins和Christine L. Ferguson[3]探讨了使得链接服务成为可能的一种系统——CrossRef。CrossRef 不是一个商业信息数据库,也不是全文内容服务商,它是促成相关出版商联合协作,使用DOI 技术为相关人员与机构提供引用链接服务的系统。CrossRef 确保任何拥有DOI 标识的网络信息资源与其资源本身之间的有效链接,并确保该链接的持久性。CrossRef 的系统链接还具有内容可见性、链接协议集中化等特点。CrossRef可允许研究人员通过点击某个出版商平台中的一个参考文献引用条目来直接链接到另一出版商平台中的被引用内容。通过提高目标链接能力及链接的便捷性,提高目标内容的使用量,用户仅需点击鼠标,便可通过开放链接、按次付费等来获得全文从而进行阅读,使文献的检索和获取更简单、直接和高效,使得阅读过程更加连贯。目前,CrossRef的引用链接网络覆盖了来自数百家学术类与专业出版商的数百万份论文及其他文献目录。这一动态的学术信息平台使研究人员迅速获得相关研究课题的各种文献,促进研究人员对科研课题的全面了解,并为科研工作的顺利展开与高质量完成提供了切实的保障。
钟惠中[4]设计并构建了一个基于序列关联规则的科技文献自动辅助阅读系统。该系统通过抽取科技文献中的参考文献和作者姓名,可以自动检索作者名称和文献名称信息,并且它能在鼠标所指处,及时显示引用文献名称信息和作者名称。科技文献自动辅助阅读系统的文献名称识别方案基于语义框架结合规则,根据科技文献中的各种语义概念构建各个概念之间的联系从而构建整个框架。由于科技文献为半结构化的数据,系统结合规则和PDF文件中的非文本信息来提高抽取的准确率。在作者名称识别方面,根据科技文献特点与技术框架的限制,选择基于隐马尔可夫模型和轻量人名语料库的作者名识别方案。最终实现减少阅读过程中的额外动作,帮助科研人员提高科技文献阅读效率的目的。
(2)文献注释辅助阅读系统
Mendenhall & Anne[5]介绍了一个通过使用多种教学策略从而支持学生提高至关重要的批判性思维、写作能力及补充相关知识的一种在线学习系统——社会注释模式学习系统(SAM-LS),并探讨了该系统在促进本科生批判性思考能力以及阅读理解上的作用。社会注释模式学习系统将Web2.0工具如社交网络(例如Facebook、MySpace、Ning)的细微差别与更基本的可以在Microsoft Word或Adobe工具中进行评论的注释工具以及大量其他互联网可用应用程序相结合。其核心是HyLighter[6],一个将阅读和写作结合起来,促进共享、整合多个评论家注解的在线注释系统。HyLighter生成一个由颜色编码的综合显示,用于各种目的。HyLighter其中一个独特功能是彩色编码系统,可以创建一个或者多个读者文档阅读中知识轨迹的"累积的地图",用户可以选择一个人的"旅行",也可以和一个小组或一个专家的进行比较。小组成员可以使用社会注释模式学习系统突出重要的文本和电子文档,与他人在一个网络添加评论和分享注释。在完成对文本的高亮和笔记之后,用户可以选择一个关于评论和标签的表格视图,用户可以在很大程度上因此受益。其研究报告表明,SAM-LS能帮助读者坚持任务、更加投入到文本情境中,并且能促进理解能力和批判性思维。
国内相关研究人员迟海[7]设计了一个简易的中文专利辅助阅读系统,研究基于CRF工具包的自动抽取术语问题,通过对抽取出的术语文档进行处理,获得一个标注好的术语文档,并对其实现过程中涉及到基于中文分词处理的一系列算法以及数据结构等问题进行剖析。在该系统中,考虑到术语的模糊性和词库的庞大,对术语进行模糊匹配,系统先将术语处理成单个汉字再与词库做匹配处理,同时对其在对术语中的每一个字符都在词库中做一次检索,并对词库中的词条建立哈希索引,进行倒排查找。在判断字符在词库中的某条语料里是否连续出现时,考虑汉字与英文的区别,由于汉语词汇的后重性,则要从最后的字符向前来判断,找到相同的字符后,再判断其前一个位置的字符是否也相同,相同则记录器进行累加操作,即字符在词库中出现了几次,记录器便是几。并且考虑术语在语料中出现的连续性,其程度越高,显示的优先级就越高。同时把术语在词库中的哪条信息中出现过的位置分别记录下来进行存储,以方便下次查找。系统基于CRF工具包自动抽取术语,通过对术语的处理,使用对词库进行哈希索引、倒排查找和词语优先显示等方法,利用最大熵模型,解决了将专利中苦涩难懂的专业词汇转化成人们易懂的词语的问题,使读者轻而易举地了解专利的作用及其商业价值。
(3)文献可视化辅助阅读系统
文献进行文本可视化的目的是以丰富的图形或图像揭示以文本为载体的信息内容。文本的可视化技术可以高度概括并且形象化表示文本信息中的核心内容,方便人们快速的理解和吸收文本中的核心思想。
在该研究领域,从检索到的文献数量以及内容质量来看,国外研究水平是要稍领先于国内研究的。根据不同的应用目的,文献可视化可以总结为基于词汇的文本可视化、基于篇章内容的文本可视化、基于时间序列的文本可视化和基于主题领域的文本可视化[8]。
Jozef Stefan研究院知识技术部门开发的Contexter系统[9]即是一种典型的基于命名实体的可视化辅助阅读系统。该系统首先利用信息抽取方法发现特定的命名实体,这些命名实体就是需要呈现的特定词汇。在此基础上,系统建立了命名实体之间的共现关系。其可视化的内容主要包含以下两个方面:①以网络图的形式表现实体之间的共现关系;②反映实体之间的背景信息,包括:命名实体相关的关键词、相关的其他命名实体、以及根据选定命名实体和其相关命名实体共同计算出的出现频次较高的特定关键词。Contexter系统会首先将处理完成的语料,以命名实体、词袋、原始文本等3种形式存储在数据库之中。词袋中包含原始文本的大多数词语,只是去掉了其中的停用词,并且做了共指消解的处理。利用词袋的目的,主要是为了全面地覆盖原始文本中的背景信息。利用一些特定的算法(典型的有TF-IDF算法),判断出文章中的关键词,从而建立命名实体与关键词的联系,帮助读者理解命名实体之间语义关系。
此外,国外在该领域的研究成果还有基于词汇分布的可视化系统——Tilebares[10]、词汇分布的可视化系统——NLPW in[11]、发现阅读线索的篇章内容可视化系统——TextArc[12]、主题变迁可视化系统——ThemeRiver[13]、内容变迁可视化系统——History Flow[14]等。
