1 , 简介
Tianqi Chen大神提出了一种可扩展性的端到端基于树的boosting系统,这个系统可以处理稀疏性数据,通过分布式加权直方图算法去近似学习树,这个系统也提供基于缓存的加速模式、数据压缩、分片功能。机器学习应用于垃圾邮件分类、基于上下文植入广告、阻止银行恶意袭击的漏洞检测系统、探测引发物理显现的事件。有两个重要的因子驱动这些成功的应用:发现数据之间相关性的模型、从大量数据集中学习到有趣的模型。
梯度boosting回归树已经被证明在大量的系统中有好的效果,例如:标准分类基准、应用于排序的boosting树变体、应用于广告点击预测,当然boosting树是集成学习方法的一种,大量应用于比赛。XGboost已经应用于大量的实战系统,在29个kaggle比赛中,17个获胜者使用了XGboost,这些获胜者一部分单独使用XGboost或者通过与神经网络集成,比赛的获胜者也指出有小部分的继承学习的算法效果比XGboost好。
XGboost能够在一系列的问题上取得良好的效果,这些问题包括存销预测、物理事件分类、网页文本分类、顾客行为预测、点击率预测、动机探测、产品分类。多领域依赖数据分析和特征工程在这些结果中扮演重要的角色。XGboost在所有场景中提供可扩展的功能,XGBoost可扩展性保证了相比其他系统更快速,XGBoost算法优势具体体现在:处理稀疏数据的新奇的树的学习算法、近似学习的分布式加权直方图。XGBoost能够基于外存的计算,保障了大数据的计算,使用少量的节点资源可处理大量的数据。XGBoost的主要贡献:
构建了高可扩展的端到端的boosting系统。
提出了具有合理理论支撑的分布分位调整框架。
介绍了一个新奇的并行适应稀疏处理树学习算法。
提出了基于缓存快的结构便于外存树的学习。
已经有人做了并行树、基于外存的计算、缓存的计算、稀疏特征的学习等一些列工作,这篇文章最重要的是能够把很多特征结合到一个系统中。
文章的组织结构:boosting树的正则化(防止过拟合)、树的split方法(decision Tree 使用Gini划分)、系统设计、实验。
2 , Tree Boosting 简述
2.1 XGboost的正则化目标
在给出n个实例,m维特征的情况下,
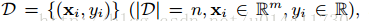
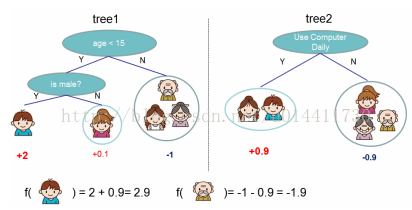
树的集成模型(多个模型相加的过程)使用K个相加函数预测结果。
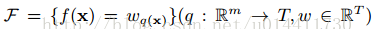
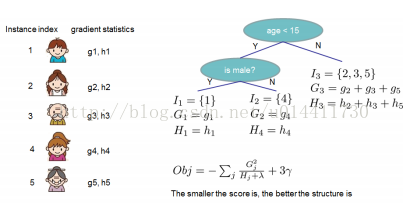
(q 将样本实例(Rm)映射到叶子节点,w T为空间,T为叶子的数量)是CART的假设空间,q 代表每颗树的结构,映射实例样本到对应的叶子节点,T代表一棵树叶子的数量,w代表叶子节点的分数,wq(x)表示为一颗独立的树对于样本实例的预测值。如图:
q(x)代表一颗树,W代表叶子的分数,f(x) 为样本实例的预测值,所以和CART的区别在于每个叶子节点有相应的权重Wi。为了学到模型需要的函数,需要定义正则化目标函数。
一种标准的正则化目标项= differentiable convex loss function + regularization,即损失函数+正则项。
L衡量预测值与真实值的差异,Ω作为模型复杂度的惩罚项,对于树的叶子节点个数和叶子节点权重的正则,防止过拟合,即simple is perfect,正则化项比RGF模型更加简单。
2.2 梯度boosting树
树的集成模型不能在传统的欧几里得空间中找到合适的解,而应该通过迭代求近似解。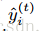 表示通过t次迭代去近似真实的值,这样可以添加迭代更新项
