









引介
ICCV2017的文章,arXiv:1703.07684 [cs.CV],本文有LeCun的署名.
Abstract
预测接下来视频帧的单纯的RGB像素值已经被研究了很久,本文提出了一种新奇的任务——预测接下来的视频帧的语义分割.
同时,本文提出了一种自动回归CNN(AR-CNN)来进行迭代生成多帧.
Model
数据
采用Cityscapes数据集,分辨率转化为128x256.
采用的度量标准是PSNR(Peak Signal to Noise Ration)、SSIM(Structural Similarity Index Measure)、MIoU等.
由于视频的标注数据很少,并且不容易获取,因此本文采用比较先进的方法(Dilated10)在Cityscapes的视频上进行数据的标注,作为label.
单帧预测
baseline:
(1)拷贝最后一帧(2)使用optical flow包裹最后一帧
建立了多种网络进行比较:
X2X(现实预测现实)
S2S(分割预测分割)
XS2X、XS2S、XS2XS
采用一种Multi-scale架构进行训练
注意点:
(1)使用softmax的pre-activations,认为这种方式包含了更多的信息
(2)loss function使用了一种变种:

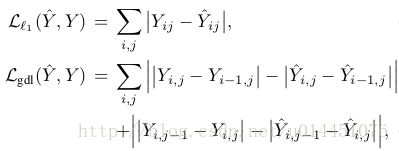
(3)另外也尝试了使用gan和VAE进行训练
预测未来更长时间
使用自动回归CNN,S1:t预测St,S2:t+1预测St,逐步预测更深。
分别尝试了0.18s、5s、10s的预测,具体方式在现实的图像中采样4帧,输出未来的几帧,说起来比较复杂,其实做法很简单,具体参考论文吧.
Summary
对我来说,本文最终要的几点是:(1)考虑到直接预测未来场景很困难,但是先从分割到分割比较容易(2)考虑到视频标注数据集比较少,采用先进的方法进行生成(3)提出了一种自动回归的方法,但是没有太多的细节
Thinking
直接预测未来的RGB现实图片可能比较难,根据本文的启发,能不能从现实的RGB->现实的分割->未来的分割->未来的RGB.














 5599
5599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