国内研究中,陆泉、陈静和jin zhang[15]开发了PDF图书可视化交互挖掘系统——电子图书多粒度内容解析系统。其目的是深化图书检索粒度,以及提升图书检索用户体验与降低认知负担。基于该系统,通过对电子图书进行多粒度逻辑结构的解析与特征词权重计算,进一步对图书全文、其逻辑组织以及检索结果进行可视化。利用其对电子图书的处理结果,提取其建立的图书页面、逻辑单元、具体文本之间的对应关系,实现逻辑层次树、可视化空间与图书原文之间的同步操作。用户在逻辑树上任一节点或可视化空间任一对象上的操作,将得到原文、逻辑树与可视化三个窗口的同步响应。
综合国内外研究可以发现,国外研究水平要高于国内研究,此外在文献辅助阅读方面,研究人员主要集中于研究文献可视化以达到辅助阅读的目的。而基于引文文献,利用文献引文相关信息(包括文献摘要、被引情况以及影响因子等相关信息)作为辅助阅读的系统研究较少,具有很大的研究空间。
1.2.2国内应用现状
本节内容,作者从不同角度选用了几款主流的阅读系统进行比较分析,分别是CajViewer、Adobe Reader和ReadCube。以上三种阅读软件均支持Windows、Mac、IOS、Androoid等主流操作系统。此外,国内研究人员在移动平台上进行PDF文献阅读时,可能还会用到iBooks、福昕阅读器、Good Reader、多看阅读、手机知网、PDF Reader、PDF expert等软件,由于与上述三种阅读器相类似,或只支持某一种系统使用未成为主流,故在这里不做详细介绍。
1.2.2.1国内主流文献阅读系统介绍
(1)CajViewer
CAJViewer又称为CAJ浏览器,是由中国知网自主开发,用于阅读和编辑CNKI系列数据库文献的专用浏览器。CNKI一直以市场需求为导向,每一版本的CAJViewer都是经过长期需求调查,充分吸取市场上各种同类主流产品的优点研究设计而成。它兼容CNKI格式和PDF格式文档,可不需下载直接在线阅读原文,也可以阅读下载后的CNKI系列文献全文,界面清晰,功能强大,使用简易,逐渐成为人们查阅学术文献不可或缺的阅读工具。
(2)Adobe Reader
Adobe Reader是由美国Adobe Systems所开发的电子文字处理软件集,可用于阅读、编辑、管理和共享PDF格式文件,文档的撰写者可以向任何人分发自己制作(通过Adobe Acobat制作)的PDF文档而不用担心被恶意篡改。它适用于跨平台和跨设备可靠地查看 PDF 文档并与之交互,保护功能非常强大,是一款值得信赖的、业界领先的阅读器。
(3)ReadCube
ReadCube 是一个用于阅读、管理、注释、获取学术文献的专业文献阅读管理系统。 ReadCube团队把它定位为用于替代现有科研文献管理软件,但实际上它的文件传输和引用功能,以及个性化的推荐功能都是非常有价值的。并且,它可以通过谷歌学术搜索(Google Scholar)、PubMed 和微软学术搜索(Microsoft Academic)来查找和下载文章。它同时具有强大的文献阅读和组织功能,这足以让它在文献管理软件市场中占据一定的份额。
1.2.2.2主流文献阅读系统调研
CajViewer、Adobe Reader、ReadCube分别作为国内知名文献阅读系统、世界领先文档阅读系统、国外优秀文献阅读管理系统的代表,为文献辅助阅读系统的发展发挥着一定的影响力。接下来从用户数量和功能对比两个方面,对CajViewer、Adobe Reader、ReadCube进行调研,探讨主流文献系统的应用现状。
(1)用户数量对比
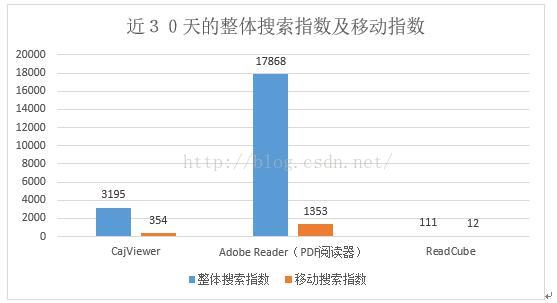
备注:搜索指数是以网民在百度的搜索量为数据基础,以关键词为统计对象,科学分析并计算出各个关键词在百度网页搜索中搜索频次的加权和。根据搜索来源的不同,搜索指数分别PC搜索指数和移动搜索指数。整体搜索指数为PC搜索指数和移动搜索指数的和。
由上表可得,就近30天的整体搜索指数及移动指数而言,Adobe Reader的指数最高,其次是CajViewer,ReadCube最低。Adobe Reader的整体指数达到17868,移动指数为1353,它的搜索热度最高,这与它注重用户习惯有关;CajViewer其次,整体指数为3195,移动指数为354,比较受欢迎,这离不开它作为中国知网专用浏览器的身份;ReadCube最低,整体指数为111,移动指数仅12,这表明在中国ReadCube的覆盖面并不广,国内的认可度较低,这与它对中文文献兼容性较差、宣传不足有关。
总的来说,Adobe Reader和CajViewer在国内的受欢迎度很高,可以为本系统界面、结构等方面的设计提供参考。而截止2015年3月,ReadCube阅读平台的全球用户数量超过800万人,在世界上有着巨大的影响力。与国内的使用情况对比表明,此类提供超链接的个性化推荐文献阅读系统在国内市场存在严重的短缺。
从整体搜索指数和移动指数的对比可以得出,在移动设备上的搜索所占搜索比例非常小,这是由于三款文献阅读系统对移动设备的支持性较差,也与用户阅读文献习惯使用较大屏幕有关,这也是文献阅读系统多为PC端的原因,我们开发的系统也是基于Windows PC端。
并且,通过百度指数提供的人群分布情况,可以得出:20-39岁的人群为CajViewer和Adobe Reader的主力军,其次为40-49岁。地域分布表明在北京、江苏、广东、浙江、上海、湖北等省份使用CajViewer、Adobe Reader和ReadCube的用户最多。可见,文献阅读活动在发达地区最为活跃,表明发达地区的科学研究工作更为普遍深入。这预示着本系统的面向用户主力群体在20-39岁,在较发达地区更倾向被使用。
1.2.2.3文献阅读系统功能对比
根据我们小组对CajViewer、Adobe Reader、ReadCube这三款软件的实际使用情况可得下表:
| 名称 | CajViewer | Adobe Reader | ReadCube | |
| 适 用 环 境 | 适用系统 | Windows,Mac,IOS,Android | Windows,Mac,IOS,Android | Windows,Mac,IOS,Android |
| 支持格式 | CAJ、NH、KDH、CAS、CAA和PDF | | | |
|
基 本 功 能 | 缩放 | √ | √ | √ |