表示通过t次迭代去近似真实的值,这样可以添加迭代更新项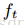 ,也就是boosting的想法:
,也就是boosting的想法:
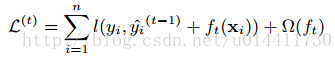
将损失项在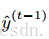 处泰勒展开:
处泰勒展开:
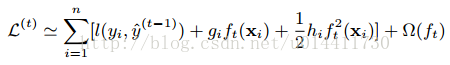
gi和hi分别为L的一阶、二阶偏导(梯度),移除常数项:
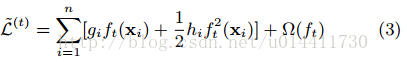
将Ω展开:
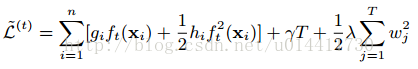
可以看到左侧为对于所有样本求目标函数的和,右边是对于所有叶子节点求正则惩罚项(需要把两项相加),将每个叶子节点拆分为样本集: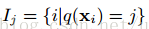
如图:
将样本分解为每个节点上的样本,所以目标函数化简为统一的在叶子节点上的和:
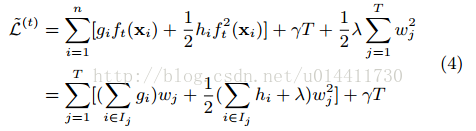
如果固定了树的结构,即目标函数只与ω叶子权重相关,所以可通过对目标函数关于ω求导,得:
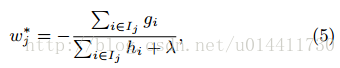
带入目标函数可得最优解:
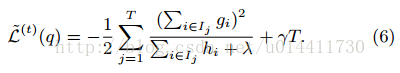
方程(6)作为衡量树结构质量的指标,这个分数类似于决策树中的纯度,只是这个评价树的指标通过目标函数获得,而不是自定义的,如图:
列举所有可能的树的结构是不可能的,应该在初始叶子节点上通过贪心算法迭代添加分支。IL和IR是split(划分)之后左右节点的集合。I = IL U IR,所以loss function变为:
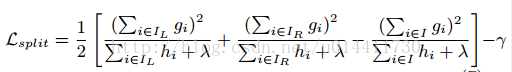
左 + 右 - 合并的形式通常作为评估划分的评价指标,对照公式(6),应该使上式最大。
2.3 收缩(学习速率)和列抽样(借鉴随机深林)
XGBoost除了使用正则项防止过拟合外,还使用了收缩和列抽样。收缩再次添加权重因子η到每一步树boosting的过程中,这个过程和随机优化中的学习速率相似,收缩减少每棵单独树的影响并且为将形成的树预留了空间(提高了模型的效果)。特征(列)抽样(在随机森林中使用)(相对于遍历每个特征,获取所有可能的gain消耗大)找到近似最优的分割点,列抽样防止过拟合,并且可以加速并行化。
3 分割算法
3.1 基础精确的贪心算法
方程(7)的关键问题是找到合适的分割,精确的贪心算法通过列举所有特征的可能划分找到最优划分解,许多单机Tree算法使用这种方式找到划分点,例如 sklearn、Rs gbm、单机的XGBoost。精确的算法需要排序成连续的特征,之后计算每个可能划分的梯度统计值,如算法1:
3.2 近似算法
精确通过列举特征所有可能的划分,耗时,当数据量大的时候,几乎不可能将数据全部加载进内存,精确划分在分布式中也会有问题。我们总结了近似的策略,如算法二所示,算法首先根据特征分布的百分比提议候选划分点,之后按照候选划分点将特征映射到槽中,找到最好的划分百分点。全局划分需要尽可能详细的特征划分,局部划分初步就能达到要求。在分布式树中许多存在的近似算法都使用这个策略,也可以直接构造直方图近似(lightGBM直方图近似,速度更快,好像准确度有所降低),也可以使用其他的策略而不仅仅是分位法,分位策略便于分布式实现、计算方便。
3.3 加权分位法
近似计算中重要的一步是提出候选的分位点,特征百分比通常作为分布式划分的依据。考虑多重集合
