









因为代码只有几行,所以可以先贴代码:
import urllib.request
url = r'http://douban.com'
res = urllib.request.urlopen(url)
html = res.read().decode('utf-8')
print(html)第一行,导入 urllib库的request模块
第二行,指定要抓取的网页url,必须以http开头的
第三行,调用 urlopen()从服务器获取网页响应(respone),其返回的响应是一个实例
第四行,调用返回响应示例中的read()函数,即可以读取html,但需要进行解码,具体解码写什么,要在你要爬取的网址右键,查看源代码,
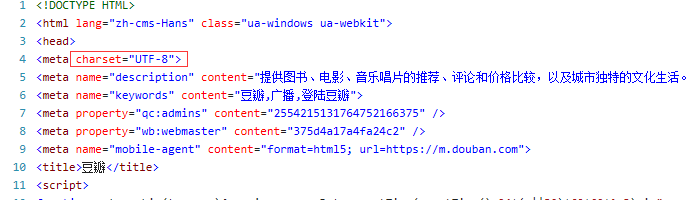
红框中的 charset= 则表示编码格式,我要爬取的网页编码为 utf-8,所以,解码我也填utf-8,如果是gbk2313,则填写的是GBK
(更为简单的方法是在程序中调用info()获取网页头部来查看编码方式:)
查看网页的头部信息以确定网页的编码方式:
import urllib.request
res = urllib.request.urlopen('http://www.163.com')
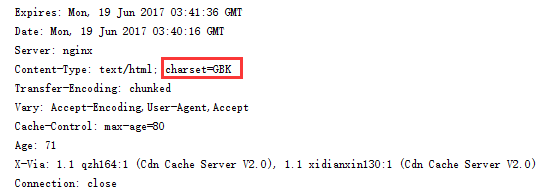
print(res.info()) #info()方法 用来获取网页头部
可以看出次网页的编码是 GBK。
第五行,打印就行。
但上面的写法是裸奔型写法,就是没有头部的,有一些网页你没有头部是不能访问的,会返回 403错误。
最正式的做法是仿照http的过程,在用爬虫获取网页的时候,加入头部,伪装成浏览器。
Http 其实就是 请求/响应模式,永远都是 客户端向服务端发送请求,然后服务端再返回响应。
有一个问题就是 头部改怎么加?可以打开你的浏览器,按F12,(我用的是谷歌浏览器)
F12打开开发者工具模式后,进入一个随便一个网页,开发者工具就会有东西出现
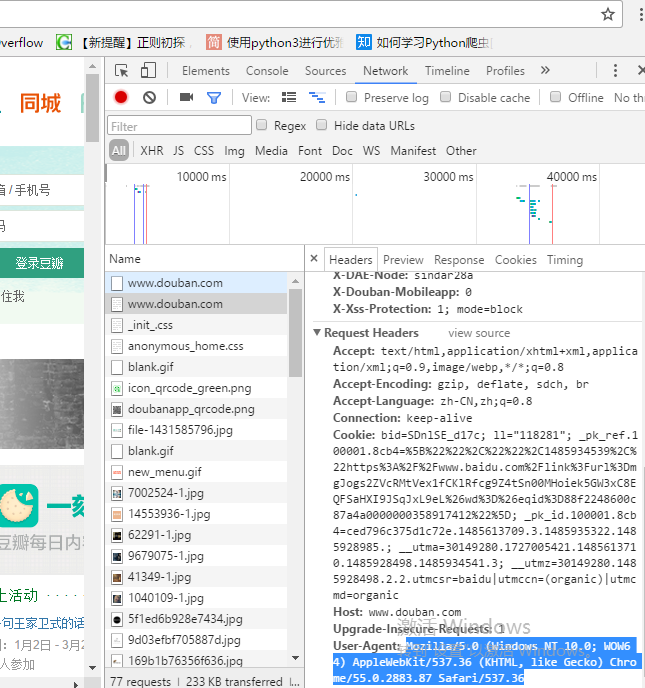
双击name栏的任意一个,在Headers 一栏会有个 User-Agent ,复制蓝色部分,蓝色部分就是头部。再把蓝色部分加入到爬虫程序中,见下面代码:
这种方式是推荐的
import urllib.request
url = r'http://douban.com'
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
print(html)注意:urllib.request.Request()用于向服务端发送请求,就如 http 协议客户端想服务端发送请求
而 urllib.request.urlopen()则相当于服务器返回的响应















 3085
3085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









