









提升方法学习笔记
前言
提升方法是我在学习机器学习算法后最摸不着头脑的一个算法。看似它的思想很简单【三个臭皮匠,顶个诸葛亮】,但至于公式为什么是这样,权值为什么这么更新,实在令我不解。无奈翻阅了下adaboost的一篇论文,找到了一些线索,然数学水平不够,当论及PAC计算机学习理论时,无从下手。其中涉及到的内容相当多,如拓扑空间,测度理论等等,但秉承学习总结的一贯作风,我还是简单总结下,仅仅作为《统计学习方法》的学习笔记。
提升方法进阶一
书中第一段对提升方法已经有了很好的总结了,如下,对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。实际上,就是“三个臭皮匠顶个诸葛亮”的道理。
对应的模型思想如下图所示:
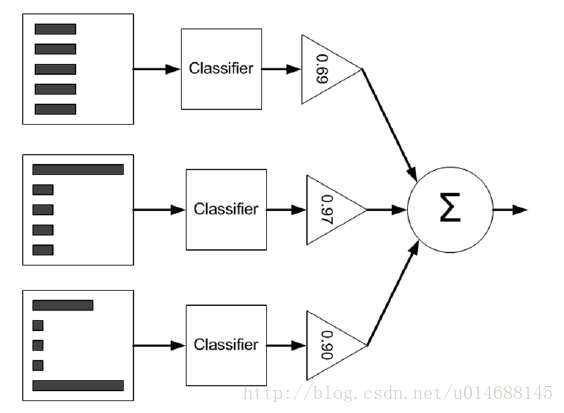
从图中我们就能看出,它其实一个加法模型,假设给定一个二元分类的训练数据集:
其中,每个样本点由实例与标记组成。实例 xi∈X⊆Rn ,标记 yi∈Y={−1,+1} , X 是实例空间, Y 是标记集合。那么提升算法的步骤是什么样子的呢?(adaboost步骤)我们先来有个感性的认识。
算法步骤很简单:
- 把收集到的数据集分为输入空间和输出空间,并对输入空间进行加权,由于是初始化过程,因此加权值为 1/N ,此处N为样本的总数量。
- 由classifier生成第一个模型的权值,记作 α1f1(x) ,如上图 α1=0.69 。
- 由第一个模型计算预测误差率,从而能够更新输入空间的权值,进一步又得到第二个模型的权值。
- 如此反复,直到最终的加权模型的损失函数达到指定精度,迭代停止。
如上图,所求得的最终模型为:
在上述算法中遗留着很多问题,倘若只需对提升算法有个感性的认识,那么看到这里已足矣。在这里,我能想到的一些问题有如下:
1. 上述算法能够收敛迭代的理论原因是什么?
2. 对输入空间加权分布如何能推得各种分类器的权重?
3. 多个弱分类器的加权累加就能变成一个有效的强分类器?
针对上面三个疑问,我尝试去理解并证明它,但发现它所需要的知识超出个人知识水平,因此,仅作为思考。在日后完善知识体系之后,回过头来再去解决这些遗留问题。但它所用到的数学知识和参考资料还是可以理出来的,有兴趣的读者可以直接搜索相关内容。
1984 Kearns & Valiant 提出了 PAC学习理论,A theory of the learnable. Communication of the ACM,1984,27(11):1134-1142
提出问题:
1. 强学习算法:存在一个多项式时间的学习算法以识别一组概念,且识别的正确率很高。
2. 弱学习算法:识别一组概念的正确率仅比随机猜测略好。
3. 弱学习器与强学习器的等价问题:如果两者等价,只需要找到一个比随机策略好的学习算法,就可以提升为强学习算法。
1990 Schapire第一个提出了可证明的多项式时间的Boosting算法,Schapire R. The strength of weak learnability. Machine learning,1990,5(2):197-227
1995 Adaboost算法横空出世,Freund Y,Schapire R. A decision-theoric generalization of on-line learning and an application to boosting.Computational learning Theory. Lecture Notes in Computer Science,Vol.904,1995,23-37
其中第二篇论文的引用量高达1.3万,可见它在统计学习中的地位,称它是统计学习中最有效的方法之一不足为过。
AdaBoost的诞生,和PAC理论有着密切的关系,在周志华《机器学习》中有提到计算机学习理论,更详细的可以参看一本小测子。
M.J.Kearns and U.V.Vazirani, “An introduction of Computational Learning Theory”,MIT Press,Cambridge,MA,1994.