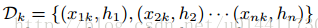
,key-value 为第样本的(样本点的第K维特征, 二阶导数),定义排序函数
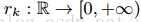
:
表示小于z的点的比例,目标是找到划分点,
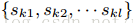
,这样的划分点满足式(9)
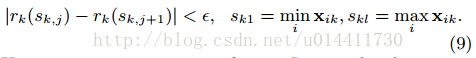
,这样尽量做到均匀划分,hi作为每个数据点的权重的原因,方程(3)整理成平方差的形式,hi为label gi/hi的加权平方损失,对于大数据找到满足基准的划分点时意义重大的。
在以往的分位法中,没有考虑权值,许多存在的近似方法中,或者通过排序或者通过启发式方法(没有理论保证)划分。文章的贡献是提供了理论保证的分布式加权分位法。
3.4 稀疏自适应分割策略
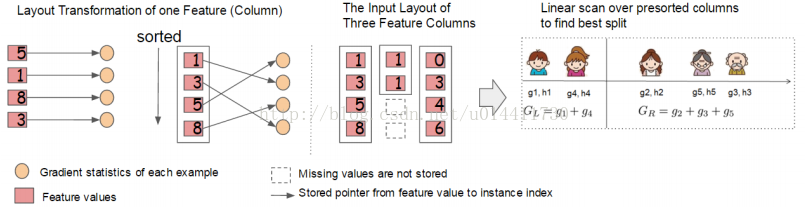
在实际应用中,稀疏数据是不可避免的,造成稀疏数据的原因主要有:1 ,数据缺失。 2 , 统计上的0 。 3 , 特征表示中的one-hot形式,以往经验表明当出现稀疏、缺失值时时,算法需要很好的稀疏自适应。
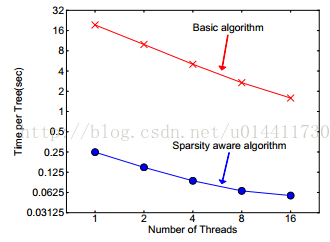
当出现特征值缺失时,实例被映射到默认的方向分支,关键是访问非缺失实体对Ik。现在的算法处理不存在的作为缺失值,学到处理缺失的最好方向,算法通过枚举一致性情况同样适用于用户指定的值。现有的树系统仅仅优化稠密的数据或者专注于处理有限的任务,例如:分类编码。XGBoost通过一种统一的方式处理所有的稀疏性情况。当出现稀疏情况的时候,稀疏性计算只有线性的计算复杂度。如图所示,稀疏自适应算法比基本的非稀疏数据算法快大约50倍。
4 , 系统设计
4.1 适应于并行学习的列块
排序开销了树学习的大部分时间,XGBoost存储数据进入划分的内存块单元,每个块中的数据以压缩列的方式存储,排序每个块单元中中的数据,输入的数据在训练前一次计算,后续重复使用。在精确算法中,需要存储整个数据进入一个单块,之后整个数据排序分割,扫描整个块发现候选的划分叶子节点。如图并行学习算法
,每一列通过相应的特征排序,在列中进行线性扫描。在近似算法中,每一块对应于数据的子集,不同的块可以分布在不同的机器上,发现分位点的扫描变成线性复杂度。
每个分支独立产生候选分立点。直方图算法中二分搜索是线性时间的合并。并行每一列找到树的分割点,列块结构支持列的子抽样。
时间复杂度分析
d表示为树的最大深度,k为树的总数量。在精确贪心算法中,原始自适应稀疏算法复杂度为
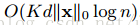
,
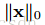
表示为非缺失的实体对。在分块树算法中,时间复杂度为
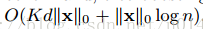
。
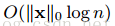
是预处理花销的时间,这个时间可以被分摊。分块处理可以节省logn时间因子。在近似计算中,原始算法的时间复杂度为
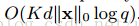
,q是候选的划分点,分块近似算法复杂度为
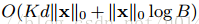
,B是块中行的最大值。
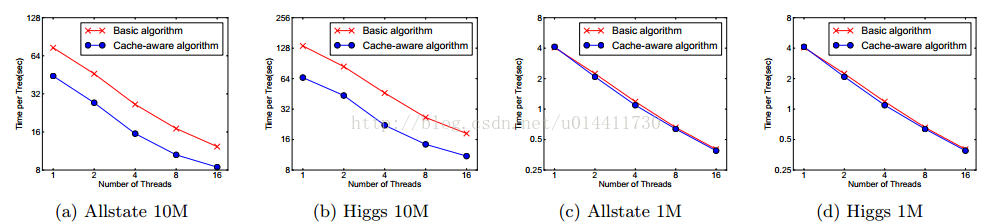
4.2 自适应缓存的访问