| 复制 | √ | √ | √ | |
| 快照 | √ | √ | √ | |
| 注释 | √ | ★(可对注释进行排序、筛选及查找等) | √ | |
| 图画标记 | √ | ★(提供多样的图画形状并可自行绘制) | × | |
| 文本编辑 | ★(可添加高亮、知识元链接等) | ★(可添加附件、录音、高亮等) | √ | |
|
特 色 功 能 | 目录 | √ | √ | × |
| 书签 | √ | × | × | |
| 页面跳转 | √ | ★(含页面缩略图) | × | |
| 参考文献链接 | × | × | √ | |
| 作者信息链接 | × | × | √ | |
| 社交网站分享 | × | × | √ | |
| 期刊网站链接 | √ | × | × | |
| 相关文献推荐 | × | × | ★ | |
| 内容查找 | √(支持在选择的范围内查找) | √(支持在选择的范围内查找,可设置查找条件) | √ | |
| 在线搜索 | √(支持在CNKI和工具书集锦在线中搜索) | × | ★(可按作者期刊题名等在Google、 Schoolar、PubMed上进行搜索) | |
| 划词链接 | √ | × | × | |
说明:★特色;√ 支持;× 不支持(参考"人人都是产品经理"网站给出的竞品分析标准)
通过对以上三大主流文献阅读系统的对比,可以发现,CajViewer是一款功能强大、旨在为用户提供方便快捷、注重检索的文献阅读器。它的基本功能诸如文本编辑、标记、注释都十分完备,在目录、书签等细节上也毫不逊色。依托中国知网的平台提供即时的在线检索,帮助用户理解文献内容,从而起到辅助阅读的作用。Adobe Reader是一款界面十分友好的小而美的阅读器。它的功能较少,但每一个功能都细化到了极致,能充分满足用户对文献的基本操作要求,极其看重用户的视觉体验,导航也十分清晰,以创造完美的用户体验为目的,可以有效辅助用户进行文献内容的阅读和组织。Readcube则是定位于搜索、引用、组织和推荐文献的一款个性化文献阅读系统。通过对引文的处理,以链接的方式提供给用户引文文献和作者的信息,通过Google Schoolar等平台提供文献的查找与下载,并且可以提供个性化推荐,真正意义上从引文和个性化的角度出发对用户进行辅助阅读。但它的编辑功能较弱,系统的稳定性有待改善。
1.2.3文献阅读系统分析总结
从文献辅助阅读的科学研究领域来看,大部分研究者倾向于通过对文献的一些基本信息如题录、摘要,或者对文献内容进行解释以及将文献内容可视化的角度来帮助用户进行辅助的阅读。
而主流文献阅读软件在基本功能方面均日益完善和趋同,而能够在市场上流行起来的主流文献阅读软件都存在一些其他软件难以替代的特色功能,这也是其能存在一批固定用户的基础。
总体而言,目前文献管理软件仍存在以下的不足:现有文献阅读系统更加注重对于文献内容的阅读格式,包括缩放、文本编辑等基本功能,而对于文献中的引文信息则显得重视不足。事实上,引文信息能够帮助用户进行文献筛选、理解等多种目标,利用文献引文相关信息(包括文献摘要、被引情况以及影响因子等信息)作为辅助阅读因素的系统具有新颖性。
1.3系统价值性
1.3.1用户相关评论
本小节内容将会摘取一些社会问答社区如知乎、或一些科研人员常用网站如科学网、小木虫等网站的用户回答或者评论,以直接或间接的方式来证明存在用户需要引文信息来帮助其进行阅读或者科研任务完成。
在知乎社区中,存在一个"如何总结和整理学术文献"的话题[16],该问题获得了8000余人的关注,在点赞数较高的答案存在一些这样的内容:
用户"menz"提到内容中出现:"xxxxx[11]"。我希望马上看看这个参考文献[11]是什么。pdf版太烦了——要拖下去找这个参考文献[11],然后再滚上来,忘了刚刚看到哪了。这点(大部分文献的)网页版就很好,鼠标虚指一下[11]这个链接,参考文献的citation信息就显示出来,再点一下,直接就可以打开这个参考文献的页面;
用户"雷泽"提到论文中引用文献时,一般的方法也就是在文中给出类似[1]的引用号,文章末尾列入参考文献等内容,真正的交叉引用效果都不太令人满意,那么也就很难将引用内容与参考文献灵活联系起来。但此时如果有一种方法,在不需翻页的情况下,在论文引用处可以链接到引用文档的信息,比如作者,题目,页码,出版社,甚至链接到pdf文档供一键打开,那就是无穷的方便。
同时,在知乎上也存在着另外一个话题"参考文献有网页链接,是不是用户体验更好?"[17]用户"徐编辑"提到有链接确实减少了阅读者的负担,而有匿名用户则回答道现在也没有专门的阅读器可以在文献里提供链接直接查询文章,但国外有文献管理工具比如readcube可以实现作者信息的链接,希望以后能有专门的文献内部参考文献链接技术和服务出现吧。
同样,在科研人员聚集的一些网络社区中如科学网用户"英论阁Enago"[18]提到在最近的一次发表论文的过程中,期刊编辑希望其发稿能对自己的参考文献附上超链接,理由是此工作能帮助读者进行更有效的阅读。
从上面的评论可以总结出下列观点:科研相关人员的确需要一款在阅读器中提供在被引处直接能给出相关信息以辅助他们进行阅读,而目前还未真正出现一款能够满足这些功能的阅读系统。
1.3.2目标用户人群分析
对于我们所构建的系统面对的用户需要满足以下几个特点:1、用户在日常生活中有进行阅读文献或者论文写作的需求;2、在阅读某领域文献的过程中,对施引文献感兴趣,即其希望能够理解文献内容包括引文所蕴含的信息或者了解更完备的该领域相关知识以加深对其认识。
据此,我们将目标用户人群分为两类,一类是对本专业领域知识还缺乏完整体系的本科生和研究生;另一类为带有特定任务或特定动机的科研相关人员。
1.3.2.1缺乏完整知识体系的本科生和研究生
对于本科生和研究生来说,文献阅读是其学习生活中的重要组成部分,并且在学习生活中也大都是在阅读本专业领域方面的文献。在其学习期间,需要通过广泛而深入的阅读、大量的知识积累和研究训练,构建合理的知识结构,以增强学术能力和适应性。由于该类型用户并没有广泛而深入的一定量的阅读,因此在进行科学研究时其没有宽厚的理论基础和一定量的学术积累。