需要强大的概率论,实分析测度理论等相关知识。实分析领域,目前正在研读一本《陶哲轩实分析》,有机会再来分享这些相关内容。在网上也搜刮到了一位大牛关于PAC的理解和测度理论的相关博客,请参看链接【Free Mind : 机器学习物语(4):PAC Learnability】及【Free Mind : 概率与测度 (1):关于测度】,无奈水平有限,暂未理解文中精髓。
提升方法进阶二
虽然搞不清前因后果,但并不妨碍我们去理解书中的公式,在这里,我们开始对该问题进行实际建模,一步步推得书中的公式及算法。这里推荐一篇博文【July : Adaboost 算法的原理与推导】,对书中的例子和公式描述的很详细,可参看。
我个人不太喜欢《统计学习方法》中关于提升算法的排版,直接给出Adaboost的一堆公式,实在让人摸不着头脑,何必呢?
前向分布算法
书中提到了一个加法模型:
是不是和上文中看到的加权模型很像?没错,它们其实就是一个东西。其中, b(x;γm) 称为基函数,你认为它是一个带参的函数就可以了,由训练数据训练得出, βm 为基函数的系数,可以简单理解为该基函数的信任权值。【你权威我给你分配的高点咯,你是老大我服你】
所有的统计学习方法,都是为了让数据去拟合咱们的给出的模型,那么该模型能否准确的表达这些数据呢,我们需要一个参照,即损失函数,同样,有了模型,我们便开始定义咱们的损失函数,如下:
在给定训练数据集及损失函数 L(y,f(x)) 的条件下,学习加法模型 f(x) 成为经验风险极小化即损失函数极小化问题。
遇到这样的损失函数还挺麻烦的,在逻辑回归,线性回归中的模型都是单纯的一堆数据集,只有一个模型。所以用简单的最小二乘法,就能把一堆参数以向量的形式用梯度下降算法or任何一种迭代算法即能求出来。但仔细观察这个式子,你会发现,每一步都会出现一组参数,这给迭代计算带来了极大的困难。所以,前向分布算法求解这一优化问题的想法是:因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近优化目标函数式,那么就可以简化优化的复杂度。
唉,说的的确很简单,但为什么是正确的呢?文中没有提及,而我自己也没法论证,但这思想的确非常出色,所以提出这些算法的牛人们,一个个都拿图灵奖了,而我等小菜只能观望,真是羡慕嫉妒恨啊。
具体地,每步只需要优化:
发现上式和上上式的区别了么?聪明的你一定观察到了,此处不再是一个加法模型了,而是其中可能的任何一个。So,我们开始定义我们的前向分布算法吧!
算法(前向分布算法)
输入:训练数据集 T=(x1,y1),(x2,y2),...,(xN,yN) ;损失函数 L(y,f(x)) ;基函数集 {b(x;γ)}
输出:加法模型 f(x)
(1) 初始化 f0(x)=0
(2) 对 m=1,2,...,M
(a) 极小化损失函数:
(βm,γm)=argminβ,γ∑i=1NL(yi,fm−1(xi)+βb(xi;γ))
得到参数 βm,γm
(b) 更新
fm(x)=fm−1(x)+βmb(x;γm)
(3) 得到加法模型
f(x)=fM(x)=∑m=1Mβmb(x;γm);
这样,前向分布算法将同时求解从m=1到M所有参数 βm,γm 的优化问题简化为逐次求解各个 βm,γm 的优化问题。
这是一个很神奇的算法,总共需要迭代M次,并且其中的每一次都需要各自再迭代求出参数值,求出的参数值将进一步被应用到下一次的迭代中,可谓是环环相扣。可看到这里,令我更加不可思议的是,它怎么就更AdaBoost算法联系在一起了!!!总结下就是【弱+弱+弱+…+弱 = 强】,其中有M个弱。
前向分布算法与AdaBoost的恩爱情仇
可以说AdaBoost是前向分布算法的特例,在上述算法中,我们并没有明确一个点,损失函数具体是什么?之前以为损失函数的定义最理想的就是最小二乘法,但其实损失函数可以有很多种,每种都有自己特定的应用,如此处AdaBoost算法所用的损失函数为指数函数。这又是一个可以深入挖掘的课题。
吼吼,接下来便开始AdaBoost算法的推导过程吧。【从前向分布算法来,而并非来源于作者最初的思想,注意区分!这中间还差n个水平】
我们把AdaBoost算法的最终分类器拿来和加法模型类比下:
它俩差多少?基本没差吧,自行比较下就可以了。接下来就是明确损失函数了,此处用的损失函数为指数损失函数(exponential loss function)
