







Hive——用户自定义函数(UDF)
用户自定义函数(UDF)是一个允许用户扩展HiveQL的强大的功能。用户可以使用Java编写自己的UDF,一旦将用户自定义函数加入到用户会话中(交互式的或者通过脚本执行的),它们就将和内置的函数一样使用,甚至可以提供联机帮助。Hive具有多种类型的用户自定义函数,每一种都会针对输入数据执行特定“一类”的转换过程。
在ETL处理中,一个处理过程可能包含多个处理步骤。Hive语言具有多种方式来将上一步骤的输入通过管道传递给下一个步骤,然后在一个查询中产生众多输出。用户同样可以针对一些特定的处理过程编写自定义函数。如果没有这个功能,那么一个处理过程可能就需要包含一个MapReduce步骤或者需要将数据转移到另一个系统中来实现这些改变。因此,Hive提供了用户自定义函数(UDF),UDF是在Hive查询产生的相同的task进程中执行的,因此它们可以高效地执行。
发现和描述函数
在编写自定义UDF之前,我们先来熟悉下Hive中自带的那些UDF。需要注意的是在Hive中通常使用“UDF”来表示任意的函数,包括用户自定义的或者内置的。
SHOW FUNCTIONS命令可以列举出当前Hive会话中所加载的所有函数名称,其中包括内置的和用户加载进来的函数。
函数通常都有其自身的使用文档。使用DESCRIBE FUNCTION 命令可以展示对应函数简短的介绍。(如:DESCRIBE FUNCTION concat;)
函数也可能包含更多的详细文档,可以通过DESCRIBE FUNCTION EXTENDED 命令进行查看。(如:DESCRIBE FUNCTION EXTENDED concat;)
调用函数
如果想使用函数,只需要在查询中通过调用函数名,并传入需要的参数即可。某些函数需要指定特定的参数个数和参数类型,而其他函数可以传入一组参数,参数类型可以是多样的。和关键字一样,函数名也是保留的字符串:
SELECT concat(column1, column2) AS x FROM table;编写UDF
编写一个UDF,需要继承UDF并实现evaluate()函数。在查询过程中,查询中对应的每个应用到这个函数的地方都会对这个类进行实例化。对于每行输入都会调用evaluate()函数。而evaluate()处理后的值会返回给Hive。同时用户是可以重载evaluate方法的。Hive会像Java的方法重载一样,自动选择匹配的方法。
package com.test.hive.udf;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
@Description(name = "deprecation",
value = "_FUNC_(date, price) - from the input date string(yyyyMMdd), " +
"returns the deprecation price by computing price and "
+ "the depreciation rate of the second-hand car.",
extended = "Example:\n" +
" > SELECT _FUNC_(date_string, price) FROM src;")
public class TestUDF extends UDF {
private SimpleDateFormat df;
private double[] rates;
public TestUDF() {
df = new SimpleDateFormat("yyyyMMdd");
rates = new double[]{0.071, 0.070, 0.069, 0.067, 0.064,
0.062, 0.060, 0.057, 0.055, 0.053,
0.051, 0.049, 0.049, 0.048, 0.046,
0.044};
}
@SuppressWarnings("deprecation")
public String evaluate(String deal_date, String price) {
Date date = null;
Date now = new Date();//获取当前时间
long price_ = Long.valueOf(price);
try {
date = df.parse(deal_date);
/*37-45行是固定的算法,可以替换自己的算法*/
double numMonth = (now.getYear() * 12 + now.getMonth())
- (date.getYear() * 12 + now.getMonth()) + 1;
double mileage = ((6.000 - (1.7000 * numMonth / 12)) / 1.7000) * 12 * 0.25;
double total = numMonth + mileage;
int depre_year = (int) (total / 12);
for(int i = 0; i < depre_year + 1; i++) {
price_ = (long) (price_ * (1 - rates[i]));
}
} catch(Exception ex) {
return null;
}
return Long.toString(price_);
}
}代码中的@Description(…)表示的是Java总的注解,是可选的。注解中注明了关于这个函数的文档说明,用户需要通过这个注解来阐明自定义的UDF的使用方法和例子。这样当用户通过DESCRIBE FUNCTION …命令查看该函数时,注解中的_FUNC_字符串将会被替换为用户为为这个函数定义的“临时”函数名称,定义方式下面会进行介绍。
提示:UDF中的evaluate()函数的参数和返回值类型只能是Hive可以序列化的数据类型。例如,如果用户处理的全是数值,那么UDF的输出参数类型可以是基本数据类型int、Integer封装的对象或者是一个IntWritable对象,也就是Hadoop对整型封装后的对象。用户不需要特别地关心将调用到哪个类型,因为当类型不一致时,Hive会自动将类型转换成匹配的类型。需要记住的是,null在Hive中对于任何数据类型都是合法的,但是对于Java基本数据类型,不能是对象,也不能是null。
如果想在Hive中使用UDF,那么需要将Java代码进行编译,然后将编译后的UDF二进制类文件打包成一个JAR文件。如下步骤:
- 右键项目,选择Export;
- 选择导出格式为JAR file格式:
- 点击Next,选择要导出的项目,以及填写导出的目录:
- 点击Finish完成。

