




 本文详细介绍Solr搜索引擎在Linux环境下的部署步骤,包括安装配置流程、中文分词器集成、业务字段配置、数据导入及搜索服务开发等内容。
本文详细介绍Solr搜索引擎在Linux环境下的部署步骤,包括安装配置流程、中文分词器集成、业务字段配置、数据导入及搜索服务开发等内容。
需要把solr服务器安装到linux环境:
第一步:安装linux、jdk、tomcat。(此步骤之前文章有提到,在此跳过)
创建 sorl 文件目录
# mkdir /usr/local/solr
# cd /usr/local/solr/
第二步:把solr的压缩包上传到服务器。并解压。
自行下载 solr-4.10.3.tgz.tgz
官网地址:http://www.apache.org/dyn/closer.lua/lucene/solr/6.2.1
解压
#tar -zxf solr-4.10.3.tgz.tgz
#cd solr-4.10.3
第三步:把 solr-4.10.3/dist/solr-4.10.3.war包部署到tomcat下。并改名为 solr.war
#cd /dist
# cp solr-4.10.3.war /usr/local/solr/tomcat/webapps/solr.war (路径根据自己配置的Tomcat路径改动)
第四步:解压war包。启动tomcat自动解压。解压成功后关闭tomcat、删除solr.war.
(注:如果没关闭tomcat就删除solr.war,解压后的文件夹solr也会被删除)
第五步:把/usr/local/solr/solr-4.10.3/example/lib/ext 目录下所有的jar包复制到solr工程中。
# cp * /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/
第六步:创建solrhome。Solrhome是存放solr服务器所有配置文件的目录。
# cp -r /usr/local/solr/solr-4.10.3/example/solr /usr/local/solr/solrhome
第七步:告诉solr服务器solrhome的位置。
需要修改solr工程的web.xml文件。
#cd tomcat/webapps/solr/WEB-INF/
#vim web.xml
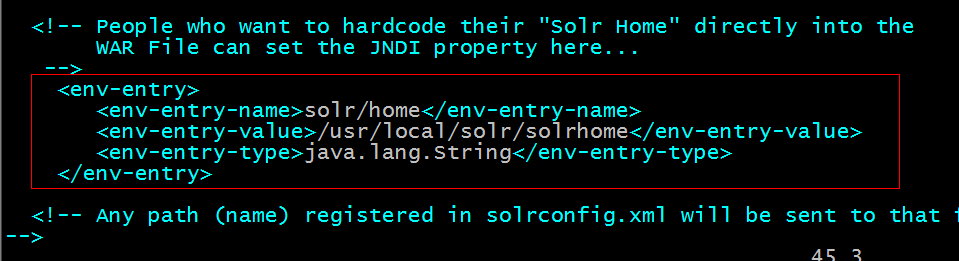
第八步:启动tomcat
在浏览器中输入地址测试是否启动成功
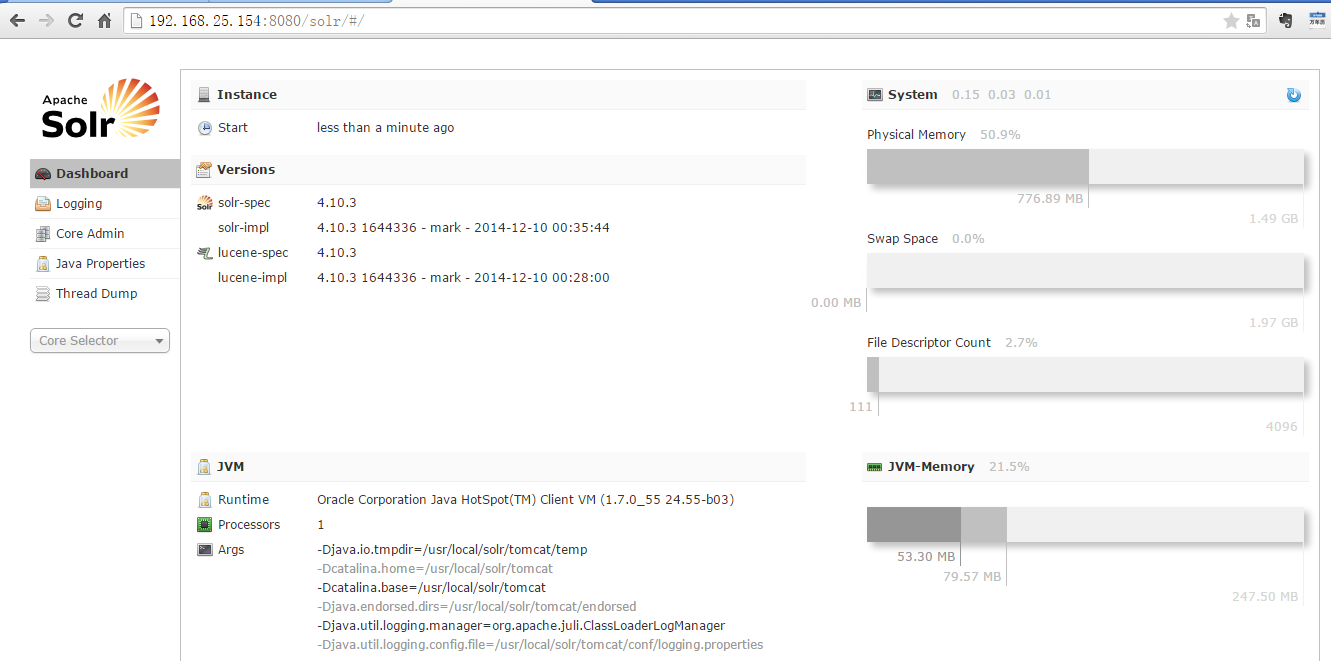
配置业务字段
1、在solr中默认是中文分析器,需要手工配置。配置一个FieldType,在FieldType中指定中文分析器。
2、Solr中的字段必须是先定义后使用
第一步:使用IK-Analyzer。把分析器的文件夹上传到服务器。(可自行到网上搜索下载)
第二步:上传到sorl目录下并解压,需要把分析器的jar包添加到solr工程中.
#cd /usr/local/sorl/
#tar -zxvf IK Analyzer 2012FF_hf1.zip
#cd IK Analyzer 2012FF_hf1
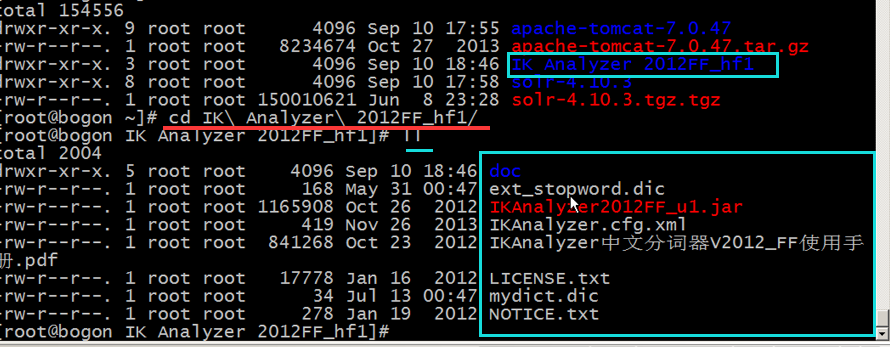
复制jar包到 tomcat 下(当前路径是solr下的tomcat中,如果tomcat定义在其他地方,请自行更改)
# cp IKAnalyzer2012FF_u1.jar /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/
第三步:需要把IKAnalyzer需要的扩展词典及停用词词典、配置文件复制到solr工程的classpath。
#cd /usr/local/solr/tomcat/webapps/solr/WEB-INF
#mkdir classes
#cd classes
即 /usr/local/solr/tomcat/webapps/solr/WEB-INF/classes
