






在上篇文章 <php实现验证码的识别 (初级篇 ) > 中,讲了如何识别简单的验证,这里的简单只的是验证码有数字和字母组成,格式统一,每次出现位置固定。这篇文章将继续深入研究识别验证码,这次识别的目标是,验证码有字符和数字组成,验证码存在旋转(可能左右都旋转),位置不固定,存在字符与字符之间的粘连,且验证码有更强的干扰素。这篇文章讲解的方法,并不是万能的解决方案,并且提供代码不能直接解决你的问题,这里仅仅是方法,具体需求读者自己解决,需要说明的是,识别验证码与具体的编程语言无关,这里只是使用 php 语言实现,使用这里介绍的方法,你可以使用任何语言实现。
这篇文章逐步讲解识别验证码过程中的各个步骤。
![]()
如上图,随后的讲解我们都围绕此图展开。
一:拿到一个验证码的,第一眼我们首先要做的工作是,二值化。把验证码的部分用 1 表示,背景部分用 0 表示出来,识别方法很简单,我们打印出验证码正张图片的 RGB ,然后分析其规律即可,通过 RGB 码,我们很容易分辨出上面这张图片的 R 值大于 120 , G 和 B 的值小于 80 ,所以依据这个规则我们很容易把上面的图片二值化。再看初级篇中识别的两张图
![]()
![]()
刚看上去,感觉很复杂。验证码的图片每次背景色都不相同,且不是单色,各个验证码数字的颜色每次也各不相同。貌似很难二值化,其实我们打印出其 RGB 值很容易就发现。无论验证数字颜色如何变化,该数字的 RGB 值总有一个值小于 125 ,所以通过如下判断
$rgbarray['red'] < 125 || $rgbarray['green']<125|| $rgbarray['blue'] < 125
我们就很容易分辨出哪里是数字,哪里是背景。
我们能够找到这些规律的因素是,在制作验证码的干扰素时,为了使干扰素不影响数字的显示效果,必须使用干扰素的 RGB 和数字 RGB 相互独立,互不干扰。只要懂得这个规律,我们就很容易实现二值化。
我们找到的 120 , 80 , 125 等阈值,可能和实际的 RGB 有出入,所以,有时二值化后,会有部分地方出现 1 ,对于验证码上固定位置显示数字,这种干扰没有太大意义。但是对于验证码位置不确定的图片来说,在我们切割字符时,很可能造成干扰。所以,在二值化后要进行去噪出来。
二:接下来我们进行第二个步骤,出噪。出燥的原理很简单,就是把孤立的有效的值去掉,如果噪点比较高,要求的效率也比较高的话,这里面也有很多工作要做。幸好这里我们不要求这么高深,我们使用最简单的方法就可以,如果一个点为 1 则判断这个点的上下左右上左上右下左下右 8 个方位上数字是否为 1 ,如果不为 1 ,就认为是一个燥点,直接设置为 1 即可。

如上图所示,我们使用此方法很容易发现红色方框部分的 1 为燥点,直接设置为 1 即可。
在判断时我们使用了一个技巧,有时候的噪点可能是两个连续的 1 ,所以我们
我们计算这个点的 8 个方向上的值之和,最后我们判断他们的和是否小于特定的阈值
三:经过去噪后,我们就得到干净的二值化的数据,接下来要做的就是切割字符了。切割字符的方法有很多种,这里我采用最简单的一种,先垂直方向切割成为字符,然后在水平方向去掉多于的 0000 ,如下图

第一步切割红线部分,第二步切割蓝线部分,这样就可以得到独立的字符了。但是像下面这种情况

按上面的方法会把 dw 字符切割成一个字符,这是错误的切割,所以这里我们涉及到粘连字符的切割。
四:粘连字符切割,制作验证码时,规则字符的粘连很容易分割开,如果字符本身有缩放,变形就很难处理,经过分析,我们可以发现,上面的字符粘连属于很简单的方式,只是规则字符的粘连,所以处理这种情况,我们也使用很简单的处理方式。当完成分割操作后,我们不能马上确定分割的部分就为一个字符,要进行验证,验证的关键因素就是,切割下来的字符的宽是否大于阈值,这个阈值的取舍标准是,一个字符无论怎么旋转变形都不会大于这个阈值,所以,如果我们切割的块大于这个阈值,就可以认为这是一个粘连字符;如果大于两个阈值之和,就认为是三个字符粘连,以此类推。知道这个规则后,切割粘连字符也就很简单了。如果我们发现是粘连字符块,直接平分这个块为两个或者多个新的块就可以。当然为了更好的还原字符,我一般都采用平分 +1 , -1 对字符块的部分进行适当的补充。
五:经过上面四个步骤,我们就可以提取出比较纯的字符块了,接下来要做就是匹配字符了。对于旋转字符的特征码建立,有很多种方法,这里就不做深入研究了。我这里使用的最简单的方式,为所有字符的所有情况建立匹配库,所以在我提供的代码种增加了 study 操作,其目的就是,先有人手工识别图片的验证码,然后通过 study 方法,写入特征码库。这样写入的图片数据越多,验证识别的准确行也就越高。
好了,经过以上步骤,我们基本上可以识别现在互联网上大部分的验证码,这里我们都是使用的最简单的方法,没有使用任何 OCR 知识。这些方法,应该属于非 OCR 领域的顶峰了,要想识别更加复杂的验证码,那就需要更多的 OCR 知识了。有机会的话,我会在高级篇中一一做介绍。
下面是一些容易识别的验证码,希望引起网站管理者的重视。
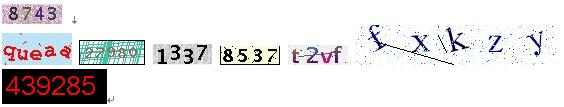
制作验证码的一些建议
对于识别验证码的程序来说,最难得部分是验证字符的切割和特征码的建立,而国内很多程序员只做验证码时,总是喜欢在验证码加很多干扰素,干扰线,影响效果不说,还达不到很好的效果;所以,要想使自己验证码难于本识别,只做下面两点就够了
1 :字符粘连,最好所有的字符都有粘连的部分;
2 :不要使用规格字符,验证码的各个部分使用不同比例的缩放或者旋转。
只要做到这两点,或者这两点的变形,识别程序就很难识别。我们看看, yahoo 和 google 的验证码就知道,白字黑底,却很难被识别。
Goole:

yahoo:

源文件下:点击下载
作者 : 逸学堂( ugg )
转帖请注明:http://blog.csdn.net/ugg/archive/2009/03/09/3972368.aspx















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









