







2014年常思源同学(大四学生)作品
在mapreduce程序的运行过程中,map阶段产生的数据存放在本地磁盘中,reduce阶段节点通过远程访问的形式读取进行下一步计算。如果能够减少map阶段产生的数据量就能够大幅度提升体统性能。
Combiner是减少map阶段产生数据量的重要措施。本文档重点研究了combiner函数对于wordcount程序运行时间的影响。
本文档的研究方法是:在运行wordcount程序过程中,针对调用combiner函数和不调用combiner函数的两种情况,比较程序运行的总时间的差异,并思考这种差异产生的原因,进一步分析combiner在mapreduce程序中所起的重要作用。
2. 产生单词库文件
2.1. 产生有大量连续重复单词的单词库文件
在本研究中,wordcount程序的输入文件要求是:随机产生一个6个字母的单词,然后将这个单词复制1000次,然后重复上面两个步骤。单词库文件大小约为500M左右。
具体做法如下:
1. 用Math.random函数产生一个0.0到1.0的随机数;
2. 将这个随机数乘25加97,得到一个97到122的随机整数,对应字母a到z的ASCII码;
3. 将上述随机整数强制转换为char类型;
4. 用for循环将上述过程重复六次,产生一个6个字母的单词;
5. 用for循环将上述过程重复1000次,使得同一个单词重复1000次;
6. 用for循环重复4、5步骤,直到文件大小为500MB左右;
2.2. 产生无大量连续重复单词的单词库文件
在本研究中,为了对比,应当产生一个无大量连续重复单词的单词库文件。具体的产生方法如下:
切换到集群上的/home/hadoop/hadoopInstall/hadoop目录下,执行hadoop-examples-1.0.2.jar的jar包,可以产生一组大小约为30G的文件。这组文件的第一个part-00000是一个无大量连续重复单词的单词库文件。把part-00000作为wordcount的输入文件即可。part-00000大小约为1050MB。
3. Wordcount运行过程
3.1. 有combiner的测试(有大量连续重复单词的单词库文件作为输入)
将wordcount程序打成jar包上传至集群;
将产生的单词库作为输入文件,上传到HDFS;
在集群运行wordcount,结果如下:
开始时间09:57:54,结束时间09:59:17,总共用时83秒;
3.2. 无combiner的测试(有大量连续重复单词的单词库文件作为输入)
测试过程同上;
测试结果为:
开始时间09:45:39,结束时间09:49:02,总共用时203秒;
3.3. 有combiner的测试(无大量连续重复单词的单词库文件作为输入)
将part-00000文件作为输入,运行wordcount程序,记录时间如下:
开始时间为20:13:38,结束时间为20:16:07,用时149秒;
3.4. 无combiner的测试(无大量连续重复单词的单词库文件作为输入)
去掉wordcount程序中combiner函数,重新上传wordcount的jar包,将part-00000文件作为输入,运行wordcount程序,记录时间如下:
开始时间为20:29:26,结束时间为20:31:49,用时143秒;
4. 分析和结论
从上面可以看出,有combiner的wordcount程序运行时间明显少于无combiner的wordcount程序运行时间。原因如下:
没有combiner函数的时候,所有的数据须经网络传输到reduce节点进行处理;加入combiner函数后,每个map节点可以完成一定的reduce任务,一方面减少了reduce节点的工作量,另一方面减少了网络中所需传输的数据量,wordcount程序运行耗时减少。
再者,当有大量连续重复单词的单词库文件作为输入时,有无combiner对于wordcount运行时间影响十分明显;当无大量连续重复单词的单词库文件作为输入时,有无combiner对于wordcount运行时间影响十分微小。
造成这一现象的原因是,当有大量连续重复单词的单词库文件作为输入时,每个map节点可以进行combiner的机会更大,能够更加明显的减少网络上的数据传输、减少reduce过程的耗时;当无大量连续重复单词的单词库文件作为输入时,每个map所处理的单词几乎都是相异的,combiner函数起不到应有的作用,进而程序运行时间几乎不受combiner函数的影响。
这进一步说明:combiner函数对于减小程序运行时间这一作用的程度不仅和要分析的问题本身有关,而且还和程序的输入密切相关。
5. 进一步研究
为了进一步研究,现将作为wordcount程序输入的单词库中的同一个随机单词连续出现的次数用常数K表示。为了研究方便,令K的变化范围为:K属于[1,1000].
