









1.如下:两个或多个参数动态实现:

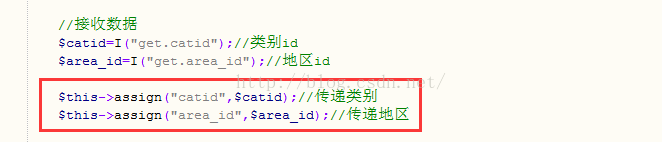
2.后台需要把接收到的参数再次传回模板里
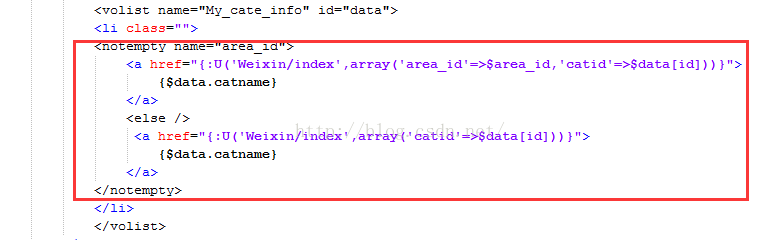
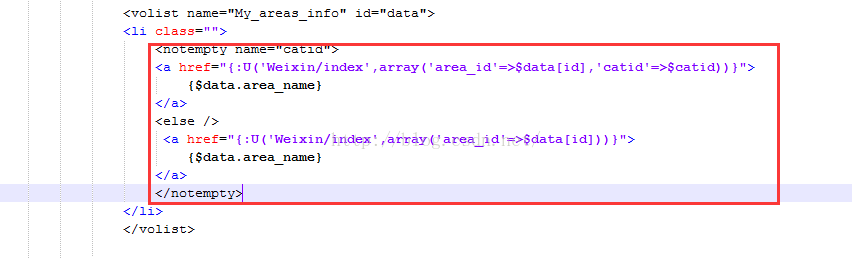
3.模板里如下:
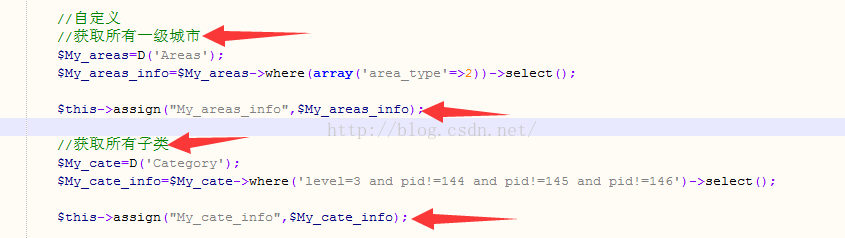
4.添加My_cate_info和My_areas_info怎么来的
1.如下:两个或多个参数动态实现:
2.后台需要把接收到的参数再次传回模板里
3.模板里如下:
4.添加My_cate_info和My_areas_info怎么来的
 74
74











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























