







词法分析器作为编译器的一个重要组成部分,原理很简单,代码也都没什么技术含量,但是如果让你手工写一个词法分析器,哪怕是一个简单的词法分析器,工作量无疑是巨大的。现代的词法分析器一般都是依靠工具自动生成,这里我们选用flex生成词法分析器,下面是用到的flex的下载地址。windows的环境的话,lex.exe文件使我们所需要的工具。里面的帮助文档将教会你如何更好的使用flex。
学习编译原理并非一定要做一个完美的编译器,我们所需要的只是了解编译器的工作原理并能运用这些特性写出更高效合法的程序,因此我们只用lex的一些简单功能写一个简单的词法分析器来印证我们所学的知识。下图是lex的使用步骤简要说明:
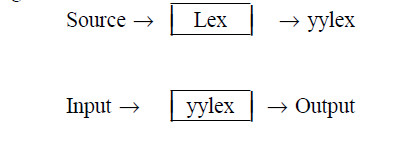
这里的源文件是符合lex的语句,flex 的输入文件由三段组成,用一行中只有%%来分隔。
定义;definition
%%
规则;rules
%%
用户代码;code
这个源文件输出的就是词法分析器的C语言源程序,编译这个.c的源程序生成的就是你所定义语言的词法分析器。
这里我们用一个简单的例子来做一个简单的词法分析器,词法规则符合《编译原理及实践教程》中描述的sample语言。
下面是Source文件
%{
#include<math.h>
#include<stdlib.h>
#include<stdio.h>
%}
DIGIT [0-9]
ID [a-z][a-z0-9]*
%%
{DIGIT}+ {printf("整数: %s(%d)\n",yytext,atoi(yytext));}
{DIGIT}+"."{DIGIT}+ {printf("实数: %s(%g)\n",yytext,atof(yytext));}
if|then|begin|end|program|while|repeat {printf("关键字: %s\n",yytext);}
{ID} {printf("标识符: %s\n",yytext);}
"+"|"-"|"*"|"/" {printf("运算符: %s\n",yytext);}
"{"[^}\n]*"}";
[\t\n\x20]+;
. {printf("不能识别的字符:%s\n",yytext);}
%%
int main(int argc,char **argv)
{
++argv;
--argc;
if(argc>0) yyin=fopen(argv[0],"r");
else yyin=stdin;
yylex();
return 0;
}
int yywrap()
{
return 1;
}这里我们把Source源文件保存为lex.l
通过在命令行模式下输出命令 lex lex.l 生成lex.yy.c文件,这就是我们的词法分析器的源代码了,打开看看,吃惊吧,这么简单的语言的词法分析程序竟然需要这么多代码,还好我们不用手工写。编译这个源程序,得到 lex.yy.exe,测试一下
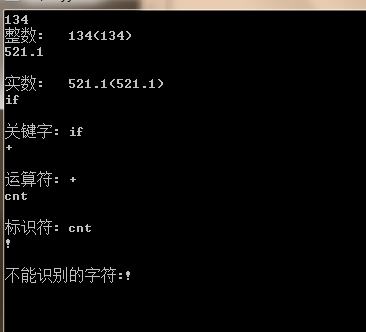
OK,简单词法分析器就完成了。
欢迎转载,转载注明出处














 1126
1126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