现在研究当K在其变化范围内不断增大时,有无combiner函数对于wordcount程序运行时间的影响程度。
5.1. K变化的实验
分别令K=1,10,100,200,500,1000,观察有无combiner函数对于wordcount程序运行时间的影响程度。
需要注意的是,当K 变化时,单词库的总大小不能变,恒为500MB。
输入文件目录为D:\jiqun\randomFile\randomFile;输出文件目录为D:\jiqun\randomFile\out;
实验结果如下:
| K值 | 有无combiner | 开始时间 (时:分:秒) | 结束时间 (时:分:秒) | Map /reduce 数目 | Wordcount 用时(秒) |
| 1 | 有 | 18:12:08 | 18:17:28 | 16/1 | 320 |
| 无 | 18:23:50 | 18:29:21 | 16/1 | 341 | |
| 10 | 有 | 17:48:52 | 17:51:01 | 16/1 | 129 |
| 无 | 17:58:33 | 18:03:20 | 12/1 | 287 | |
| 100 | 有 | 17:01:10 | 17:02:33 | 16/1 | 83 |
| 无 | 17:35:40 | 17:39:16 | 19/1 | 216 | |
| 200 | 有 | 16:38:06 | 16:39:32 | 19/1 | 86 |
| 无 | 16:42:25 | 16:45:47 | 16/1 | 202 | |
| 500 | 有 | 16:24:11 | 16:25:34 | 19/1 | 83 |
| 无 | 16:28:00 | 16:31:22 | 12/1 | 202 | |
| 1000 | 有 | 15:54:07 | 15:55:30 | 16/1 | 83 |
| 无 | 16:03:48 | 16:07:14 | 19/1 | 206 |
表1 K变化对于wordcount程序运行时间的影响
根据上表,可以画出折线图:
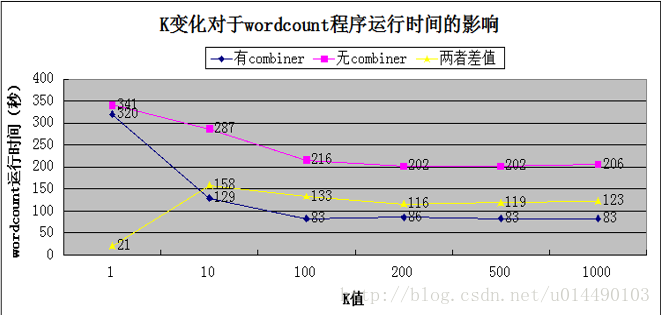
图1 K变化对于wordcount程序运行时间的影响
5.2. 对上述研究的思考
1. K=1时,有无combiner函数对于wordcount程序运行的时间影响很小;K不等于1时,有无combiner函数对于wordcount程序运行的时间影响非常显著。这说明,当输入文档中没有连续的重复单词时,combiner的作用几乎没有,combiner只在文档中有大量连续的重复单词时发挥作用。
2. 在K变大的过程中,有无combiner的情况下wordcount程序运行时间的差值不是一直增大的。
3. 有combiner时,wordcount运行时间基本上随K值增加而减小。这说明,输入文件中连续重复单词的数量越多,combiner发挥的作用也就越大。
4. 无combiner时,wordcount运行时间基本上随K值增加而减小。这说明,随着输入文件中连续重复单词的数量增加,reduce过程的耗时有所减少。
5. 无论K等于多少,有combiner函数时的wordcount用时总是比无combiner函数时要少。














 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









