









rollover API 使你可以根据索引大小,文档数或使用期限自动过渡到新索引。 当 rollover 触发后,将创建新索引,写别名(write alias) 将更新为指向新索引,所有后续更新都将写入新索引。
对于基于时间的 rollover 来说,基于大小,文档数或使用期限过渡至新索引是比较适合的。 在任意时间 rollover 通常会导致许多小的索引,这可能会对性能和资源使用产生负面影响。
Rollover历史数据
- 在大多数情况下,无限期保留历史数据是不可行的
- 时间序列数据随着时间的流逝而失去价值,我们最终不得不将其删除
- 但是其中一些数据对于分析仍然非常有用
- Elasticsearch 6.3 引入了一项新的 rollover 功能,该功能
- 以紧凑的聚合格式保存旧数据
- 仅保存您感兴趣的数据
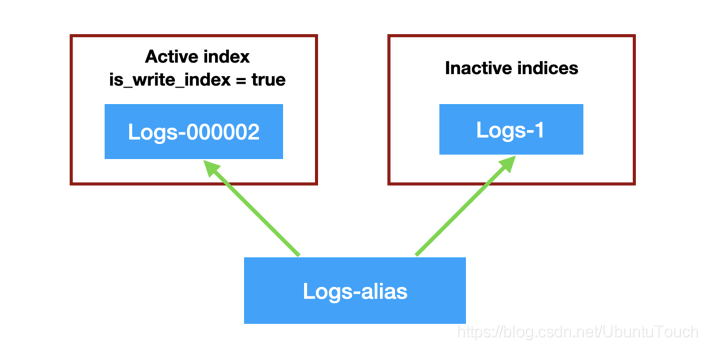
就像上面的图片看到的那样,我们定义了一个叫做 logs-alias 的alias,对于写操作来说,它总是会自动指向最新的可以用于写入index 的一个索引。针对我们上面的情况,它指向 logs-000002。如果新的 rollover 发生后,新的 logs-000003 将被生成,并对于写操作来说,它自动指向最新生产的 logs-000003 索引。而对于读写操作来说,它将同时指向最先的 logs-1,logs-000002 及 logs-000003。在这里我们需要注意的是:在我们最早设定 index 名字时,最后的一个字符必须是数字,比如我们上面显示的 logs-1。否则,自动生产 index 将会失败。
注意:尾随后缀(如000001)是一个正数,Elasticsearch 希望用它创建索引。弹性搜索只能从正数开始递增;起始号码是多少并不重要。只要我们有一个正整数,Elasticsearch就会递增数字并向前移动。例如,如果我们提供 my-index-04 或 my-index-0004,下一个滚动索引将是 myindex-000005。Elasticsearch会自动用零填充后缀。
rollover 例子
我们还是先拿一个 rollover 的例子来说明,这样比较清楚。首先我们定义一个 log-alias 的 alias:
PUT /%3Clogs-%7Bnow%2Fd%7D-1%3E
{
"aliases": {
"log_alias": {
"is_write_index": true
}
}
}如果大家对于上面的字符串 “%3Clogs-%7Bnow%2Fd%7D-1%3E” 比较陌生的话,可以参考网站 URL Encode Online | URLEncoder。实际上它就是字符串 “<logs-{now/d}-1>” 的url编码形式。请注意上面的 is_write_index 必须设置为 true。运行上面的结果是:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "logs-2019.10.21-1"
}显然,它帮我们生产了一个叫做 logs-2019.10.21-1 的 index。接下来,我们先使用我们的 Kibana 来准备一下我们的 index 数据。我们运行起来我们的 Kibana:
我们分别点击上面的1和2处:
点击上面的 “Add data”。这样我们就可以把我们的 kibana_sample_data_logs 索引加载到 Elasticsearch 中。我们可以通过如下的命令进行查看:
GET _cat/indices/kibana_sample_data_logs命令显示结果为:
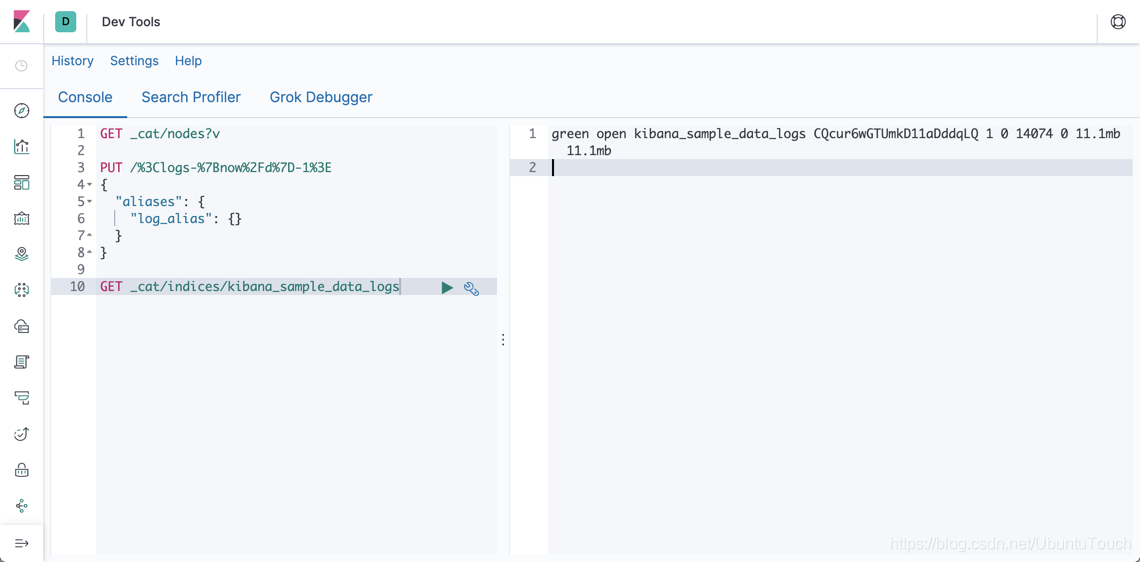
它显示 kibana_sample_data_logs 具有 11.1M 的数据,并且它有 14074 个文档:
我们接下来运行如下的命令:
POST _reindex
{
"source": {
"index": "kibana_sample_data_logs"
},
"dest": {
"index": "log_alias"
}
}这个命令的作用是把 kibana_sample_data_logs 里的数据 reindex 到 log_alias 所指向的 index。也就是把 kibana_sample_data_logs 的文档复制一份到我们上面显示的 logs-2019.10.21-1 索引里。我们做如下的操作查看一下结果:
GET logs-2019.10.21-1/_count显示的结果是:
{
"count" : 14074,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
显然,我们已经复制到所有的数据。那么接下来,我们来运行如下的一个指令:
POST /log_alias/_rollover?dry_run
{
"conditions": {
"max_age": "7d",
"max_docs": 14000,
"max_size": "5gb"
}
}在这里,我们定义了三个条件:
- 如果时间超过7天,那么自动 rollover,也就是使用新的 index
- 如果文档的数目超过 14000 个,那么自动 rollover
- 如果 index 的大小超过 5G,那么自动 rollover
