










配置的方法主要是对于节点的分配,与修改配置文件,按照一定的顺序启动即可。
不多说,先上角色分配表(3台机器)
多台机器请自行分配
| 节点 | 分配的角色 |
|---|---|
| Hadooplee1 | Namenode、datanode、resoucemanager、DFSZKFailorController、nodemanager、zookeeper |
| Hadooplee2 | Namenode、datanode、resoucemanager、DFSZKFailorController、nodemanager、zookeeper |
| Hadooplee3 | datanode、nodemanager、zookeeper 、journalnode |
可以实现Namenode的故障自动切换。
第一步:搭建zookeeper集群
zookeeper集群的搭建见我的另一篇文章:
第二步:搭建hadoop集群
hadoop集群的搭建见我的另一篇文章:
第三步:修改配置文件:
主要配置如下:
core-site.xml(注意要删掉我的注释)
<!-- Put site-specific property overrides in this file. -->
<configuration>
Nameservice的名字在hdfs-site中定义就可以,名字一定要一致
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.7.2/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<!-- zookeeper site -->
Zookeeper集群的地址与端口
<property>
<name>ha.zookeeper.quorum</name>
<value>hadooplee1:2181,hadooplee2:2181,hadooplee3:2181</value>
</property>
</configuration>
hdfs-site.xml(注意要删掉我的注释)
<configuration>
<!--nameservice 的名字,一定要与 core-site中的一致,否则出现问题-->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
Nameservice有两个节点 nn1 和nn2
<!-- ns have two NameNode,nn1 and nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- namenode1 RPC address -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadooplee1:9000</value>
</property>
<!-- namenode1 http address -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadooplee1:50070</value>
</property>
<!-- namenode2 RPC address -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadooplee2:9000</value>
</property>
<!-- namenode2 http address -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadooplee2:50070</value>
</property>
这里配置namenode的目录,必须配置,否则出现不可测错误
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
Nomenode在journalnode的目录
<!-- NameNode data on JournalNode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadooplee3:8485/ns1</value>
</property>
<!-- JournalNode dir -->
Journalnode的本地目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journaldata</value>
</property>
开启自动ha切换
<!--ha auto switch -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
切换方式
<!-- switch way -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
切换方法
<!-- switch method -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
配置ssh的key,必须实现免密钥登陆,否则出错
<!-- ssh key-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--time-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
yarn-site.xml(注意要删掉我的注释)
<configuration>
开启ha
<!-- ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
Resoucemanage的id
<!--RMcluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
声明resoucemanager
<!-- RM id -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
Resoucemanager的地址
<!-- RM address -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadooplee1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadooplee2</value>
</property>
Zookeeper的地址与端口
<!-- zookeeper address -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadooplee1:2181,hadooplee2:2181,hadooplee3:2181</value>
</property>
</configuration>
第四步:启动步骤
启动zookeeper,并检查zookeeper的状态,如果出错,会造成hadoop集群出错。
zkServer.sh start zkServer.sh status 查看zookeeper集群的状态,记得要查看每个节点(首次运行)启动journalnode
hadoop-daemon.sh start journalnode 在你设置的journalnode上启动,非master节点,只有第一次需要如此,以后都可以用start-all来启动。(首次运行)格式化hdfs,在master1上运行
hdfs namenode -format 格式化之后将namenode的文件下复制到你的master2上 Scp –r /home/hadoop/dfs hadooplee2:/home/hadoop(首次运行)格式化zkfc,故障迁移的控制器
hdfs zkfc -formatZK启动hdfs并检查状态
start-dfs.shjps命令检查 进程是否启动,通过网页查看两个namenode是否启动成功。
eg:http://hadooplee1:50070 http://hadooplee2:50070
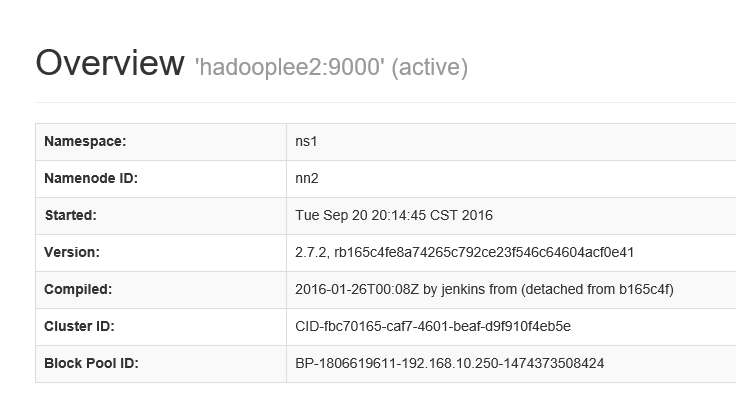
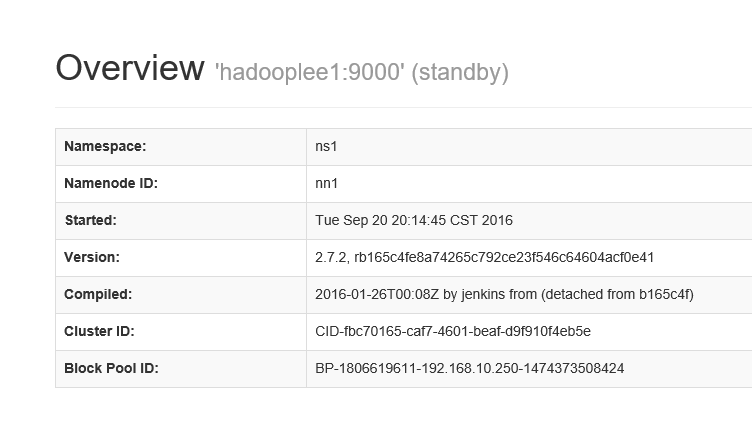
配置文件下载地址:














 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