返回到 IK Analyzer 目录中
[root@rootIK Analyzer 2012FF_hf1]# cp IKAnalyzer.cfg.xml ext_stopword.dic mydict.dic /usr/local/solr/tomcat/webapps/solr/WEB-INF/classes
注意:扩展词典及停用词词典的字符集必须是utf-8。不能使用windows记事本编辑。
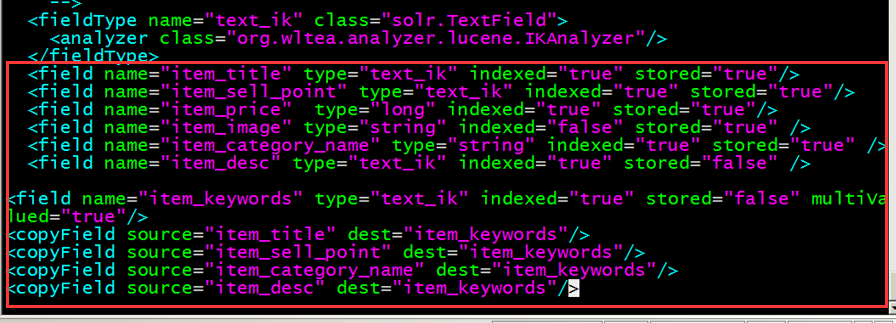
第四步:配置fieldType。需要在solrhome/collection1/conf/schema.xml中配置。
技巧:使用vi、vim跳转到文档开头gg。跳转到文档末尾:G,在最后节点前加入
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
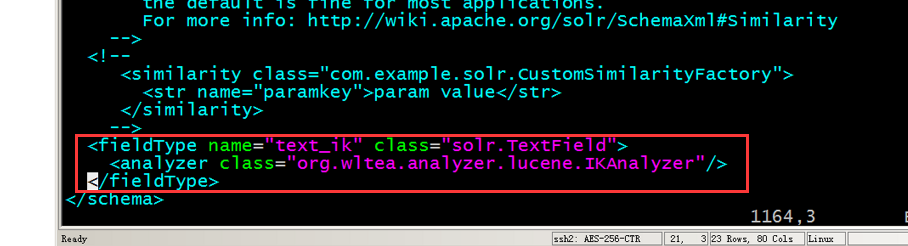
业务字段配置
以下以 商品为例
业务字段判断标准:
1、在搜索时是否需要在此字段上进行搜索。例如:商品名称、商品的卖点、商品的描述
2、后续的业务是否需要用到此字段。例如:商品id。
需要用到的字段:
1、商品id
2、商品title
3、卖点
4、价格
5、商品图片
6、商品分类名称
7、商品描述
Solr中的业务字段:
1、id——》商品id
其他的对应字段创建solr的字段(来代替)。
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_sell_point" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="long" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true" />
<field name="item_category_name" type="string" indexed="true" stored="true" />
<field name="item_desc" type="text_ik" indexed="true" stored="false" />
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_sell_point" dest="item_keywords"/>
<copyField source="item_category_name" dest="item_keywords"/>
<copyField source="item_desc" dest="item_keywords"/>
stored 标示是否存储,主要看是否展示此信息,不展示一般为false
name=“item_keywords” 是把“item_title”、“item_sell_point”、“item_category_name”、“item_desc”的内容放入复制域中,统一搜索,是solr做的搜索优化
写入schema.xml
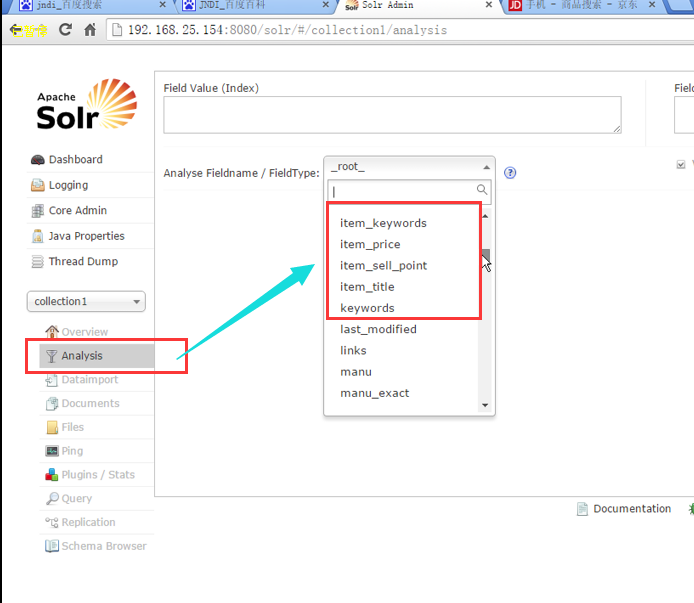
重新启动tomcat
通过浏览器访问solr,可以看到我们添加的搜索字段
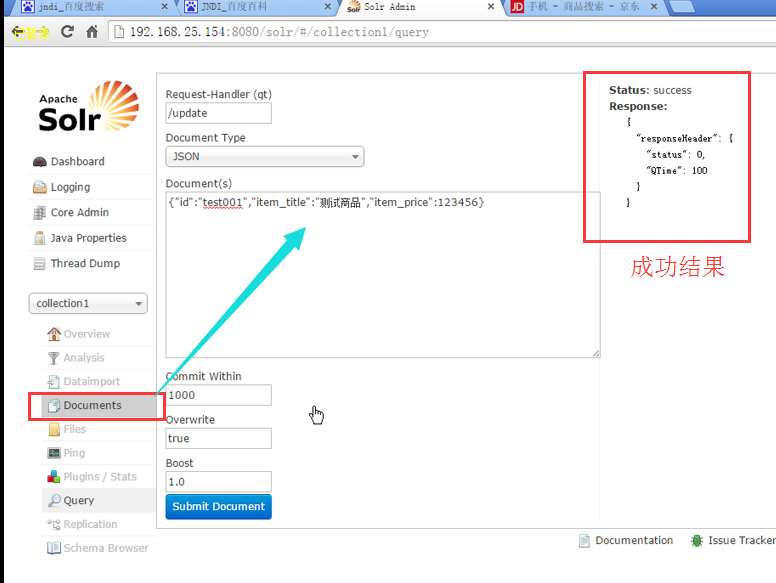
测试
1、在文档中添加测试数据
2、添加成功后,进入Query进行测试查询
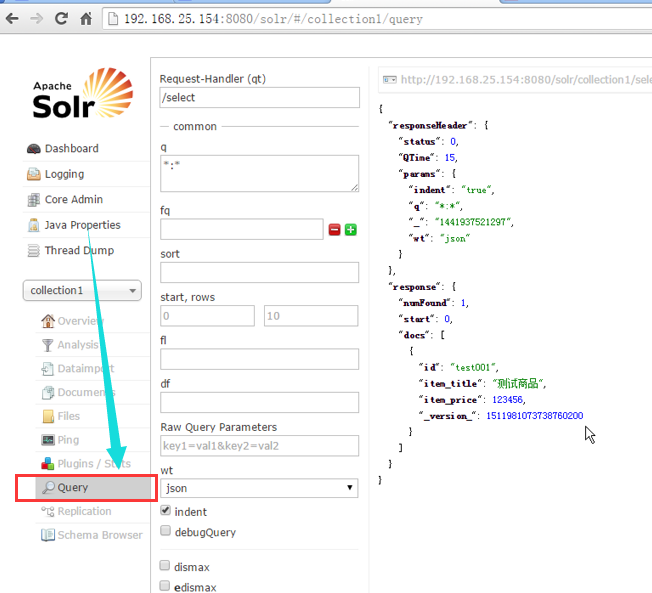
参数测试参照事例
http://blog.csdn.net/yanlove_jing/article/details/50931704
维护索引库
添加:添加一个json格式的文件就可以。
修改:在solr中没有update,只需要添加一个新的文档,要求文档id和被修改文档的id一致。原理是先删除后添加。
删除:使用xml格式。
删除两种方法:
1、根据id删除:
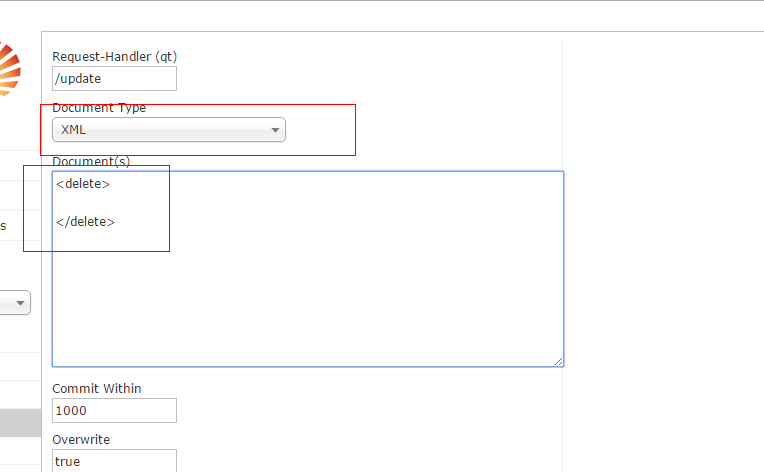
<delete>
<id>test001</id>
</delete>
<commit/>
2、根据查询删除:
删除所有
<delete>
<query>*:*</query>
</delete>
<commit/>
如果没有 commit 操作不生效
接下来要将数据库的数据导入到索引库里面去
引入 solrJ客户端
依赖下载 org.apache.solr jar
使用solrj的使用
测试
public class SolrJTest {
@Test
public void addDocument() throws Exception {
//创建一连接
//单机版
SolrServer solrServer = new HttpSolrServer("http://192.168.0.100:8080/solr");
//集群版
//SolrServer solrServer = new CloudSolrServer("http://192.168.0.100:8080/solr");
//创建一个文档对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "test001");
document.addField("item_title", "测试商品2");
document.addField("item_price", 54321);
//把文档对象写入索引库
solrServer.add(document);
//提交
solrServer.commit();
}
@Test
public void deleteDocument() throws Exception {
//创建一连接
SolrServer solrServer = new HttpSolrServer("http://192.168.0.100:8080/solr");
//solrServer.deleteById("test001");
solrServer.deleteByQuery("*:*");
solrServer.commit();
}
}
把商品信息导入到索引库
使用java程序读取mysql数据库中的商品信息,然后创建solr文档对象,把商品信息写入索引库。
需要发布一个服务。
为了灵活的进行分布式部署需要创建一搜素的服务工程发布 搜素服务。
系统架构
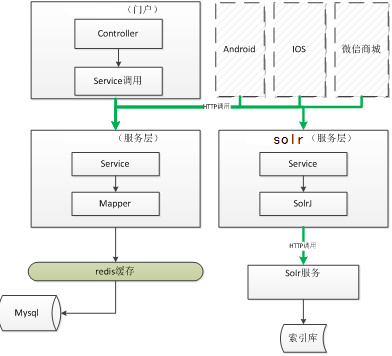
如果是maven,就建立一个solr服务工程,并调用依赖的JAR包
需要依赖的jar包:
Spring的jar包
Springmvc的jar包。
Solrj的jar包。
Mybatis的jar包
如果是其他构建,可以直接写个接口类实现
(构建过程就跳过,按自己工程需要编写)
导入商品数据
这里涉及三种数据表
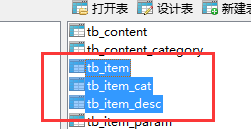
编写SQL语句,查询出要查询的表及其搜索内容
SELECT
a.id,
a.title,
a.sell_point,
a.price,
a.image,
b.`name` category_name,
c.item_desc
FROM
tb_item a
LEFT JOIN tb_item_cat b ON a.cid = b.id
LEFT JOIN tb_item_desc c ON a.id = c.item_id
Dao层
需要创建一个mapper接口+mapper映射文件。名称相同且在同一目录下。
创建一个sql语句对应的pojo(实体类)。上面搜索的主表是 tb_item ,就以item命名
public class Item {
private String id;
private String title;
private String sell_point;
private long price;
private String image;