在上面我们使用了 dry_run 参数,表明就是运行时看看,但不是真正地实施。显示的结果是:
{
"acknowledged" : false,
"shards_acknowledged" : false,
"old_index" : "logs-2019.10.21-1",
"new_index" : "logs-2019.10.21-000002",
"rolled_over" : false,
"dry_run" : true,
"conditions" : {
"[max_docs: 1400]" : true,
"[max_size: 5gb]" : false,
"[max_age: 7d]" : false
}
}根据目前我们的条件,我们的 logs-2019.10.21-1 文档数已经超过 14000 个了,所以会生产新的索引 logs-2019.10.21-000002。因为我使用了 dry_run,也就是演习,所以显示的 rolled_over 是 false。
为了能真正地 rollover,我们运行如下的命令:
POST /log_alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1400,
"max_size": "5gb"
}
}显示的结果是:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"old_index" : "logs-2019.10.21-1",
"new_index" : "logs-2019.10.21-000002",
"rolled_over" : true,
"dry_run" : false,
"conditions" : {
"[max_docs: 1400]" : true,
"[max_size: 5gb]" : false,
"[max_age: 7d]" : false
}
}
说明它已经 rolled_ovder了。我们可以通过如下写的命令来检查:
GET _cat/indices/logs-2019*显示的结果为:

我们现在可以看到有两个以 logs-2019.10.21 为头的 index,并且第二文档 logs-2019.10.21-000002 文档数为0。如果我们这个时候直接再想 log_alias 写入文档的话:
POST log_alias/_doc
{
"agent": "Mozilla/5.0 (X11; Linux x86_64; rv:6.0a1) Gecko/20110421 Firefox/6.0a1",
"bytes": 6219,
"clientip": "223.87.60.27",
"extension": "deb",
"geo": {
"srcdest": "IN:US",
"src": "IN",
"dest": "US",
"coordinates": {
"lat": 39.41042861,
"lon": -88.8454325
}
},
"host": "artifacts.elastic.co",
"index": "kibana_sample_data_logs",
"ip": "223.87.60.27",
"machine": {
"ram": 8589934592,
"os": "win 8"
},
"memory": null,
"message": """
223.87.60.27 - - [2018-07-22T00:39:02.912Z] "GET /elasticsearch/elasticsearch-6.3.2.deb_1 HTTP/1.1" 200 6219 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:6.0a1) Gecko/20110421 Firefox/6.0a1"
""",
"phpmemory": null,
"referer": "http://twitter.com/success/wendy-lawrence",
"request": "/elasticsearch/elasticsearch-6.3.2.deb",
"response": 200,
"tags": [
"success",
"info"
],
"timestamp": "2019-10-13T00:39:02.912Z",
"url": "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.deb_1",
"utc_time": "2019-10-13T00:39:02.912Z"
}显示的结果:
{
"_index" : "logs-2019.10.21-000002",
"_type" : "_doc",
"_id" : "xPyQ7m0BsjOKp1OsjsP8",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}显然它写入的是 logs-2019.10.21-000002 索引。我们再次查询 log_alias 的总共文档数:
GET log_alias/_count显示的结果是:
{
"count" : 14075,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