虽然该类型用户未形成完整知识体系,但此类型用户具有一定的先验背景知识。先验背景知识(prior background knowledge)是指阅读者拥有的与阅读文本内容有关的所有背景知识的总体,它包括领域知识与主题知识。领域知识(domain knowledge)表征知识的广度与范围,是指与某一特定学科有关的并能将此学科知识体与彼学科知识体区分开来的基本原理与概念;主题知识(topic knowledge)表征知识的深度,由领域知识内的某些子概念与子观点构成[19]。
(1)从先验背景知识和兴趣之间的关系分析
Alexander发现在技术性物理学文本阅读中,领域知识与兴趣具有显著性相关,而在另一篇同类非技术性文本的阅读中,领域、话题知识与兴趣有显著性的相关[20]。Schraw与Wade都发现信息的完整性(由文本所提供的阅读中的必要背景信息)与情境兴趣间有着积极的关系。[21, 22]
此外,Tobias(1992a)指出:认为领域知识与兴趣无关的论断是不合理的。因为如果人们对某一领域非常感兴趣,则可能会主动探寻以获得此领域的更多知识,并且也愿意在此领域中花费更多的时间来学习,因此兴趣所引起的学习结果变异中必然有部分应归功于领域知识的作用。[23]
综上所述,许多学者关于先前背景知识与兴趣的研究中,均发现先前背景知识与兴趣具有显著性相关,即先前背景知识能明显促进用户进行阅读的兴趣。
(2)从先验背景知识和阅读理解的关系分析
阅读理解是学生获取知识和信息的一个有效途径。图式理论认为,理解的产生离不开图式,因图式早已存在,且以知识结构的形式存储于大脑中,所以,当文章中的信息与已存在的知识结构(图式)发生映射的时候,理解也就产生;已有知识是理解产生的基础,通过已有知识,阅读内容可以被预知,且这样的过程由读者驱动;背景知识为理解得以产生提供了其所需的导引语境,而语境则帮助读者筛选阅读中输入的信息并最终帮助读者理解其所读内容。[24, 25, 26]
此外,在阅读理解的过程中,兴趣也明显对阅读理解有着明显的正向促进作用[27]。我国学者章凯、张必隐在以大学生为被试的研究中,以兴趣的自组织目标-信息理论为基础,融合个体兴趣与情境兴趣的四个维度,提出兴趣发生的四维模型,其研究也再次表明:兴趣高的读者对所读内容表现出更强的推理能力、更高的元认知水平,并且兴趣对文章理解的促进作用相对独立于背景知识的影响[28]。Schiefele[29]进行了一系列研究来考察话题兴趣在文本阅读中的重要作用,系列实验表明高兴趣激发了阅读中更高水平的积极活动和情感方面的体验,并且高兴趣水平的个体进行的是一种更精细的信息加工并能主动运用学习的技能。
综上所述,存在一定的先验背景知识是用户在阅读过程进行理解的必要条件,同时有(1)已知,先验背景知识能够正向促进读者的阅读兴趣,而兴趣则能激发读者的热情,促进用户运用学习等技能去理解文章。
从以上两个角度可以总结道,对于缺乏完整知识体系的本科生和研究生而言,由于在日常生活中经常阅读本专业领域相关文献或者进行本专业领域的文献写作,并且该类型用户拥有一定的先验背景知识,他们会在阅读过程中产生对专业领域更深层的领域知识产生兴趣,他们也希望能够理解正在阅读的文献;因此其符合系统面向用户所具备的两个特征,是该系统的目标用户人群。
对该类型用户进行分析可得,目前仍存在下列问题[30]:
(1)阅读量不够。是否拥有足够的阅读量与研究进展及阅读能力的提示关联极大。尤其在研究生教育阶段,我国研究生在文献阅读上时间及阅读数量是偏低的,很多研究生仅仅局限于课本、教材,对本专业的学术渊源和前沿不去做了解和涉猎;另一方面,不愿过多了解相关学科知识,也导致了其学术视野狭窄和学术科研能力的不足。
(2)从文献中获取有效信息的能力不足。
第一、缺乏系统的文献检索能力。我国在本科及研究生教育过程中,缺乏对文献检索和查阅方面知识的系统培养。即便在检索资源丰富的条件下也很少有研究生对文献检索方法和知识作深入的了解。
第二、缺乏整理文献资料及准确理解的能力。能否从众多的文献中遴选出有效的信息,对研究过程来说至关重要。准确无误地理解文献,一方面是治学态度严谨的表现,另一方面也是科研人员阅读能力的重要标志。而实际学习中在浩渺文献中不知哪些该略读或者精读,对文献理解也缺乏准确性,学生在文献使用过程中断章取义的现象并不少见。
(3)缺乏阅读自主性。我国当前,大学生的阅读多处在一种被动的状态,很少有研究生能将文献阅读内化为研究生生活的重要工程部分,从而主动广泛而深入地阅读文献的。大多学生处于被动状态,不够主动而深入、广泛地阅读,自主地涉猎相关知识的,阅读上缺乏规划性和目的性。
因此,通过文献摘要辅助引导,可以让此类用户通过摘要带动深入学习、探究的兴趣,对值得精读的领域知识有更加清晰的思维框架,提高阅读效率,优化阅读策略。
1.3.2.2特定任务或特定动机的科研学习相关人员
该类型用户同样需要满足上述两个条件,因此包括了跨学科研究的科研人员,为显示自己非常勤奋的学生,为说服读者、显示作品权威与可信的科研人员等;这几种用户都需要用到引文,并且需要对引文所蕴含的内容具有阅读和使用意愿。
对于第一类跨学科研究的科研人员,虽然其并不具备跨学科的背景知识,不能保证其对该领域能产生兴趣,但其在科研过程中由于进行跨学科研究,该类人员必须要要理解文献内容以及文章中一些被引文献,该类型用户拥有特定任务。
对于第二类为了显示自己非常勤奋的学生,Harwood 和 Petric [31]对两名商学院研究生的课程论文写作过程进行了参与式观察,研究发现:不管任课教师开出的阅读清单上的文献对自己论文的内容有没有参考价值,学生都会引用这些清单上的文献。因为,他们认为这种引用可以向任课教师显示他们已经认真学习过所布置的阅读材料;此外,为了显示自己是阅读广泛的勤奋学生,每个学生都倾向于引用大量的参考文献,尽管他们并没有真正细读过这些文献。此类用户对被引文献虽不是完全想要真正理解,但其希望能够引用更多引文,对引文内容有一定的需求,该类型用户拥有特定动机。
对于第三类为说服读者、显示作品权威与可信的科研人员,Case[32]在传播学和文献计量学两个领域展开实证研究,发现传播学学者倾向于引用综述和熟人的文章,引用动机为:应用该文献有利于增强作者自己研究成果的权威性;布达佩斯大学的Vinkler[33]将作者的多种引用动机归为两大类:专业动机(Professional Motivations)和关系动机(Connectional Motivations)。专业动机主要是指由于理论或实践上的内容联系导致作者的引用行为,关系动机是指作者为了和学术共同体建立起社会联系而进行的引用。