为什么使用指数损失函数?这个问题着实不好回答,因为在AdaBoost设计之处可能就是用了损失函数,从而推出了一系列的公式。但我们是可以验证指数函数是否符合损失函数的定义。 y∗f(x) 的形式是相当特殊的,尤其在针对分类问题时,它能呈现它的强大之处。如二元分类问题中 Y∈{+1,−1} ,所以 y∗f(x) 的形式可以化简为 f(x) ,那么损失函数的大小只跟 f(x) 的取值有关了,我们来分析下指数损失函数的正确性吧,假设 f(x)∈[−1,1] ,此处为模型输出的值域。可以分为两种情况【分类成功】和【分类失败】
分类成功
分类成功时,
y和f(x)
同号,所以
y∗f(x)>0
,那么
f(x)
的正确分类的可信度越高,指数损失函数的值将越低。
分类失败
分类失败时,
y和f(x)
异号,所以
y∗f(x)<0
,那么
f(x)
的错误分类的可信度越高,指数损失函数的值将越高。
它符合了损失函数的定义,因此,我们便可以拿来做进一步的推导了,当然你说用对数损失函数可不可以?或者平均损失函数?我觉得是完全没问题的,但只能说由这些损失函数推得的算法,我们估计要重新命名了,不能再叫AbaBoost算法。
AdaBoost算法公式推导
假设经过
m−1
轮迭代前向分布算法已经得到
fm−1(x)
,典型的数学归纳法,多米诺骨牌。因为前文已经给出结论,说从m-1次迭代能够推得第m次迭代,且第m次的迭代后,损失函数将进一步减小。所以,设计算法时,我们只需要假设第m-1次的参数已知,从而去求第m次的参数,那么不管是用递归算法还是迭代算法,都能求得最终所有参数的结果。
在第
m
轮迭代需得到
目标是使前向分布算法得到的 αm和Gm(x)使fm(x) 在训练数据集T上的指数损失函数最小,即
那么无非就开始对公式求导咯,让偏导等于0,就能求出各个参数了呗。不过,在这里可以发现一个指数函数的细节,对加法模型,指数函数的已知参数能够完全移到指数外,非常优美的性质,所以上式可以表达为:
为了分析方便,我们暂且令
w¯¯¯mi=exp[−yifm−1(xi)]
,它到底是个什么东西?不管他,数学公式的中间产物罢了。但还是可以有个感性认识,它和第m-1次的模型有关,且作用于每个样本。所以,公式又变成了如下:
我们先来求解
G∗m(x)
。对任意
α>0
,可得:
提升算法进阶三
这一部分内容我得单独拎出来,这是理解提升算法的核心之核心。
上式是AdaBoost的关键步骤,你会发现求解 G∗m(x) 时,它并没有用定义的指数损失函数,而是变换到了指示损失函数。这点实在是太巧妙了!正因为这一点简单的变化,使得系数 α 能够求解出来,从而得到了一个完美的加权模型。它是如何思考的?好的,我们尝试去构建一下。首先,需要明确adaBoost的宗旨是什么,是由上一个模型的输出,求得下一个误差分布!!!再由这个误差分布,去衡量此时此刻第M次迭代模型的损失函数。
我们再来观察一下式子:
这时候,我们该明确 w¯¯¯mi 的物理含义了,看看它的导出式,每个样例 i 的损失函数,这点没错吧。所以,
这点没有任何问题吧,我们是把第m-1次的损失信息代入到了第m次迭代当中,我们甚至可以把这个式子命名为经验损失函数,其实就是期望。这个G函数怎么求?求偏导,等式等于0,从而求出
Gm(x)
中的待定系数。你会遇到很大的麻烦,不信你试试。adaBoost并没有那么做,而是充分利用了
Gm(xi)
的函数特性,
Gm(x)只能取{+1,−1}
。所以,进一步的,我们把上述公式用另外一个损失函数给替换掉了,如下:
此处,绝了!真的太巧妙了,上述两个式子求出来的参数是等价的,简单说明下,数据可以被简单切分为【正确分类】和【错误分类】
对于正确分类:
1. 指数损失函数表达式为:
∑i被正确分类w¯¯¯mi∗e−1
2. 指示损失函数表达式为:
∑i被正确分类w¯¯¯mi∗0
对于错误分类:
1. 指数损失函数表达式为:
∑i被错误分类w¯¯¯mi∗e1
2. 指示损失函数表达式为:
∑i被错误分类w¯¯¯mi∗1
两者不管是错误分类还是正确分类都一一对应吧?随着样本数的增加,损失函数不断增加,都属于递增函数,而且更重要的一点是,指数损失函数的递增量总比指示函数的递增量多。但不管怎么样,上述性质给了我们一个很好的等价式,即我们只需要求解令指示函数最小的弱分类器
Gm(x)
。所以有了书中令人一时疑惑的公式:
但我们求出第m次的单个弱分类器 Gm(x) 还不够,因为,我们是需要求解出整个综合模型的各种参数,所以问题又回到了求解:
只不过问题变简单了而已,因为我们已经求解出了 G∗m(x) 了,现在只需要明确另外一个参数 α ,算法就完成了。
