







什么是Spark?
在Apache的网站上,有非常简单的一句话,'Spark is a fast and general engine',就是说Spark是一个统一的计算引擎,而且突出fast。那么具体是做什么的?是做large-scale的processing,即大数据处理。
Spark is a fast and general engine for large-scale processing. 这句话非常简单,但是它突出了Spark的一些特点:第一个特点就是Spark是一个并行式的、内存的、计算密集型的计算引擎。
那么来说内存的,因为Spark是基于MapReduce的,但是它的空间数据不是存在于HDFS上面,而是存在于内存中,所以他是一个内存式的计算,这样就导致了Spark的计算速度很快,同时它可以部署成集群,所以它可以分布到各个节点上,并行式地计算;Spark上还有很多机器学习和数据挖掘的学习包,用户可以利用学习包进行数据的迭代计算,所以它又是一个计算密集型的计算工具。
为什么使用Spark?
在传统的方法中,MapReduce需要大量的磁盘I/O,MapReduce会将大量的数据存储在HDFS上,而Spark因为是内存式的,就不需要大量的磁盘I/O,这样就提高了处理速度。
性能方面,在通用的任务上,Spark可以提高20-100倍的速度,因此Spark性能的第一点就是快;第二个就是比较高效,用过Scala开发程序的人应该有感受,Spark语法的表达式非常强大,原来可能用十行去描述的一段匹配的代码,Scala可能一行就可以做到,所以它效率非常高,包括它也支持一些主流的编程语言,Java、Python、R等。
另外,Spark可以和Hadoop生态系统结合在一起。
Spark基础
1. Spark核心组件