private String category_name;
private String item_des;
}
创建接口
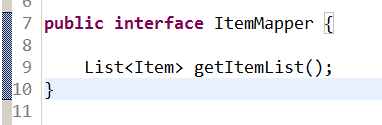
Mapper文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.search.mapper.ItemMapper" >
<select id="getItemList" resultType="com.search.pojo.Item">
SELECT
a.id,
a.title,
a.sell_point,
a.price,
a.image,
b.`name` category_name,
c.item_desc
FROM
tb_item a
LEFT JOIN tb_item_cat b ON a.cid = b.id
LEFT JOIN tb_item_desc c ON a.id = c.item_id
</select>
</mapper>
Service层
功能:导入所有的商品数据。没有参数。返回结果LeopardResult。从数据库中查询出所有的商品数据。创建一个SolrInputDocument对象,把对象写入索引库。
首先将SolrServer对象配置进spring容器中
applicationContext-solr.xml
<!-- 配置SolrServer对象 -->
<!-- 单机版 -->
<bean id="httpSolrServer" class="org.apache.solr.client.solrj.impl.HttpSolrServer">
<constructor-arg name="baseURL" value="http://192.168.0.100:8080/solr"></constructor-arg>
</bean>
然后编写service
@Service
public class ItemServiceImpl implements ItemService {
@Autowired
private ItemMapper itemMapper;
@Autowired
private SolrServer solrServer;
@Override
public LeopardResult importAllItems() {
try {
//查询商品列表
List<Item> list = itemMapper.getItemList();
//把商品信息写入索引库
for (Item item : list) {
//创建一个SolrInputDocument对象
SolrInputDocument document = new SolrInputDocument();
document.setField("id", item.getId());
document.setField("item_title", item.getTitle());
document.setField("item_sell_point", item.getSell_point());
document.setField("item_price", item.getPrice());
document.setField("item_image", item.getImage());
document.setField("item_category_name", item.getCategory_name());
document.setField("item_desc", item.getItem_des());
//写入索引库
solrServer.add(document);
}
//提交修改
solrServer.commit();
} catch (Exception e) {
e.printStackTrace();
return LeopardResult.build(500, ExceptionUtil.getStackTrace(e));