此类用户对引文内容有较高的需求,并通常引用较为权威的作者的文献,以求与其建立社会联系、成为科研共同体,该类型用户拥有特定动机。
因此,通过文献引文辅助引导,可以让这三类用户通过摘要提高阅读效率,帮助其快速筛选被引文献价值,对有价值的文献进行详细阅读,优化阅读策略,以此满足其特定动机或促进其完成特定任务。
1.3.2.3从引文功能分析目标用户
结合日常阅读情景,我们可以知道,对于用户来说,阅读文献肯定不会也没有必要对所有参考文献进行依次阅读,因此可以预测用户只会想要了解该文献中某些参考文献所蕴含的信息。这意味着由于某些参考文献本身所带来的价值和功能吸引了用户想要对被引文献进行了解。
Oppenheim[34]以物理学和物理化学领域23篇高被引文献为样本,这些文献在1974-75总共被978篇文献引用。通过内容分析研究发现,提供研究背景(436篇)和相关研究信息(206篇)的非实质性引用,占施引文献总数的65.64%,将自己的研究结果与被引文献对比(141篇)、借鉴被引文献的理论(174篇)或研究方法(121篇)的实质性引用仅占施引文献总数的44.58%。
Pefitz[35]在社会科学领域内开展了一次跨学科的研究,通过对The American Journal of Sociology、The American Journal of Epidemiology、The American Journal of Educational Research、Demography、Library Research五份期刊中实证论文的引文内容分析,研究发现承担情境铺垫和提供背景信息功能的引文占总数的43.48%,而且将近半数的引文出现在引言部分,施引文献和被引文献之间并没有实质性的知识借鉴产生。
刘宇、李武等人[36]通过对相关实证研究的梳理,我们不难发现引文内容分析存在两大共性:一、大部分的引文主要是为了向读者提供研究背景信息,或罗列现有的相关研究成果;二、基于内容的实质性引用关系(通过概念借鉴和方法借鉴的建立引用关系)。
从以上实例我们分析得到:
1.若是对本专业领域知识还缺乏完整体系的本科生和研究生,在阅读过程中可能对关于提供背景信息或相关研究信息和借鉴被引文献的理论与研究方法的被引文献感兴趣;
2.对于跨学科研究的科研人员等则对于被引文献的研究方法、研究思路更感兴趣;
3.对于为了显示自己非常勤奋的学生,可能对研究结果或者结论的施引文献感兴趣;
4.对于为说服读者、显示作品权威与可信的科研人员,可能会对施引文献的作者信息或者所发表期刊知名度等更为看重。
具体情况如下表所示:
用户与主要五种引文功能的兴趣匹配情况
| 用户 | 研究背景 | 相关研究信息 | 研究结果对比 | 理论借鉴 | 研究方法借鉴 |
| 缺乏完整体系的本科生和研究生 | √ | √ | √ | √ | |
| 跨学科研究人员 | √ | √ | |||
| 显示自己勤奋的学生 | √ | √ | √ | √ | |
| 为显示作品权威的科研人员 | √ | √ | √ |
1.3.3阅读方式结合的价值
1.3.3.1超文本阅读简介
超文本是文本的电子表现形式,它将文本材料划分成多个线性单元(称为"节点"),然后按语义关系和特定的结构形式将所有节点链接成网络,人们轻击超链接就可以从一个网页任意跳转到另一个网页,即通过链接的方式将各种文本组织起来[37,38]。卜丽娜指出,超文本是用超链接将各种不同时间、空间的文字、图像、声音等信息组织成网状文本[39]。
超文本阅读使读者可以通过链接获得多样化的说明,特别是利用网络的漫游特性、下载功能、资源检索等服务扩展信息来源,进而开阔读者眼界[40]。目前,超文本 Hypertext 已经成为多媒体教育、现代远程教育、电子商务、计算机支持协作工作(Computer Supported Cooperative Work)以及其它信息通讯技术的重要信息结构基础[38]。
1.3.3.2与传统线性文本的对比
传统的文本课文是按顺序组织信息的,阅读时人们的思维往往只能随课文内容顺序展开,因此被称为线性阅读(Linear Reading)。这种信息组织方式不仅会限制读者的思维流向而且难以对大型信息系统进行有效地组织[38]。相比之下,超文本采用一种网状结构组织信息,由信息节点和联线组成。节点间通过联线彼此相互联系,读者可以顺着联线在超文本信息网络中自由移动[41]这种设计符合人类的联想思维特征,具有灵活组织信息和超强存贮信息的特点,不仅极大地方便了用户的阅读,提高了学习效率,而且容易引起学习兴趣。
超文本阅读的特点表现为:灵活性、非线性和随机通达性[42]。超文本的灵活性是显而易见的,超链接把知识有机地联系在一起,学习者可以顺着这些链接寻找自己需要的知识。超文本的链接也使它不局限于前后翻页式的线性操作,它可以在不同的页面之间来回跳转。由于有了知识点之间的超链接,同一信息可以由不同的路径得到,这种接近信息的方式不是先前决定的,它近似于随机,学习者可以根据自己对知识点的掌握情况选择通达的道路。
Jonassen [43]认为,超文本可以适应读者的先前知识( prior knowledge) ,是一种非常好的学习形式。学习就是通过习得新的概念和构建概念间的新关系从而逐渐改变知识结构的过程,因此读者预先所知的信息为构建新知识提供了框架。如果文本结构与读者的先前知识结构相似,那么就增进了学习。在这个意义上,读者在进行超文本阅读时可以根据自己的需求改变文本结构,因此这种阅读方式符合读者的内在语义网络。
吴骏[44]对超文本有图、超文本无图、线性文本有图、线性文本无图的阅读效果,进行了实证比较研究,发现超文本阅读明显优于传统线性文本阅读,并指出,超文本阅读应当科学的应用在教学及企业实践中。超文本网络还具有强大的数据存贮能力,超文本已成为互联网的重要信息结构基础,广泛地应用于现代远程教育、电子商务和其它数据通讯场合。
1.3.3.3超文本阅读方式的局限性
由于超文本阅读固有的灵活性,一方面,学习者通过这一灵活的文本组织形式构建适合自身的知识结构,从而对阅读内容有更加深刻的理解;另一方面,超文本这种近似随机的阅读方式以及让人眼花缭乱的链接,很可能导致学习者的迷失,从而对阅读效果产生不利影响[41];用户会在浏览超文本时很有可能偏离原有主题,在层级复杂的链接中产生迷航(迷路)[40]。迷路是指用户在游览信息网络时,不知道自己身处何处,如何达到目的地,或者在游览时因多次跳转而偏离学习(或搜索)主题[38]。
