








图的遍历
定义:从图中的某一顶点出发,沿着一些边访遍图中所有的顶点,使得每个顶点仅被访问一次。
图的遍历算法是求解图的连通性问题、拓扑排序和求关键路径等算法的基础。
然而,图的遍历要比树的遍历复杂的多。因为图的任一顶点都可能和其余的顶点相邻接。所以在访问了某个顶点后,可能沿着某条路径搜索之后,又回到该顶点上。为了避免同一个顶点被访问多次,在遍历图的过程中,必须记下每个已访问过的顶点。为此,我们可以设一个辅助数组visited[],它的初始值为“假”或者零,一旦访问了顶点vi,便置visited[i]为“真”或者为被访问时的次序号。
通常有两条遍历图的路径:深度优先搜索和广度优先搜素。
1. 深度优先搜索
深度优先搜索遍历类似于树的前序遍历,是树的前序遍历的推广。
假设初始状态是图中的所有顶点都没有被访问,则深度优先搜索可以从图中某个顶点v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。显然,这是一个递归的过程。
算法描述总结如下:
1.访问起始顶点v
1.1当v还有邻接顶点未访问时
1.1.1.深度遍历未访问过的邻接顶点w
1.2.当v的所有邻接顶点都被访问时
1.2.1.若图中所有顶点均已访问,算法结束
1.2.2.若图中还有未访问的顶点,以未访问顶点作为起始顶点深度遍历。
示例:
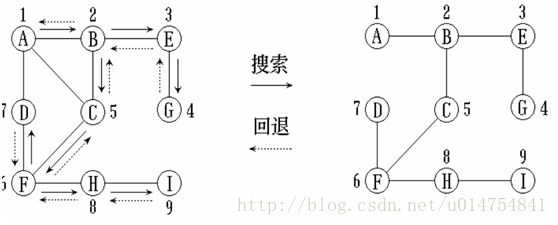
为了在遍历过程中便于区分顶点是否已被访问,需设一个辅助数组visited[],它的初始值为“假”或者零,一旦访问了顶点vi,便置visited[i]为“真”。
下面我们讲解一下实现代码,我们都知道图的实现有两种方式:邻接矩阵法和邻接链表法。所以这里分别讲解这两种实现方式的遍历算法。
邻接链表法图的遍历的实现代码
// 深度优先搜索遍历图
void LGraph_DFS(LGraph* graph, int v, LGraph_Printf* pFunc)
{
// 定义图结点结构体变量,并强制转换入口参数
TLGraph* tGraph = (TLGraph*)graph;
// 定义辅助访问数组,标记已被访问的顶点
int* visited = NULL;
// 参数合法性检查
int condition = (tGraph != NULL);
condition = condition && (0 <= v) && (v < tGraph->count);
condition = condition && (pFunc != NULL);
// 为辅助访问数组申请内存空间、并且初始化为0
condition = condition && ((visited = (int*)calloc(tGraph->count, sizeof(int))) != NULL);
// 参数合法性OK
if( condition )
{
int i = 0;
// 调用深度优先搜索递归函数,访问顶点
recursive_dfs(tGraph, v, visited, pFunc);
// v的所有邻接顶点都被访问
// 遍历辅助访问数组
for(i=0; i<tGraph->count; i++)
{
// 图中还有未访问的顶点,以未访问顶点作为起始顶点深度遍历
// 否则结束遍历算法
if( !visited[i] )
{
recursive_dfs(tGraph, i, visited, pFunc);
}
}
printf("\n");
}
// 释放申请的辅助访问数组空间
free(visited);
}前面提到过,深度优先搜索算法是一个递归的过程,所以我们还得实现一个递归函数
深度优先搜索递归函数
// 深度优先搜索递归函数
static void recursive_dfs(TLGraph* graph, int v, int visited[], LGraph_Printf* pFunc)
{
int i = 0;
// 访问起始顶点v
pFunc(graph->v[v]);
// 标记已访问的顶点
visited[v] = 1;
printf(", ");
// 遍历该顶点的所有邻接点
for(i=0; i<LinkList_Length(graph->la[v]); i++)
{
TListNode* node = (TListNode*)LinkList_Get(graph->la[v], i);
// 当v还有邻接顶点未访问时,深度遍历未访问过的邻接顶点
if( !visited[node->v] )
{
recursive_dfs(graph, node->v, visited, pFunc);
}
}
}邻接矩阵法图的遍历算法实现代码
// 深度优先搜索遍历图
void MGraph_DFS(MGraph* graph, int v, MGraph_Printf* pFunc)
{
// 定义图结点结构体变量,并强制转换入口参数
TMGraph* tGraph = (TMGraph*)graph;
// 定义辅助访问数组,标记已被访问的顶点
int* visited = NULL;
// 参数合法性检查
int condition = (tGraph != NULL);
condition = condition && (0 <= v) && (v < tGraph->count);
condition = condition && (pFunc != NULL);
// 为辅助访问数组申请内存空间、并且初始化为0