既然有了
G∗m(x)
,同样的,把数据分为【正确分类】和【错误分类】,我们来继续探寻下:
由于待求系数
α
独立,所以我们可以对它进行求导,并令其偏导为0,于是得:
现在只需要根据等式求解出 α 即可。这里还需要注意一点, w¯¯¯mi 的和是可能大于1的,所以为了求解的方便,我们将其归一化,所以,我们引入了误差分类率 em :
注意,这里摘了一个小帽子哦。所以求导式就可以写成:
解得:
有了 α∗m 整个模型不就出来了嘛!所以它就像个多米诺骨牌一样,当给定初始权值分布 w1i ,就能求出相应的 e1 ,便能确定 α1及G1(x) 。至于为什么每一次迭代,损失函数不断减小,那就超出我的水平了,暂时无法解释。
简单总结下,【指数损失函数】在【加法模型】中的应用,是我认为最为巧妙的地方。它很好的模拟了boosting算法的核心思想【三个臭皮匠,顶个诸葛亮】,每一次迭代,把上一轮的每个样例的损失分布代入到了下一轮,并且在本轮对 G(x) 进行参数学习,难道这就是所谓的记忆模型?起码经验被代入下一轮迭代完完全全有指数函数造成的。至于说为什么取底数 e ,我觉得很大一部分原因在于它求导的方便。详细的AdaBoosting算法,请参考《统计学习方法》P138-142,此处不在赘述了。
Code Time
接下来,我们来看看一个具体的adaBoost算法,加深印象吧,毕竟公式
没有告诉你具体的 G∗m(x) 怎么求,而是用arg一笔带过了。更合理的还是应该表示成 G∗m(x;γm) 。而 G∗m(x;γm) 的求解可以自成体系,无关乎adaBoost。如决策树中,对于slice的划分,完全可以用平方差损失函数来衡量。但书中关于提升树的例子着实不能理解,怎么加权值都没有了?且损失函数的衡量直接变成了平方差,那adaBoost的意义何在?这里就拿《机器学习实战》中的提升树来具体操作一把吧,书中的例子可以暂且略过,否则只会更加迷糊。
生成数据
def loadSimpeData():
"""
加载简单数据集
:return:
"""
datMat = np.matrix([[1., 2.1],
[2., 1.1],
[1.3, 1.],
[1., 1.],
[2., 1.]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
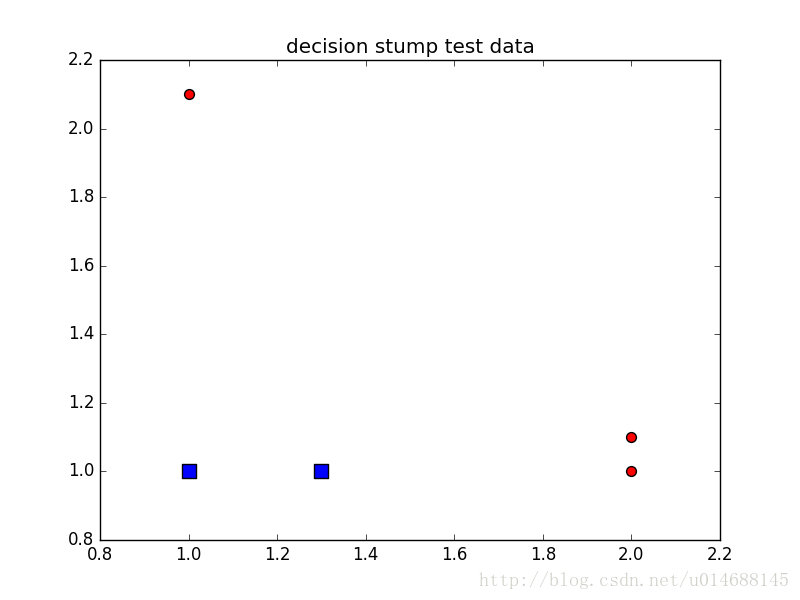
return datMat, classLabels可视化数据
def plotData(datMat, classLabels):
xcord0 = []
ycord0 = []
xcord1 = []
ycord1 = []
for i in range(len(classLabels)):
if classLabels[i]==1.0:
xcord1.append(datMat[i,0]), ycord1.append(datMat[i,1])
else:
xcord0.append(datMat[i,0]), ycord0.append(datMat[i,1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord0,ycord0, marker='s', s=90)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
plt.title('decision stump test data')
plt.show()如下图所示:
单层决策树分类
def stumpyClassify(dataMartix,dimen,threshVal,threshIneq):
"""
:param shape(dataMatrix)[0]: 取总样本数
"""
retArray = np.ones((np.shape(dataMartix)[0],1))
if threshIneq == 'lt':
retArray[dataMartix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMartix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
"""
:param m,n: 样本数量,特征数量
"""
dataMatrix = np.mat(dataArr)
labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0