根据认知负荷理论,和传统文本相比,学习者在超文本阅读中面临更多的认知任务,从而增加了认知负担。由于一个节点会与多个节点链接,使用户难以知道要选择哪条路径;节点之间的关系存在疏密的差别,也会增加认知负担[41]。同时,用户为了保证特定搜索与目标相关信息,又要抑制自己感兴趣而无关的信息,大大增加了心理负荷[40]。当用户的游览目标不很清晰时,所承受的认知压力更为严重,阅读效果因而受到影响[38]。
在超文本阅读中,学习者需要明确学习目标、制定学习计划、掌控学习界面、监控阅读进程,必然会增加学习者的认知负荷,导致如迷航、认知过载等各种问题的出现[40]。
1.3.3.4线性与非线性方式结合的价值
虽然超文本设计符合联想思维的特征,但信息的最终获取还需通过阅读线性文档,即各结点的内容来实现。有研究发现爱好线性阅读还是非线性阅读存在明显的个体差异,即一些人更多地依靠线性阅读来获取知识,而另一些人却更多地依靠非线性阅读来积累知识[38]。本研究旨在有效地结合线性文档与非线性文档,提高不同用户的个性阅读效率。
在阅读的过程中,插入特别提示[45]要求读者进行深度加工,能够有效地激发读者的元认知监测,从而辅助阅读。研究如何给用户清楚的提示和强调(需求分析),避免兴趣过于泛化和注意不稳定,对于提高阅读效率是十分有益的。
在保证线性阅读文献的大前提下,借鉴超文本阅读模式,对参考文献提供基础信息的阅读辅助,既可以帮助用户理解引用内容,与已有知识进行整合,形成对文献更好的整体把握;又避免了迷航与认知负载问题的产生。另外,超文本学习环境可以很好地实现随机通达教学,提高结构不良领域认知灵活性[41],即提高跨领域阅读效率。
1.4系统可行性
1.4.1时间可行性
本次系统开发将严格按照陆泉老师制定的信息系统设计与开发教学日历执行,第5周提交领域分析报告,第6周进行小组需求分析报告,第8周进行小组系统设计报告,第11周进行小组系统开发报告,第13周进行小组系统测试报告,第15周进行小组系统评价报告,第18周进行小组总体报告。具体情况由课任导师陆泉老师监督指导,此次系统开发具有时间可行性。
1.4.2用户可行性
本系统面向用户为大学里的本科生与研究生,武汉大学每年招收本科生8000余人,硕士近6000人,而且对于武汉大学这种国内一流的综合性大学来说,其校内在读本科生与研究生在日常学习生活中均存在阅读文献的需求,因此对于我们的系统目标用户是容易找到的,具有用户可行性。
1.4.3技术可行性
本次系统开发涉及到的技术包括网页技术、PDF文件解析技术、超链接技术、数据库技术以及B/S模式设计等。
1.4.3.1 网页技术
(1)B/S服务模式
B/S结构(Browser/Server,浏览器/服务器模式)[46,47],是WEB兴起后的一种网络结构模式,WEB浏览器是客户端最主要的应用软件。这种模式统一了客户端,将系统功能实现的核心部分集中到服务器上,简化了系统的开发、维护和使用。客户机上只要安装一个浏览器,如Chrome或Internet Explorer,服务器安装SQL Server、Oracle、MYSQL等数据库。浏览器通过Web Server 同数据库进行数据交互。
(2)HTML/XHTML
HTML指超文本标记语言[48],是一种标记语言,使用标记标签来描述网页。这种标记语言处在不断的变动之中,支持几乎所有格式的文件在网页上的呈现(包括图片、视频等)。XHTML[49]最早叫做"HTML in XML",是一种基于XML的超文本标记语言,也就是说,将以前用SGML定义的HTML改为用XML重新定义。
(3)JS
JavaScript[50]是一种在客户端浏览器中以解释方式运行的,可嵌入在网页中的执行改变网页效果的语言。其设计目标是更少地占用系统和网络资源,却可以在页面做更多的事情。有了这种语言,可使得网页设计更加灵活,页面效果丰富多彩。
(4)JSP
JSP全名为Java Server Pages,中文名叫java服务器页面[51],其根本是一个简化的Servlet设计,它是由Sun Microsystems公司倡导、许多公司参与一起建立的一种动态网页技术标准。JSP技术有点类似ASP技术,它是在传统的网页HTML(标准通用标记语言的子集)文件(*.htm,*.html)中插入Java程序段(Scriptlet)和JSP标记(tag),从而形成JSP文件,后缀名为(*.jsp)。用JSP开发的Web应用是跨平台的,既能在Linux下运行,也能在其他操作系统上运行。
(5)Ajax
AJAX 指异步JavaScript及XML(AsynchronousJavascript+XML)[52]。这个术语源自描述从基于 Web 的应用到基于数据的应用的转换。AJAX不是一种新的编程语言,而是一种用于创建更好更快以及交互性更强的 Web 应用程序的技术。AJAX 在浏览器与 Web 服务器之间使用异步数据传输(HTTP 请求),这样就可使网页从服务器请求少量的信息,而不是整个页面。
1.4.3.2数据库技术
(1)MYSQL
MySQL 是一个关系型数据库,由瑞典 MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性[53]。MySQL 所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策(本词条"授权政策"),它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。由于其社区版的性能卓越,搭配 PHP ,Linux和 Apache 可组成良好的开发环境,经过多年的web技术发展,在业内被广泛使用的一种web服务器解决方案之一,称之为LAMP。
(2)Navicat
Navicat是一套快速、可靠并价格相宜的数据库管理工具[54],专为简化数据库的管理及降低系统管理成本而设。它的设计符合数据库管理员、开发人员及中小企业的需要。Navicat 是以直觉化的图形用户界面而建的,让你可以以安全并且简单的方式创建、组织、访问并共用信息。Navicat for MySQL是一套专为 MySQL 设计的高性能数据库管理及开发工具。它可以用于任何版本 3.21 或以上的 MySQL数据库服务器,并支持大部份 MySQL 最新版本的功能,包括触发器、存储过程、函数、事件、视图、管理用户等。