condition = condition && ((visited = (int*)calloc(tGraph->count, sizeof(int))) != NULL);
// 参数合法性OK
if( condition )
{
int i = 0;
// 调用深度优先搜索递归函数,访问顶点
recursive_dfs(tGraph, v, visited, pFunc);
// v的所有邻接顶点都被访问
// 遍历辅助访问数组
for(i=0; i<tGraph->count; i++)
{
// 图中还有未访问的顶点,以未访问顶点作为起始顶点深度遍历
// 否则结束遍历算法
if( !visited[i] )
{
recursive_dfs(tGraph, i, visited, pFunc);
}
}
// 释放申请的辅助访问数组空间
printf("\n");
}
free(visited);
}不管是什么方法实现的图,它的深度优先遍历图的算法不会改变,所以邻接矩阵法和邻接链表法遍历实现基本相似,不同的是深度优先搜索递归函数的实现不同,下面看一下邻接矩阵法的深度优先搜索递归函数
// 深度优先搜索递归函数
static void recursive_dfs(TMGraph* graph, int v, int visited[], MGraph_Printf* pFunc)
{
int i = 0;
// 访问起始顶点v
pFunc(graph->v[v]);
// 标记已访问的顶点
visited[v] = 1;
printf(", ");
// 遍历顶点v的所有邻接点
for(i=0; i<graph->count; i++)
{
// 当v还有邻接顶点未访问时,深度遍历未访问过的邻接顶点
if( (graph->matrix[v][i] != 0) && !visited[i] )
{
recursive_dfs(graph, i, visited, pFunc);
}
}
}通过比较两种方法的递归函数我们发现,邻接链表法遍历顶点v的所有邻接点是从链表中获取的,而邻接矩阵法直接取出二维数组矩阵的相应位置权值为1的位置即可。
分析上述算法,在遍历图时,对图中每个顶点至多调用一次递归函数,因此一旦某个顶点被标志成已被访问,就不再从它出发进行搜索。因此,遍历图的过程实质上是对每个顶点查找其邻接点的过程。其耗时的时间取决于所采用的存储结构。显然,使用邻接矩阵法时其时间复杂度为O(n2);邻接链表法的时间复杂度为O(n)。
2. 广度优先搜索
广度优先搜索遍历类似于树的按层次遍历过程。
假设从图中某顶点v出发,在访问了v之后一次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问他们的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有的顶点都被访问到为止。换句话说,广度优先搜索遍历图的过程是以v为起始点,由近至远,依次访问和v有路径相通且路径长度为1,2,…的顶点。
和深度优先搜索类似,在遍历的过程中也需要一个访问标志数组。并且,为了顺次访问路径长度为2、3、…的顶点,还需设队列以存储已被访问的路径长度为1、2、…的顶点,广度优先遍历的算法总结如下:
算法描述:
1.访问起始顶点v0;
2. 依次访问v0的各个邻接点v01,v02,…,v0x;
3. 假设最近一次访问的顶点依次为vi1,vi2,…,viy,则依次访问vi1,vi2,…,viy的未被访问的邻接点;
4. 重复3,直到所有顶点均被访问。
示例:
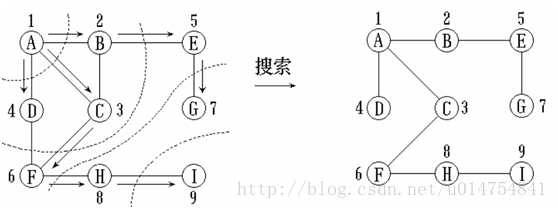
同深度优先搜索法一样,这里也分别讲解两种实现代码:
邻接链表法图的遍历算法实现代码
// 广度优先搜索遍历图
void LGraph_BFS(LGraph* graph, int v, LGraph_Printf* pFunc)
{
// 定义图结点结构体变量,并强制转换入口参数
TLGraph* tGraph = (TLGraph*)graph;
// 定义辅助访问数组,标记已被访问的顶点
int* visited = NULL;
// 参数合法性检查
int condition = (tGraph != NULL);
condition = condition && (0 <= v) && (v < tGraph->count);
condition = condition && (pFunc != NULL);
// 为辅助访问数组申请内存空间、并且初始化为0
condition = condition && ((visited = (int*)calloc(tGraph->count, sizeof(int))) != NULL);
// 参数合法性OK
if( condition )
{
int i = 0;
// 调用广度优先搜索函数
bfs(tGraph, v, visited, pFunc);
// 图中尚有顶点未被访问,则以该顶点继续调用广度优先搜素函数
for(i=0; i<tGraph->count; i++)
{
if( !visited[i] )
{
bfs(tGraph, i, visited, pFunc);
}
}
printf("\n");
}
// 释放申请的辅助访问数组空间
free(visited);
}广度优先搜索算法函数(邻接链表法)
// 广度优先搜素算法函数
static void bfs(TLGraph* graph, int v, int visited[], LGraph_Printf* pFunc)