bestStump = {}
bestClasEst = np.mat(np.zeros((m,1)))
minError = float("inf") # 将错误率之和设为正无穷
for i in range(n): # 遍历所有维度
rangeMin = dataMatrix[:,i].min()
rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax - rangeMin) / numSteps
for j in range(-1,int(numSteps) + 1):
for inequal in ['lt','gt']:
threshVal = (rangeMin + float(j)*stepSize)
predictedVals = stumpyClassify(dataMatrix,i,threshVal,inequal)
errArr = np.mat(np.ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr
print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst控制台输入:
dataMat,classLabels = loadSimpleData()
D = np.mat(np.ones((5,1))/5)
bestStump,minError,bestClasEst = buildStump(dataMat,classLabels,D)输出:
({'dim': 0, 'thresh': 1.3, 'ineq': 'lt'}, matrix([[ 0.2]]), array([[-1.],
[ 1.],
[-1.],
[-1.],
[ 1.]]))简单说明下,上面的工作其实就是求某个弱分类器中的
G∗m(x;γm)
中的
γm
参数,在单层决策树中,它只对一维特征进行划分,上述结果表明对第0维特征,且阈值设在1.3,整体的分类误差最小。用公式可以表示为:
AdaBoost训练核心代码
def adaBoostTrainDs(dataArr,classLabels,numIt = 40):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m,1))/m)
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
# print("D:",D.T)
alpha = float(0.5 * math.log ((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) # 保存树桩决策树
expon = np.multiply(-1 * alpha * np.mat(classLabels).T,classEst)
res = np.mat([math.exp(x) for x in expon])
D = np.multiply(D,res.T)
D = D / D.sum()
# 计算所有分类器的误差,如果为0则终止训练
aggClassEst += alpha * classEst
# print("aggClassEst:",aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T,np.ones((m,1)))
errorRate = aggErrors.sum() / m
print ("total error:",errorRate)
if errorRate == 0.0: break
return weakClassArr,aggClassEst上述过程对应了系数 α 的求解,误差权值 wmi 的计算,以及整个adaBoost迭代过程。
提升树分类
def adaClassify(dataToClass,classifierArr):
dataMatrix = np.mat(dataToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], \
classifierArr[i]['thresh'], \
classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
return np.sign(aggClassEst)控制台输入:
dataMat,classLabels = loadSimpleData()
D = np.mat(np.ones((5,1))/5)
classifierArr,aggClassEst = adaBoostTrainDs(dataMat,classLabels)
print (adaClassify([0, 0], classifierArr))控制台输出:
total error: 0.2
total error: 0.2
total error: 0.0
[[-1.]]上述的数据集相对简单,我们再来看看《机器学习实战》中给出的复杂数据集:horseColicTraining2.txt
加载训练代码
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t'))
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
datArr, labelArr = loadDataSet("horseColicTraining2.txt")
classifierArr, aggClassEst = adaBoost.adaBoostTrainDs(datArr, labelArr, 10)我们可以直接将aggClassEst打印出来观察对训练集的预测结果,但这样太抽象,而且我们希望计算准确率和召回率,特别是在测试集上的准确率和召回率。
准确率与召回率
对于二元分类问题:
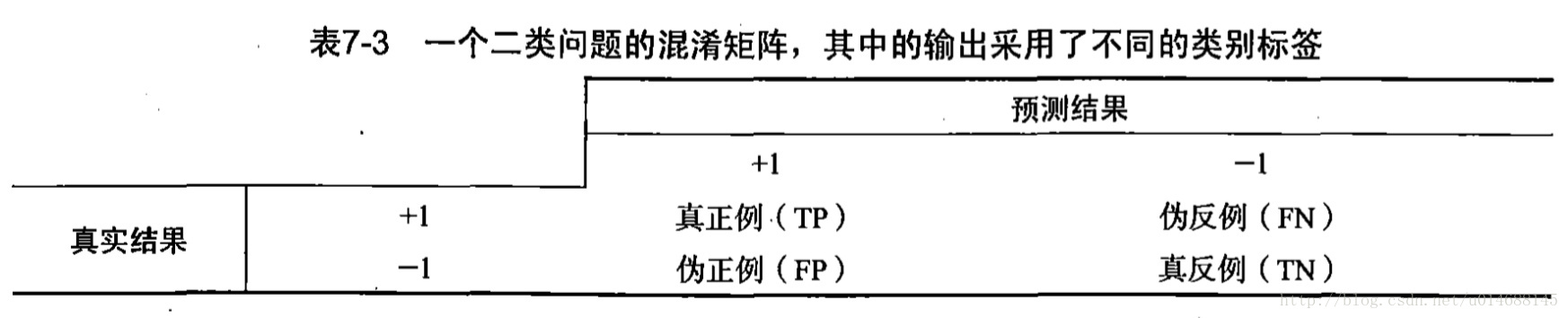
准确率的计算方法为
TP / (TP + FP)召回率的计算方法为
TP / (TP + FN)计算准确率与召回率
import adaBoost
import numpy as np
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t'))
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
def evaluate(aggClassEst, classLabels):
"""
计算准确率与召回率
:param aggClassEst:
:param classLabels:
:return: P, R
"""
TP = 0.
FP = 0.
TN = 0.
FN = 0.
for i in range(len(classLabels)):
if classLabels[i] == 1.0:
if (np.sign(aggClassEst[i]) == classLabels[i]):
TP += 1.0
else:
FP += 1.0
else:
if (np.sign(aggClassEst[i]) == classLabels[i]):
TN += 1.0
else:
FN += 1.0
return TP / (TP + FP), TP / (TP + FN)
def train_test(datArr, labelArr, datArrTest, labelArrTest, num):
classifierArr, aggClassEst = adaBoost.adaBoostTrainDS(datArr, labelArr, num)
prTrain = evaluate(aggClassEst, labelArr)
aggClassEst = adaBoost.adaClassify(datArrTest, classifierArr)
prTest = evaluate(aggClassEst, labelArrTest)
return prTrain, prTest
datArr, labelArr = loadDataSet("horseColicTraining2.txt")
datArrTest, labelArrTest = loadDataSet("horseColicTest2.txt")
prTrain, prTest = train_test(datArr, labelArr, datArrTest, labelArrTest, 10)
print (prTrain, prTest)控制台输出:
(0.8595505617977528, 0.7766497461928934) (0.7872340425531915, 0.8604651162790697)事实上,通过调整分类器的数量(train_test的最后一个参数),可以得到不同的性能。《机器学习实战》验证了1到10000个分类器的错误率:

上图说明分类器并不是越多越好,50是个最好的值,过了这个值,模型发生过拟合,性能越来越低。
ROC曲线
给定分类器在某个数据集上的输出,我们就能计算出假阳率与真阳率,这两个值决定一个坐标点。以假阳率作为x轴,真阳率作为y轴,制定坐标系。
完美的分类器应该是左上角那个点,分类器越接近左上角,就越完美。这样我们就可以较为直观地比较两个不同的分类器了。
在决策函数中,我们使用的是sign来二值化预测强度,以得到最终分类。也就是说,我们取的阈值是0。分类强度离阈值越远,分类的可信度越高。如果我们改变阈值,我们就能得到同一个分类器在坐标系中不同的点,将它们按照阈值大小顺序连成线,就能得到一条ROC曲线。完美的分类器的ROC曲线应该是正方形的左上角对应的两条边,而随机猜测的ROC曲线则是连接左下角与右上角的一条直线。ROC曲线下的面积(AUC)反映了分类器的平均性能。
ROC曲线绘制代码
def plotROC(predStrengths, classLabels):
import matplotlib.pyplot as plt
cur = (1.0, 1.0) # 中间变量,初始状态为右上角
ySum = 0.0 # variable to calculate AUC
numPosClas = sum(np.array(classLabels) == 1.0) # TP
yStep = 1 / float(numPosClas)
xStep = 1 / float(len(classLabels) - numPosClas)
sortedIndicies = predStrengths.argsort() # 按元素值排序后的下标,逆序
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
# 遍历所有的值
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0: # 预测正确
delX = 0 # 真阳率不变
delY = yStep # 假阳率减小
else:
delX = xStep
delY = 0
ySum += cur[1] # ROC面积的一个小长条
# 从 cur 到 (cur[0]-delX,cur[1]-delY) 画一条线
ax.plot([cur[0], cur[0] - delX], [cur[1], cur[1] - delY], c='b')
cur = (cur[0] - delX, cur[1] - delY)
ax.plot([0, 1], [0, 1], 'b--') # 随机猜测的ROC线
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0, 1, 0, 1])
plt.show()
print ("the Area Under the Curve is: ", ySum * xStep)
datArr, labelArr = loadDataSet("horseColicTraining2.txt")
classifierArr, aggClassEst = adaBoost.adaBoostTrainDS(datArr, labelArr, 10)
plotROC(aggClassEst.T, labelArr)效果:
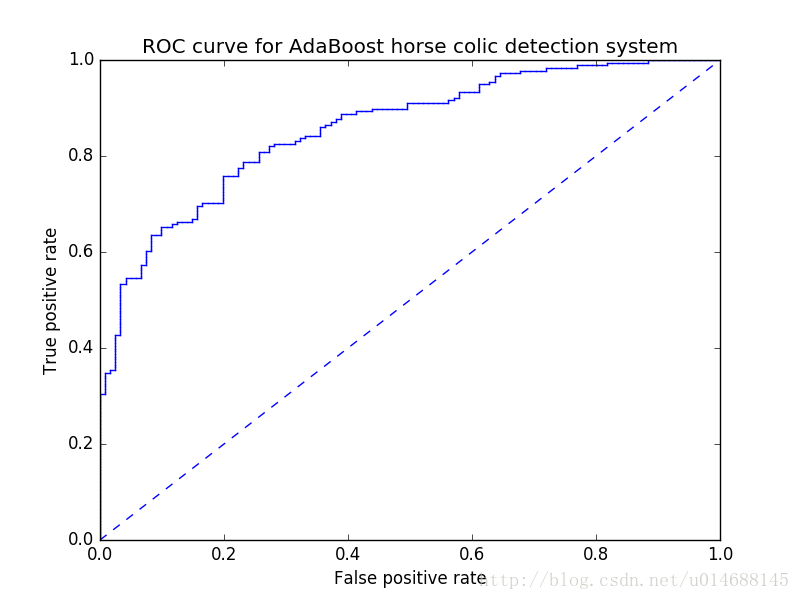
随机猜测的ROC曲线是一条y=x直线,这是因为对真阳率和假阳率相等,意味着分类器猜对和猜错的比率相等,说明该分类器就是在随机猜。以上部分内容摘自博文【码农场-提升方法】。
提升方法进阶四
未完待续……
参考文献
- Free Mind : 机器学习物语(4):PAC Learnability
- Free Mind : 概率与测度 (1):关于测度
- July : Adaboost 算法的原理与推导
- 李航. 统计学习方法[M]. 北京:清华大学出版社,2012
- Peter Harrington. Machine Learning in Action[M]. 北京:人民邮电出版社,2013














 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









