







用Tensorflow1.1搭建一个自编码网络(含有多个隐藏层),在MNIST数据上进行训练
自编码网络的作用是将输入的样本进行压缩到隐藏层,然后解压在输出层重建.所以输入层和输出层神经元的数量是相等的.在压缩的过程当中网络会除去冗余的信息(要限制隐藏层神经元的数量),留下有用的特征.类似与主成分分析PCA,
多个隐藏层能够学到更有意义的特征
# 导入相关的库
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data# 设置模型的训练参数
# 学习效率
# 训练的轮数
# 小批量数据大小
# 每隔几轮显示训练结果
# 测试样本数量
learning_rate = 0.001
training_epochs = 40
batch_size = 200
display_step = 1
test_examples = 10# 网络参数,输入层,第一个隐藏层,第二个隐藏层的节点个数,
# 网络实际是有3个隐藏层(784,256,128,256,784)
n_input = 784
n_hidden1 = 256
n_hidden2 = 128# 定义输入数据节点(占位节点)
X = tf.placeholder(tf.float32, [None, n_input]) # None的意识是:任意数量# 在深度模型中,权重初始化的太小,信号会在每层传递的时候逐渐缩小,但是如果权重
# 初始化的太大,信号会在每层传递的时候逐渐放大导致发散和失效,Xavier初始化方
# 方法就是,让权重初始化的不大也不小
# layer1, layer2 为相邻两层神经元的节点数
def xavier_init(layer1, layer2, constant = 1):
Min = -constant * np.sqrt(6.0 / (layer1 + layer2))
Max = constant * np.sqrt(6.0 / (layer1 + layer2))
return tf.random_uniform((layer1, layer2), minval = Min, maxval = Max, dtype = tf.float32)
# 初始化权重(字典)和偏置
weights = {
'encoder_1': tf.Variable(xavier_init(n_input, n_hidden1)),
'encoder_2': tf.Variable(xavier_init(n_hidden1, n_hidden2)),
'decoder_1': tf.Variable(xavier_init(n_hidden2, n_hidden1)),
'decoder_2': tf.Variable(xavier_init(n_hidden1, n_input)),
}
# 偏置
biases = {
'encoder_1': tf.Variable(tf.random_normal([n_hidden1])),
'encoder_2': tf.Variable(tf.random_normal([n_hidden2])),
'decoder_1': tf.Variable(tf.random_normal([n_hidden1])),
'decoder_2': tf.Variable(tf.random_normal([n_input])),
}# 定义压缩方法
def encoder(x):
h_layer1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_1']), biases['encoder_1']))
h_layer2 = tf.nn.sigmoid(tf.add(tf.matmul(h_layer1, weights['encoder_2']), biases['encoder_2']))
return h_layer2
# 解压重建方法
def decoder(h_layer2):
h_layer3 = tf.nn.sigmoid(tf.add(tf.matmul(h_layer2, weights['decoder_1']), biases['decoder_1']))
out_layer = tf.nn.sigmoid(tf.add(tf.matmul(h_layer3, weights['decoder_2']), biases['decoder_2']))
return out_layer# 构建模型
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
# 网络输出结果
pred_y = decoder_op
# 真实值,即输入
y = X
# 定义损失函数和优化器
cost = tf.reduce_mean(tf.pow(y - pred_y, 2))
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)# 变量初始化Op
init = tf.global_variables_initializer()# 加载数据
mnist = input_data.read_data_sets('MNIST/mnist', one_hot=True)Extracting MNIST/mnist/train-images-idx3-ubyte.gz
Extracting MNIST/mnist/train-labels-idx1-ubyte.gz
Extracting MNIST/mnist/t10k-images-idx3-ubyte.gz
Extracting MNIST/mnist/t10k-labels-idx1-ubyte.gz
# 开启一个回话
with tf.Session() as sess:
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
# 开始
Cost = []
for epoch in range(training_epochs):
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# 执行optimizer,和 cost ,返回 loss value
_, c = sess.run([optimizer, cost], feed_dict={X:batch_x})
Cost.append(c)
# 打印训练情况
if epoch % 1 ==0:
print 'Epoch: %d, cost = %.9f'%(epoch+1, c)
print ('Optimization Finished')
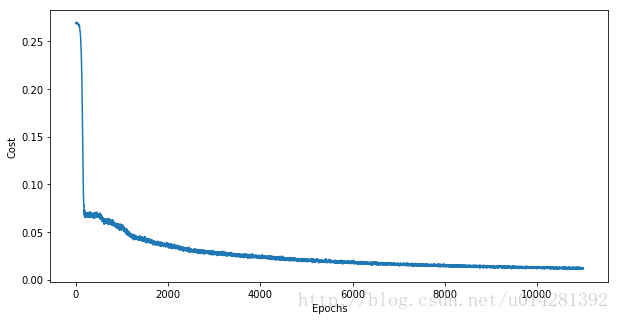
fig1,ax1 = plt.subplots(figsize=(10,5))
plt.plot(Cost)
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Cost')
plt.show()
#---------------------------------------测试-------------------------------------
# 选取测试数据(10个样本)进行重建测试
test_pred_y = sess.run(pred_y, feed_dict={X: mnist.test.images[10:20]})
# 比较测试原始图片和 压缩重建后的图片
fig, ax = plt.subplots(2, 10, figsize=(10, 2))
for i in range(10):
ax[0][i].imshow(np.reshape(mnist.test.images[10+i], (28,28)))
ax[1][i].imshow(np.reshape(test_pred_y[i], (28, 28)))
plt.show()
Epoch: 1, cost = 0.065628514
Epoch: 2, cost = 0.064358398
Epoch: 3, cost = 0.058146056
Epoch: 4, cost = 0.049762029
Epoch: 5, cost = 0.043949362
Epoch: 6, cost = 0.039976787
Epoch: 7, cost = 0.037451632
Epoch: 8, cost = 0.033604462
Epoch: 9, cost = 0.030377652
Epoch: 10, cost = 0.029405368
...............
Epoch: 36, cost = 0.012330795
Epoch: 37, cost = 0.013209986
Epoch: 38, cost = 0.012119931
Epoch: 39, cost = 0.011887702
Epoch: 40, cost = 0.011322427
Optimization Finished

测试数据的原始图片 与 重建测试图片对比

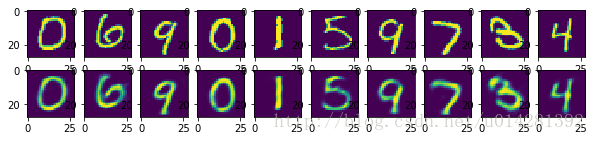














 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