1.4.3.3 PDF文件解析技术
(1)Adobe Acrobat SDK
Adobe Acrobat SDK[55]是一套工具,帮助开发的软件与 Acrobat 技术的交互,提供在 Windows 和苹果 Mac OS 环境发展的支持。该 SDK 包含的头文件,类型库,简单的工具,示例代码和文档。它既能很好的显示 PDF 又能很好的解析 PDF。它的具体实现语言有 JavaScript 和 C++。其中 JavaScript 是一种跨平台的脚本语言。通过JavaScript 扩展时,Acrobat 公开 Acrobat 和它的插件文档作者的大部分功能。Acrobat中定义了几个对象,让自定义的程序能够跟一个 PDF 文件或者字段进行交互。C++的 API 比起 JavaScript 有访问 COS 和其他低层次的对象的权限,可以操纵 PDF 内容流等,但是不能使用 SOAP 和其它 Web 服务,也能操作 PDF 文档中的多媒体。
(2)ICEpdf
ICEpdf[56]是一种开源,轻量级的pdf 引擎,用于展示/查看PDF文档,转换和抽取PDF文档的内容,还可以集成到Java桌面应用程序或Web服务器中使用。ICEpdf的优势:与java客户端无缝整合,通过配置完全控制功能和用户接口;易于开发和使用,无需任何其他PDF工具支持;可作为独立的PDF查看工具,也可以嵌入到其它PDF查看器组件中;轻松的将PDF转换成图片文件(PNG,JPEG或者GIF),这些工作都可以很容易在Java服务器端完成;支持所有PDF内置字体;支持PDF文档的增量加载,方便快速读取数据量较大的文件;支持Adobe标砖密码保护;支持读取PDF注释标记信息。
1.4.4数据可行性
武汉大学图书馆购买了较为丰富的数据库,中文数据库主要包括中国知网、维普、万方、读秀等国内知名数据库,而英文数据库也包括WOS、EI等国际认可度很高的数据库。
本次系统实验数据,将选取中国知网或者WOS中某一篇或几篇文献,将该文献中所包含的所有被引文献通过武汉大学图书馆下载保存在系统建造的数据库中,并不存在太大问题。此外,由于数据库极其丰富,找到一篇具有需要各种引文功能的文献并不是太大的限制。
1.4.5团队可行性
本小组成员均为信息管理与信息系统专业2013级的学生,在前三年的本科学习阶段,学习过 Java编程与设计、数据库、数据结构、管理信息系统等课程基础,并于大三上学期小组成员开发过中文关键词抽取、文章聚类、C\S服务通信等信息系统,拥有一定的信息系统设计与开发的经历与经验,具有团队可行性。
| 实验阶段名称 | 参与人员(其中第一个为阶段负责人) |
| 领域分析 | 王鑫、张慧、高志辉、徐振怡 |
| 需求分析 | 邹文平、邱科达 |
| 系统设计 | 高志辉、王鑫、邱科达 |
| 系统开发 | 邱科达、王鑫、邹文平 |
| 系统测试 | 徐振怡、张慧 |
| 系统评估 | 张慧、邹文平、王鑫、邱科达、高志辉、徐振怡 |
领域分析部分参考文献:
[1]刘欣. 基于阅读价值的科技文献排序方法研究[D].大连理工大学,2010.
[2]艾华,孟繁疆,李勇,孙军. 基于PDF的文献管理软件的开发[J]. 煤炭技术,2010,07:234-235.
[3]Maria D.D Collins ,&Christine L Ferguson,Context-Sensitive Linking.Serials Review,2002,28(4):267-282
[4]钟惠中. 科技文献自动辅助阅读系统[D].华中科技大学,2012.
[5]Anne Mendenhall & Tristan E. Johnson (2010) Fostering the development of critical thinking skills, and reading comprehension of undergraduates using a Web 2.0 tool coupled with a learning system, Interactive Learning Environments, 18:3, 263-276.
[6]Lebow, D.G., Lick, D.W., & Hartman, H. (2009). New technology for empowering virtual communities. In M. Pagani (Ed.), Encyclopedia of Multimedia and Technology (2nd) (pp. 1066–1071). Hershey, PA: IGI Global.
[7]迟海. 中文专利辅助阅读[J]. 科技风,2012,21:198.
[8]赵琦,张智雄,孙坦. 文本可视化及其主要技术方法研究[J]. 现代图书情报技术,2008,08:24-30.
[9]Mladenic M G D. Visualization of News Articles [EB/OL]. [2008-06-12]. http://eprints.Pascal-network.org/archive/00000742/01/GrobelnikMladenic-Contexter.pdf
[10] Hearst M A. TileBars: Visualization of Term Distribution Information in Full Text Information Access[C]. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 1995:59-66.
[11]Leskovec J, Grobelnik M, Milic-Frayling N. Learning Sub-structures of Document Semantic Graphs for Document Summarization[C]. Link KDD. 2004.
[12] Paley W B. TextArc: Showing Word Frequency and Distribution in Text[C].IEEE Symposium on Information Visualization.2002.