分块帮助优化划分点获取的复杂度,新的算法需要每一行的梯度值,这些值通过特征顺序访问,这是非连续内存访问过程。在累积和非连续内存获取操作中,划分枚举的基本时实现需要实时读写依赖。这个过程延缓分位点的发现,当梯度值在CPU没有命中,cache缺失的时候。针对这样的问题,我们提出自适应再获取算法。我们获取每个线程的缓存,从缓存中获取梯度数据,之后以类似批处理的方式累计。这种预取改变读写依赖的方,帮助减少限制的运行时间,特别是行数据很大时。如图基本算法与缓存策略:
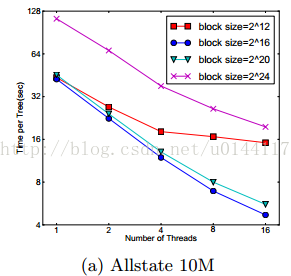
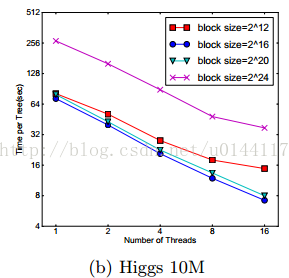
对于近似算法,我们通过选择合适的块大小解决问题,我们定义块的大小为包含在块中最大实例,因为这个反应了梯度数据的存储开销。选择太小的工作块会有线程负载,从而导致低效的并行化。而太大的块导致cache缺失,梯度数据不能很好的匹配CPU的cache。下图比较了块选择:
结果验证了我们上面的讨论,块的大小影响效率。
4.3 核外计算的块
系统的目标是充分利用机器资源完成大规模学习任务,除了利用CPU cache和内存外,充分利用磁盘空间处理数据也是非常重要的,特别是当内存不能加载完整个数据的时候。在计算期间,使用独立的线程从磁盘中预取块到内存缓存中,所以可以并发执行计算任务。这样做只是保证了计算过程并发执行,这不能解决开销大量时间读取磁盘的瓶颈,增加磁盘I/O的通道问题能够减少开销的天花板。针对以上问题,我们提出两种方案提高外存计算的能力。
块压缩
在加载数据进内存时,块按照列进行压缩,压缩通过独立的线程进行,这是以压缩、解压代价换区磁盘I/O。
块分片
将数据分片在在多个磁盘上,一个预取线程对应一个磁盘。
5 相关的工作
该系统实现了梯度boosting 包,这个包在函数空间上做了额外的优化。梯度boosting已经成功应用于分类、排序、结构预测和其他领域。XGboost模型合并正则模型防止过拟合,这种集成正则的操作已经有人做过,该模型通过并行简化了目标函数和算法。列抽样借鉴于随机森林,简单有效。自适应稀疏方法多用在线性模型中,很少用在树模型。该算法联合了多种有效的方法(论文说是第一次)。树的并行工作已经有人做过了,许多并行也是通过近似处理或者按列划分数据。分位点法常用于数据库中,本算法需要找到梯度boosting树中的加权分位点。
6 端到端的评估工作
6.1 系统实现
XGBoost主要提供权重分类、排序目标函数,支持python、R、Julia,集成到了本地的数据管道如sklean。在分布式系统中,XGboost也支持Hadoop、MPI、Flink、spark。
6.2 数据集
6.3 分类

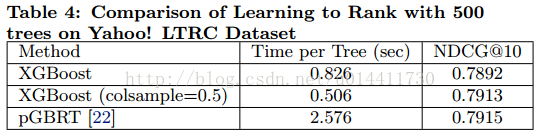
6.4 排序
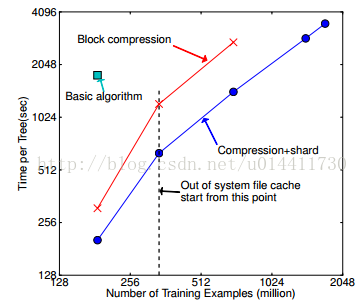
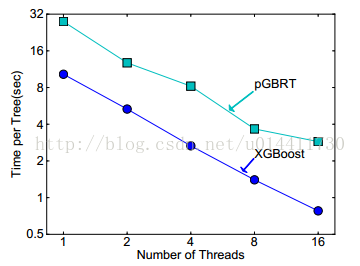
6.5 外存实验
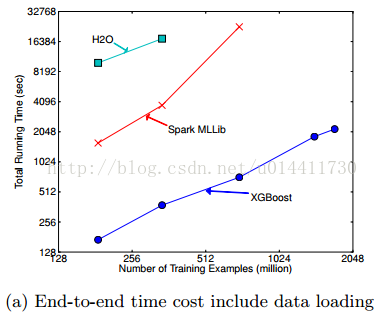
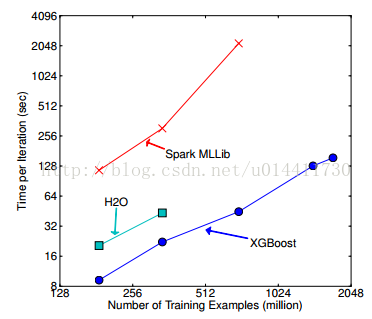
6.6 分布式实验








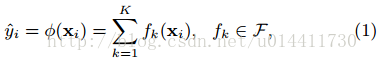
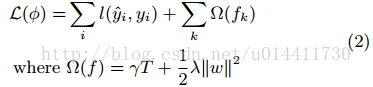


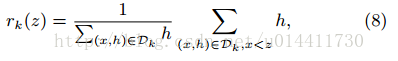
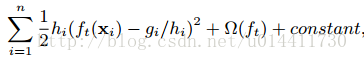















 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