}
}
显然它和之前的 14074 个文档多增加了一个文档,也就是说 log_alias 是同时指向 logs-2019.10.21-1 及 logs-2019.10.21-000002。
配合 ILM 一起使用
Rollover 在实战中,我们可以配合 ILM 一起使用。我们可以定义如下的一个 ILM policy:
PUT _ilm/policy/50gb_30d_delete_90d_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50GB",
"max_age": "30d",
"max_docs": 10000
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}在上面,我们定义了如下的一个 policy:
- 当一个索引的文档数超过 10000,或者文档的时间超过 30 天,或者索引的大小超过 50G,之后摄入的文档就会自动 rollover
- 文档超过 90 天,就会被自动删除
我们接着就定义如下的 index template:
PUT _index_template/timeseries_template
{
"index_patterns": [
"myindex-*"
],
"data_stream": {},
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "50gb_30d_delete_90d_policy"
}
}
}之后,所有新创建的以 myindex- 为开头的索引将会自动采纳 50gb_30d_delete_90d_policy 策略,也就是该索引将会根据 50gb_30d_delete_90d_policy 所定义的条件自动 rollover。针对上面的 data_stream,我们可以采用如下的方式来创建索引:
PUT _data_stream/myindex-ds更多关于 data stream 的知识可以参考文章 “Elastic:Data stream 在索引生命周期管理中的应用”。
ILM 可以通过简单的设置更新轻松集成到现有索引中。 要将策略添加到现有索引,你必须仅提供策略名称:
PUT myindex/_settings
{
"index": {
"lifecycle": {
"name": "50gb_30d_delete_90d_policy"
}
}
}你可以在索引名称中使用通配符将更改应用于多个索引。我们可以通过 REST API 检查每个索引的 ILM 应用规则:
GET <index_name>/_ilm/explain比如:
GET myindex/_ilm/explain上面的命令返回:
{
"indices" : {
"myindex" : {
"index" : "myindex",
"managed" : true,
"policy" : "50gb_30d_delete_90d_policy",
"index_creation_date_millis" : 1659074177474,
"time_since_index_creation" : "1.96m",
"lifecycle_date_millis" : 1659074177474,
"age" : "1.96m",
"phase" : "hot",
"phase_time_millis" : 1659074180591,
"action" : "rollover",
"action_time_millis" : 1659074180591,
"step" : "check-rollover-ready",
"step_time_millis" : 1659074180591,
"phase_execution" : {
"policy" : "50gb_30d_delete_90d_policy",
"phase_definition" : {
"min_age" : "0ms",
"actions" : {
"rollover" : {
"max_size" : "50gb",
"max_age" : "30d"
}
}
},
"version" : 1,
"modified_date_in_millis" : 1659074079064
}
}
}
}结果包含很多信息,但最重要的字段如下:
-
managed (Boolean):索引是否由 ILM 管理
-
policy:运用策略的名称。 必须主要出于调试目的对其进行检查
-
age:索引的时间
-
phase:索引的实际阶段。
-
action:上一个运用的 action
-
step:动作的步骤。 有些动作可以有一个或多个步骤。
-
phase_execution:实际阶段执行的描述
总结:在今天的文档里,我们讲述了如何使用 rollover API 来自动管理我们的 index。利用 rollover API,它可以很方便地帮我们自动根据我们设定的条件帮我们把我们的Index过度到新的 index。在未来的文章里,我们将讲述如何使用 Index life cycle policy 来帮我们管理我们的 index。















 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