a. SparkSQL - 处理结构化数据
b. Spark Streaming - 创建可扩展和容错性的流式应用
c. MLlib - Spark的机器学习库
d. GraphX - 并行图计算
在Spark Build-in组件中,最基础的就是Spark Core,它是所有应用程序架构的基础。Spark SQL、Spark Streaming、Spark MLlib、GraphX都是Spark Build-in组件提供的应用组件的子架构。
不管是哪一个应用上的子架构,它都是基于RDD上的应用框架。实际上用户可以基于RDD来开发出不同领域上的子框架,运用Spark Build-in组件来执行。
2. Spark应用程序的架构
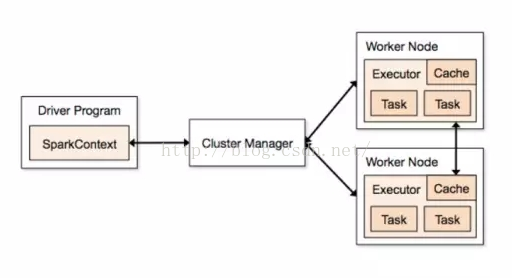
在每一个Spark应用程序中,只有一个Driver Program,和若干个Executor。大家可以看到右边的Work Node,可以认为Work Node就是一个物理机器,所有的应用程序都是从Driver开始的,Driver Program会先初始化一个SparkContext,作为应用程序的入口,每一个Spark应用程序只有一个SparkContext。SparkContext作为入口,再去初始化一些作业调度和任务调度,通过Cluster Manager将任务分配到各个节点上,由Worker Node上面的执行器来执行任务。一个Spark应用程序有多个Executor,一个Executor上又可以执行多个Task,这就是Spark并行计算的框架。
此外,Executor除了可以处理Task,还可以将数据存在Cache或者HDFS上面。
3. Spark运行模式
一般我们看到的是下图的前四种Spark运行模式:Local、Standalone、Yarn和Mesos。Cloud就是一种外部base的Spark运行环境。
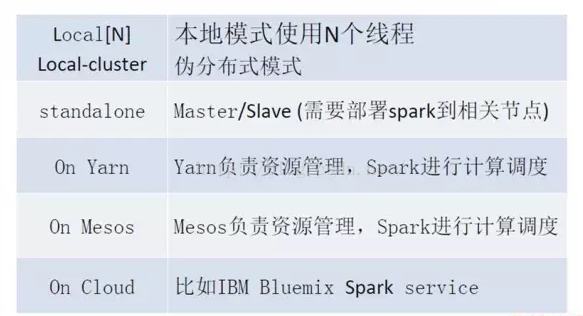
Local就是指本地模式,用户可以在本地执行Spark程序,Local[N]即指的是使用多少个线程;Standalone是Spark自己自带的一个运行模式,需要用户自己去部署Spark到相关的节点上;Yarn和Mesos是做资源管理的,它也是Hadoop生态系统里面的,如果使用Yarn和Mesos,那么就是这两者去做资源管理,Spark来做资源调度。
不管是哪种运行模式,它都还细分为两种,一种是client模式,一种是cluster模式。那么怎么区分这两者模式呢?可以用到架构图中的Driver Program。Driver Program如果在集群里面,那就是cluster模式;如果在集群外面,那就是client模式。
4. 弹性分布式数据集RDD
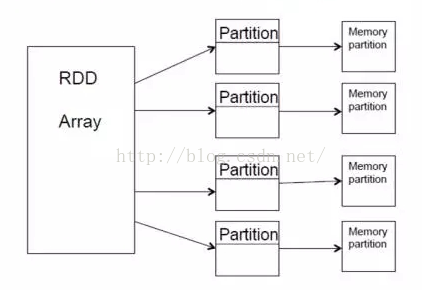
RDD有几个特点:一是它不可变,二是它被分区。我们在Java或C++里,所用的基本数据集、数组都可以被更改,但是RDD是不能被更改的,它只能产生新的RDD,也就是说Scala是一种函数式的编程语言。函数式的编程语言不主张就地更改现有的所有数据,而是在已有的数据上产生一个新的数据,主要是做transform的工作,即映射的工作。
RDD不可更改,但可以分布到不同的Partition上,对用户来说,就实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD本身是一个抽象的概念,它不是真实存在的,那么它分配到各个节点上,对用户来说是透明的,用户只要按照自己操作本地数据集的方法去操作RDD就可以了,不用管它是怎么分配到各个Partition上面的。
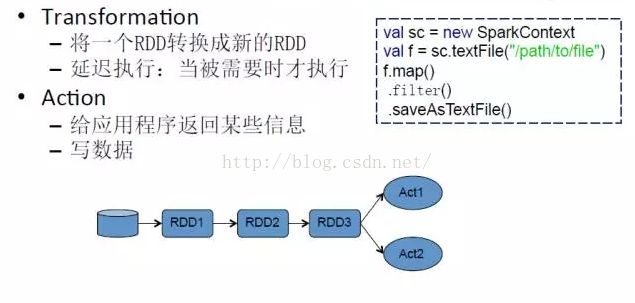
在操作上,RDD主要有两种方式,一种是Transform,一种是Action。Transform的操作就是将一个RDD转换成一个新的RDD,但是它有一个特点,就是延迟执行;第二种操作是Action,用户要么写数据,要么给应用程序返回某些信息。当你执行Action的时候,Transform才会被触发,这也就是延迟执行的意思。
看一下上图中右面的代码,这是一个Scala代码,在第一行,它去创建一个SparkContext;第二行去读取一个文件;然后这个文件做了三个操作,第一个是map,第二个是filter,第三个是saveAsTextFile,前面两个动作就是一个Transform,map的意思就是映射,filter就是过滤,saveAsTextFile就是左后的写操作。当saveAsTextFIle写操作发生之前,前面的map和filter是不会去执行的,等到saveAsTextFile写操作这个动作开始时,才会去执行map和filter这两个动作。
5. Spark程序的运行
了解了RDD和Spark运行的原理之后,我们从整体上看一下Spark程序是怎么执行的。
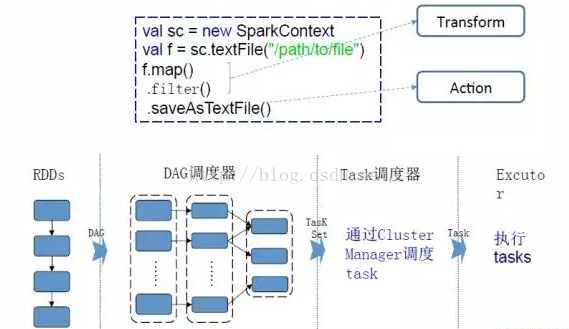
还是之前的三行代码,前两步是Transform,最后一步是Action。那么RDD就做一系列的Transform;DAG是一个调度器,SparkContext会初始化一个任务调度器,任务调度器就会将RDD的一系列转换切分成不同的Stage,由任务调度器将不同的Stage分成不同的Task,通过Cluster Manager去调度这些Task,把这些TaskSet分布到不同的Executor上去执行。
6. Spark DataFrame
很多人会问,已经有RDD了,为什么还要DataFrame?DataFrame API是2015年发布的,Spark1.3之后就有,它是以命名列的方式去组织分布式的数据集。

Spark上面原来主要是为了Big Data,大数据平台,它很多都是非结构化的数据。非结构化数据需要用户自己去组织映射,而DataFrame就提供了一些现成的,用户可以通过操作关系表去操作大数据平台上的数据。这样很多Data Scientists就可以使用原来使用关系型数据库的知识和方式去操作大数据平台上的数据。
DataFrame支持的数据源也很多,比如说JSON、Hive、JDBC等。
DataFrame还有另外一个存在的理由:我们可以分析上图中的表,蓝色部分代表着RDD去操纵不同语言的同样数量集的性能。可以看到,可以看到RDD在Python上的性能较差,Scala的性能比较好一些。但是从绿色的部分(代表DataFrame)来看,用DataFrame来编写程序时,它们的性能是一样的,也就是说,RDD在被不同语言操作时,性能表现不一样,但是使用DataFrame去操作时,性能表现不受语言的影响,并且性能比RDD的性能整体要高。
下面展示一个简单的DataFrame示例。
val df = sqlContext.jsonFile("/path/to/your/jsonfile")
df.registerTempTable("people")
sqlContext.sql("select age, count(*) from people group by age").show()先读取JSON文件获取DataFrame数据,再将DataFrame数据转换为一个虚拟的临时表,接着进行sql语句方式的查询并展示查询结果。














 6576
6576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