[13] Havre S, Hetzler B, Nowell L. ThemeRiverTM: In Search of Trends, Patterns, and Relationships [EB/OL]. [2008 -06 -12]. http://infovizpnl.gov/pdf/themeriver99.pdf
[14] History Flow-Visualizing the Editing History of Wikipedia Pages [EB/OL]. [2008-06-12]. http://www.research.ibm.com/visual/projects/history_flow/.
[15]陆泉,陈静, jin zhang "电子图书多粒度内容解析系统v1.0"使用说明书
[16] http://www.zhihu.com/question/26901116知乎话题"如何总结和整理学术文献"
[17] http://www.zhihu.com/question/40029977知乎话题"参考文献有网页链接,是不是用户体验更好?"
[18] http://blog.sciencenet.cn/blog-681387-688590.html科学网相关博文
[19]Suzanne Hidi. Interest, Reading, and Learning: Theoretical and Practical Considerations. Educational Psychology Review, 2001, 13(3): 191-209
[20]Alexander, Patricai A., Jetton, Taman L., Kulikowich, Jonna M, interrelationship of knowledge, interest, and recall: assessing a model of domain learning, journal of educational psychology vol87(4), p559-575, 1995
[21]Gregory Schraw, Stephen Lehman (2001), Situational Interest: A Review of the Literature and Directions for Future Research: Educational Psychology Review, vol.13, No 1, 2001.
[22]Suzanne E. Wade, research on importance and interest: implications for curriculum development and future research, educational psychology review, vol13 (3), 2001
[23]Tobias, Sigmund, interest and metacognitive word knowledge, journal of educational psychology, vol87 (3), p 399-405, 1995
[24]訾韦力. 近年国内图式理论应用研究述评[J]. 中国农业大学学报(社会科学版),2004,03:77-81. [25]Anderson R.C., & Pearson, P.D. A schema–theoretic view of basic processes in reading comprehension[C] // P.D. Pearson. Handbook of reading research. New York: Longman,1984: 255-292.
[26]饶斌. 建构-整合模式理论:指导大学生有效提升阅读能力的新途径[J]. 西华大学学报(哲学社会科学版),2013,06:48-52.
[27]涂阳军,陈建文. 先前背景知识、兴趣与阅读理解之关系研究[J]. 心理研究,2009,03:84-89.
[28]章凯,张必隐. 兴趣对文章理解的作用[J]. 心理学报,1996,03:284-289.
[29] Ulrich Schiefele, interest, learning, motivation, educational psychologist, 26(3&4), 299-
[30]闫明明. 研究生阅读现状交叉分析[J]. 中国研究生,2012,04:7-9.
[31] Nigel Harwood, and Bojana Petric, " Performance in the Citing Behavior of Two Student Writers," Written Communication, Vol.29, No.1, 2012, pp.55-103.
[32]D.O. Case, and G. M. Higgins. "How Can We Investigate Citation Behavior? A Study of Reasons for Citing Literature in Communication." Journal of the American Society for Information Science. Vol. 51.No. 7.2000.pp. 635-645.
[33]P.Vinkler. "A Quasi-Quantitative Citation Model." Scientometrics. v01.12, no.1, 1987: PP, 47-72.
[34]Charles Oppenheim, and Susan P.Renn. "Highly Cited Old Papers and the Reasons Why They
Continue to Be Cited." Journal of the American Society for Information Science, v01.29,
no.5,1978:PP.225-23 1.
[35] Bluma Pefitz. "A Classification of Citation Roles for the Social Sciences and Related Fields."
Scientometrics,v01.5,no.5,1983:PP.303-312.
[36]刘宇,李武. 引文评价合法性研究——基于引文功能和引用动机研究的综合考察[J]. 南京大学学报(哲学.人文科学.社会科学版),2013,06:137-148+157.
[37]刘辉. 超文本阅读的模式与效果——一项基于元认知的实验研究[J]. 西南科技大学学报(哲学社会科学版),2012,02:43-48.
[38]张智君. 超文本阅读中的迷路问题及其心理学研究[J]. 心理学动态,2001,02:102-106.
[39]卜丽娜. 对优化超文本阅读的思考[J]. 湖南第一师范学院学报,2013,01:40-43.
[40]赵晟楠. 超文本阅读中常见问题及学习策略的影响作用[J]. 邢台学院学报,2010,01:10-11.
[41]石向实,申腊梅. 超文本阅读绩效研究述评——认知的视角[J]. 社会心理科学,2010,04:3-5+44.
[42]郑欢欢. 超文本和背景音乐对多媒体学习的影响[D].河南大学,2008.
[43].Anderson, D., Hypertext/Hypermedia: Donald H. Jonassen. Englewood Cliffs, NJ: Educational Technology Publications. Computer in Human Behavior, 1995. 11(3-4): p. 667-668.
[44]吴骏. 超文本阅读条件下信息获取的实验研究[J]. 前沿,2004,09:192-195.
[45] Schommer, M. and J. Surber, Comprehension-monitoring Failure in Skilled Adult Readers. Journal of Educational Psychology, 1986. 78(5): p. 353-357.
[46]张友生, 陈松乔. C/S与B/S混合软件体系结构模型[J]. 计算机工程与应用, 2002, 38(23):138-140.
[47] 朱爱红, 余冬梅, 张聚礼. 基于B/S软件体系结构的研究[J]. 计算机工程与设计, 2005, 26(5):1164-1165.
[48]宋菲娅. 超文本标记语言HTML5新特性探索[J]. 网络安全技术与应用, 2012(7):40-41.
[49] 王仲. XHTML--一种可扩展的超文本标记语言[J]. 计算机科学, 2000, 27(10):16-18.
[50]王震宇, 刘清森. JavaScript语言的特性和应用[J]. 信息工程大学学报, 1998(3):32-34.
[51]Bergsten H, 光田, 秀. JavaServer Pages[M]. O'Reilly, 2001.
[52]柯昌正, 黄厚宽. Ajax技术的原理与应用[J]. 铁路计算机应用, 2007, 16(1):27-29.
[53]兰旭辉, 熊家军, 邓刚. 基于MySQL的应用程序设计[J]. 计算机工程与设计, 2004, 25(3):442-443.
[54]黄永聪, 吴琦, 徐玉峰,等. 电网系统用电检查管理系统的设计与实现[J]. 计算机技术与发展, 2008, 18(11):187-190.
[55] Documents S. Software development kit, Adobe Systems, Adobe Acrobat[J]. Phon.
[56]Developer H. PDF Rendering Engine ICEpdf jetzt Open Source[J]. 2009.














 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