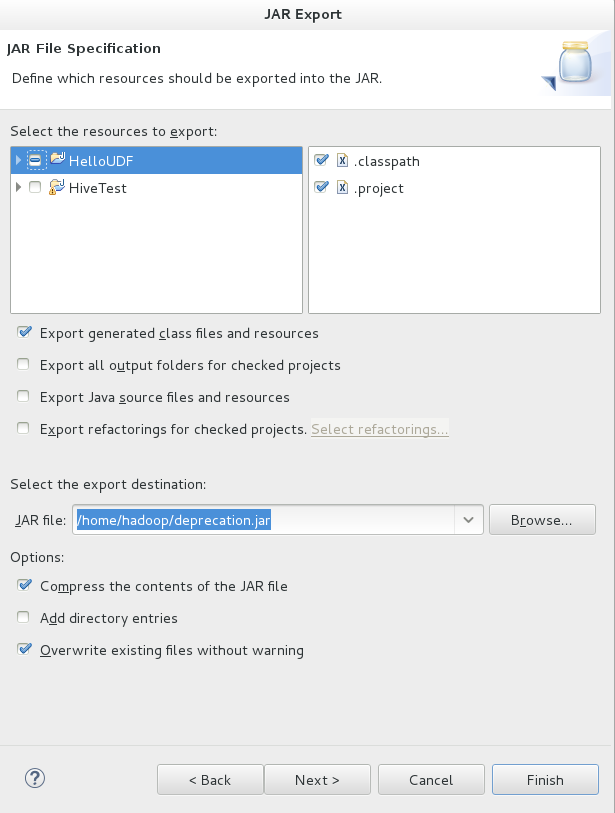
然后,在Hive会话中,将这JAR文件加入到类路径下,再通过CREATE FUNCTION语句定义好使用这个Java类的函数:
hive> ADD JAR /home/hadoop/deprecation.jar;
Added [/home/hadoop/deprecation.jar] to class path
Added resources: [/home/hadoop/deprecation.jar]
hive> CREATE TEMPORARY FUNCTION deprecation AS 'com.test.hive.udf.TestUDF';
OK
Time taken: 0.7 seconds需要注意的是,JAR文件路径是不需要用引号括起来的,同时,到目前为止这个路径需要是当前文件系统的全路经。Hive不仅仅将这个JAR文件加入到classpath下,同时还将其加入到分布式缓存中,这样整个集群的机器都是可以获得该JAR文件的。
需要注意的是,CREATE FUNCTION语句中的TEMPORARY这个关键字。当前会话中声明的函数只会在当前会话中有效。因此用户需要在每个会话中都增加JAR然后创建函数。不过,如果用户需要频繁地使用同一个JAR文件和函数的话,那么可以将相关语句增加到$HOME/.hiverc文件中去。
下面是应用示例:
hive> DESCRIBE FUNCTION deprecation;
OK
deprecation(date, price) - from the input date string(yyyyMMdd), returns the deprecation price by computing price and the depreciation rate of the second-hand car.
Time taken: 0.403 seconds, Fetched: 1 row(s)
hive> DESCRIBE FUNCTION EXTENDED deprecation;
OK
deprecation(date, price) - from the input date string(yyyyMMdd), returns the deprecation price by computing price and the depreciation rate of the second-hand car.
Example:
> SELECT deprecation(date_string, price) FROM src;
Time taken: 0.008 seconds, Fetched: 3 row(s)
hive> SELECT deal_date, substring(total_price, 0, 2), deprecation(deal_date, substring(total_price, 0, 2)) FROM stg_price;
OK
20150513 13 11
20150514 13 11
Time taken: 0.057 seconds, Fetched: 2 row(s)再次说明下,UDF允许用户在Hive语言中执行自定义的转换过程。通过上面那个UDF,Hive现在可以执行对二手车的简单折旧计算。
当我们使用完自定义UDF后,我们可以通过如下命令删除此函数:
hive> DROP TEMPORARY FUNCTION IF EXISTS deprecation;
OK
Time taken: 0.066 seconds像通常一样,IF EXISTS是可选的。如果增加此关键字,则即使函数不存在也不会报错。















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