}
return LeopardResult.ok();
}
}
Controller层
功能:发布一个url形式的服务。调用Service的服务方法,把数据导入到索引库中,返回LeopardResult。
Url:/search/manager/importall
@Controller
@RequestMapping("/manager")
public class ItemController {
@Autowired
private ItemService itemService;
/**
* 导入商品数据到索引库
*/
@RequestMapping("/importall")
@ResponseBody
public LeopardResult importAllItems() {
LeopardResult result = itemService.importAllItems();
return result;
}
}
可以开启项目运行测试
测试过程中如果遇到 not found Mapper.xml,可检测下Mapper配置文件的路径是否加载正常
如果是 maven ,需要pom做如下更改
具体路径根据各自的配置文件路径进行更改就行
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
</build>
搜索服务发布
1、需求分析
http形式的服务。对外提供搜索服务是一个get形式的服务。调用此服务时需要查询条件,分页条件可以使用pageNum(要显示第几页)、pageSize(每页显示的记录数)。返回一个json格式的数据或是直接request保存参数。
请求的url:/search/query/{查询条件}/{pageNum}/{pageSize}
/search/query?q={查询条件}&pageNum={pageNum}&pageSize={pageSize}
2、Dao层
分析:尽可能的做的通用一些。参数应该是SolrQuery。返回商品列表、查询结果总记录数
查询测试:
@Test
public void queryDocument() throws Exception {
SolrServer solrServer = new HttpSolrServer("http://192.168.25.154:8080/solr");
//创建一个查询对象
SolrQuery query = new SolrQuery();
//设置查询条件
query.setQuery("*:*");
query.setStart(20);
query.setRows(50);
//执行查询
QueryResponse response = solrServer.query(query);
//取查询结果
SolrDocumentList solrDocumentList = response.getResults();
System.out.println("共查询到记录:" + solrDocumentList.getNumFound());
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
System.out.println(solrDocument.get("item_title"));
System.out.println(solrDocument.get("item_price"));
System.out.println(solrDocument.get("item_image"));
}
}
返回结果pojo:
public class SearchResult {
//商品列表
private List<Item> itemList;
//总记录数
private long recordCount;
//总页数
private long pageCount;
//当前页
private long curPage;
}
@Repository
