







今天看了一篇名为Top 3 Troubleshooting Tips to Keep You Sparking的文章,讲述了一些编写Spark程序需要注意的地方,看完之后想要总结一下。
Spark执行模型,总结为官方的架构图:
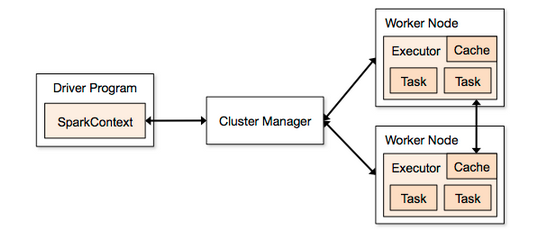
本文主要讨论Driver和Worker。
我们知道,对于Spark开发的分布式应用程序,和写普通的scala程序基本类似。所以这时往往会陷入一些误区:
在Spark开发的应用程序的对象里,我给他们分成2类对象:
1、闭包内的对象:即在类似map, filter, reduceByKey这样的闭包内的对象,通常会有一个函数映射。
2、闭包外的对象:反之,即使闭包外的对象。
这2类对象其实是混杂在Driver 和 Worker里的,即并不是所有对象都会随着程序序列化到Worker里。
Summary:
Summary1:对于Spark应用程序,创建在闭包内的对象 和 创建在闭包外的对象的状态是不一样的。
Summary2: 如果强制将一个不支持序列化的对象,放到闭包里,会报异常NotSerializableException
Summary3:闭包内的对象会被序列化到Worker参与计算,闭包外的对象只会存在于Driver里。
Summary3.1 闭包外的对象之存在于Driver内会导致->所有涉及此对象的操作,会在Driver里单线程执行,导致Spark程序非常慢
Summary4:关于异常捕获,如果在Spark Driver程序中对job的异常没有捕捉的话会导致java.lang.IllegalArgumentException: Shuffle Id Nnnn Registered Twice?
解决方案:
1、对于状态不一致,和NotSerializableException这种情况,可以采用序列化自定义对象的方法 和 BroadCast对象的方法。
2、对于异常,尽量捕捉能在并行操作中可以处理的异常。
还有2个问题:
Tip2 Why spark slow的代码例子里JsonParser.parse为什么不报NotSerializableException,是否object声明的对象默认是序列化的?是否伴生对象不能被分发到Worker里,只能在Driver里,Why?
——EOF——
原创文章,转载请注明出自:http://blog.csdn.net/oopsoom/article/details/38389111















 5781
5781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