{
// 创建辅助队列
LinkQueue* queue = LinkQueue_Create();
// 创建成功
if( queue != NULL )
{
// 将起始顶点v入队
LinkQueue_Append(queue, graph->v + v);
// 标记起始顶点v已被访问
visited[v] = 1;
// 访问顶点v
while( LinkQueue_Length(queue) > 0 )
{
int i = 0;
// 出队并打印
v = (LVertex**)LinkQueue_Retrieve(queue) - graph->v;
pFunc(graph->v[v]);
printf(", ");
// 依次访问顶点v的的邻接点
for(i=0; i<LinkList_Length(graph->la[v]); i++)
{
TListNode* node = (TListNode*)LinkList_Get(graph->la[v], i);
// 顶点v尚有未被访问的邻接点
if( !visited[node->v] )
{
// 将顶点v入队
LinkQueue_Append(queue, graph->v + node->v);
// 标记起始顶点v已被访问
visited[node->v] = 1;
}
}
}
}
// 销毁创建的辅助队列
LinkQueue_Destroy(queue);
}通过分析代码,我们发现这里和深度优先搜索优点不一样,使用到了队列,队列有关内容参考队列的链表实现。
邻接矩阵法图的遍历算法实现代码
// 广度优先搜索遍历图
void MGraph_BFS(MGraph* graph, int v, MGraph_Printf* pFunc)
{
// 定义图结点结构体变量,并强制转换入口参数
TMGraph* tGraph = (TMGraph*)graph;
// 定义辅助访问数组,标记已被访问的顶点
int* visited = NULL;
// 参数合法性检查
int condition = (tGraph != NULL);
condition = condition && (0 <= v) && (v < tGraph->count);
condition = condition && (pFunc != NULL);
condition = condition && (0 <= v) && (v < tGraph->count);
condition = condition && (pFunc != NULL);
// 为辅助访问数组申请内存空间、并且初始化为0
condition = condition && ((visited = (int*)calloc(tGraph->count, sizeof(int))) != NULL);
// 参数合法性OK
if( condition )
{
int i = 0;
// 调用广度优先搜索函数
bfs(tGraph, v, visited, pFunc);
// 图中尚有顶点未被访问,则以该顶点继续调用广度优先搜素函数
for(i=0; i<tGraph->count; i++)
{
if( !visited[i] )
{
bfs(tGraph, i, visited, pFunc);
}
}
printf("\n");
}
// 释放申请的辅助访问数组空间
free(visited);
}通过分析上面代码我们发现,邻接矩阵法和邻接链表法的实现方式几乎一样,这是因为算法没有变。
广度优先搜索算法函数(邻接矩阵法)
// 广度优先搜索算法函数
static void bfs(TMGraph* graph, int v, int visited[], MGraph_Printf* pFunc)
{
// 创建辅助队列
LinkQueue* queue = LinkQueue_Create();
// 创建成功
if( queue != NULL )
{
// 将起始顶点v入队
LinkQueue_Append(queue, graph->v + v);
// 标记起始顶点v已被访问
visited[v] = 1;
// 访问顶点v
while( LinkQueue_Length(queue) > 0 )
{
int i = 0;
// 出队并打印
v = (MVertex**)LinkQueue_Retrieve(queue) - graph->v;
pFunc(graph->v[v]);
printf(", ");
// 依次访问顶点v的的邻接点
for(i=0; i<graph->count; i++)
{
// 顶点v尚有未被访问的邻接点
if( (graph->matrix[v][i] != 0) && !visited[i] )
{
// 将顶点v入队
LinkQueue_Append(queue, graph->v + i);
// 标记起始顶点v已被访问
visited[i] = 1;
}
}
}
}
// 销毁创建的辅助队列
LinkQueue_Destroy(queue);
}分析上述算法,每个顶点至多进一次队列。遍历图的过程实质上是通过边或弧找邻接点的过程,因此广度优先搜素遍历图复杂度和深度优先搜素遍历相同,两者不同之处仅仅在于对顶点访问的顺序不同。
代码详请见:邻接链表法实现图C代码和邻接矩阵法实现图C代码
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