public class SearchDaoImpl implements SearchDao {
@Autowired
private SolrServer solrServer;
@Override
public SearchResult search(SolrQuery query) throws Exception {
//返回值对象
SearchResult result = new SearchResult();
//根据查询条件查询索引库
QueryResponse queryResponse = solrServer.query(query);
//取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
//取查询结果总数量
result.setRecordCount(solrDocumentList.getNumFound());
//商品列表
List<Item> itemList = new ArrayList<>();
//取高亮显示
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
//取商品列表
for (SolrDocument solrDocument : solrDocumentList) {
//创建一商品对象
Item item = new Item();
item.setId((String) solrDocument.get("id"));
//取高亮显示的结果
List<String> list = highlighting.get(solrDocument.get("id")).get("item_title");
String title = "";
if (list != null && list.size()>0) {
title = list.get(0);
} else {
title = (String) solrDocument.get("item_title");
}
item.setTitle(title);
item.setImage((String) solrDocument.get("item_image"));
item.setPrice((long) solrDocument.get("item_price"));
item.setSell_point((String) solrDocument.get("item_sell_point"));
item.setCategory_name((String) solrDocument.get("item_category_name"));
//添加的商品列表
itemList.add(item);
}
result.setItemList(itemList);
return result;
}
}
3、Service层
功能:接收查询条件。查询条件及分页条件(pageNum、pageSize),创建一个SolrQuery对象。指定查询条件、分页条件、默认搜索域、高亮显示。调用dao层执行查询。得到查询结果计算总页数。返回SearchResult对象。
public interface SearchService {
SearchResult search(String queryString, int pageNum, int pageSize);
}
@Service
public class SearchServiceImpl implements SearchService {
@Autowired
private SearchDao searchDao;
@Override
public SearchResult search(String queryString, int pageNum, int pageSize) throws Exception {
//创建查询对象
SolrQuery query = new SolrQuery();
//设置查询条件
query.setQuery(queryString);
//设置分页
query.setStart((pageNum- 1) * pageSize);
query.setRows(pageSize);
//设置默认搜素域
query.set("df", "item_keywords");
//设置高亮显示
query.setHighlight(true);
//设置高亮显示的域
query.addHighlightField("item_title");
query.setHighlightSimplePre("<em style=\"color:red\">");
query.setHighlightSimplePost("</em>");
//执行查询
SearchResult searchResult = searchDao.search(query);
//计算查询结果总页数
long recordCount = searchResult.getRecordCount();
long pageCount = recordCount / pageSize;
if (recordCount % pageSize> 0) {
pageCount++;
}
searchResult.setPageCount(pageCount);
searchResult.setCurPage(pageNum);
return searchResult;
}
}
4、 Controller层
接收查询参数:查询条件、pageNum、pageSize
调用Service执行查询返回一个查询结果对象。
把查询结果包装到LeoaprdResult中返回,结果是json格式的数据。
如果查询条件为空,返回状态码:400,消息:查询条件不能为空。
pageNum为空:默认为1
pageSize 为空:默认为50
@Controller
public class SearchController {
@Autowired
private SearchService searchService;
@RequestMapping(value="/query", method=RequestMethod.GET)
@ResponseBody
public LeoaprdResult search(@RequestParam("q")String queryString,
@RequestParam(defaultValue="1",value="pageNum")Integer pageNum,
@RequestParam(defaultValue="60",value="pageSize")Integer pageSize) {
//查询条件不能为空
if (StringUtils.isBlank(queryString)) {
return LeoaprdResult.build(400, "查询条件不能为空");
}
SearchResult searchResult = null;
try {
//解决get乱码问题
queryString = new String(queryString.getBytes("IOS8859-1"),"utf-8");
searchResult = searchService.search(queryString, page, rows);
} catch (Exception e) {
e.printStackTrace();
return LeoaprdResult.build(500, ExceptionUtil.getStackTrace(e));
}
return LeoaprdResult.ok(searchResult);
}
}
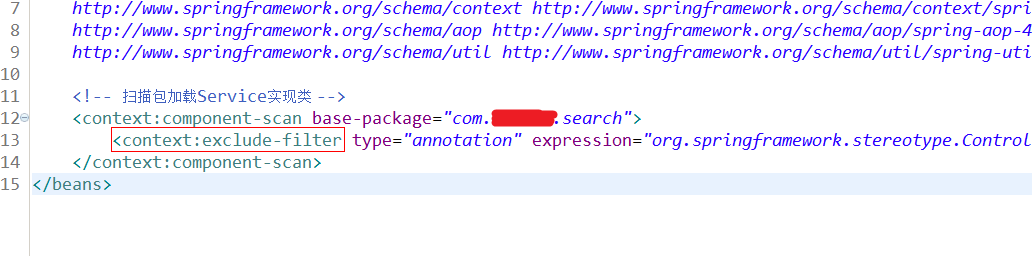
不扫描controller配置:

















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









