









一、Logistic回归
Logistic回归为概率型非线性回归模型,是研究二分类结果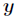
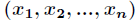
在讲解Logistic回归理论之前,我们先从LR分类器说起。LR分类器,即Logistic Regression Classifier。在分类情形下,经过学习后的LR分类器是一组权值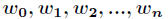
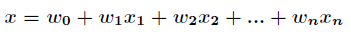
这里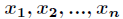
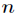
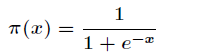
由于Sigmoid函数的定义域为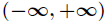
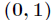
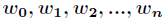
下面正式讲Logistic回归模型。
考虑具有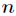
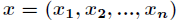
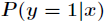
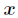
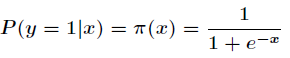
其中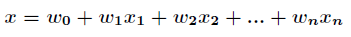
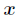

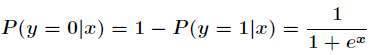
所以事件发生与不发生的概率之比为:

这个比值称为事件的发生比(the odds of experiencing an event),简记为odds。
可以看出Logistic回归都是围绕一个Sigmoid函数来展开的。接下来就讲如何用极大似然估计求分类器的参数。
假设有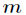



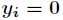
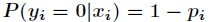

因为各个观测样本之间相互独立,那么它们的联合分布为各边缘分布的乘积。得到似然函数为

然后我们的目标是求出是这一似然函数的值最大的参数估计,最大似然估计就是求出参数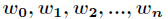
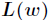
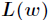
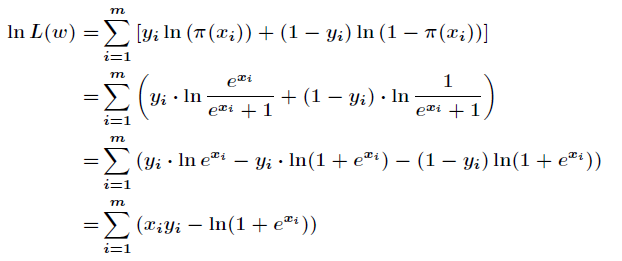
现在求向量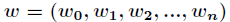
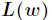
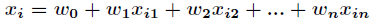
这里介绍一种方法,叫做梯度下降法(求局部极小值),当然相对还有梯度上升法(求局部极大值)。对上述的似然函数求偏导后得到
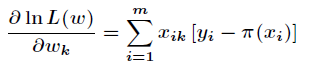
由于是求局部极大值,所以跟据梯度上升法,有
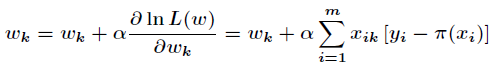
根据上述公式,只需初始化向量
二、softmax回归
softmax回归可以看成是Logistic回归的扩展。我们知道Logistic回归用于二分类,那么如果我们面对多分类问题怎么办?最常见的例子就是MNIST手写数字分类,今天要讲的softmax回归能用于解决这类问题。
在Logistic回归中,样本数据的值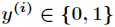


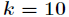
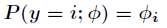
那么
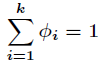
而且有
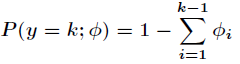
为了将多项式模型表述成指数分布族,先引入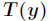
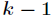
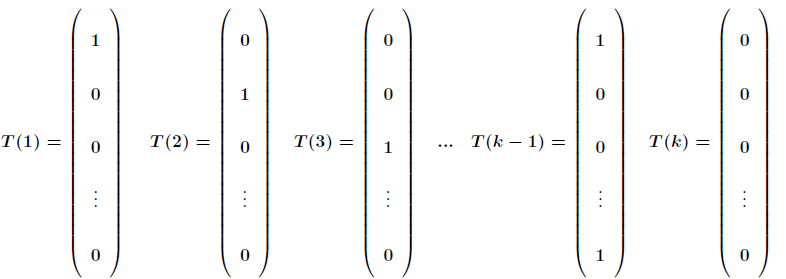
应用于一般线性模型,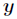

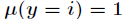
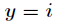
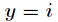
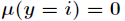
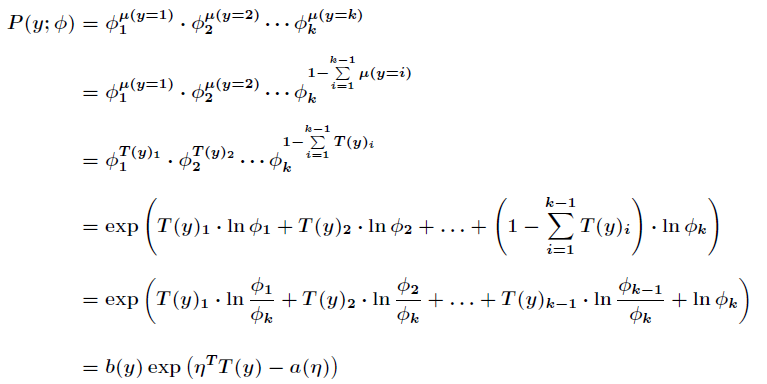
对比一下,可以得到
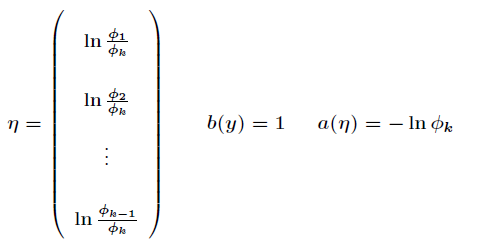
由于
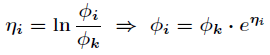
那么最终得到

可以得到期望值为
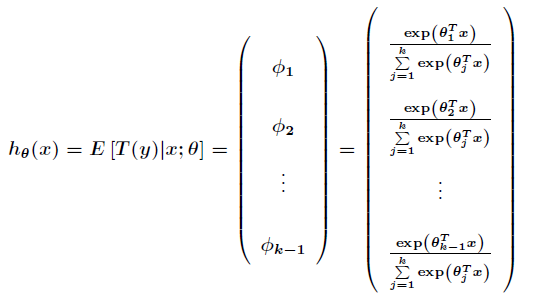
接下来得到对数似然函数为
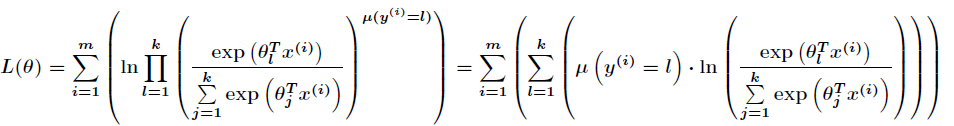
其中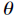
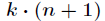

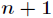

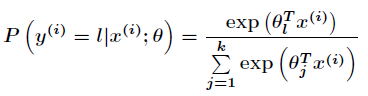
跟Logistic回归一样,softmax也可以用梯度下降法或者牛顿迭代法求解,对对数似然函数求偏导数,得到
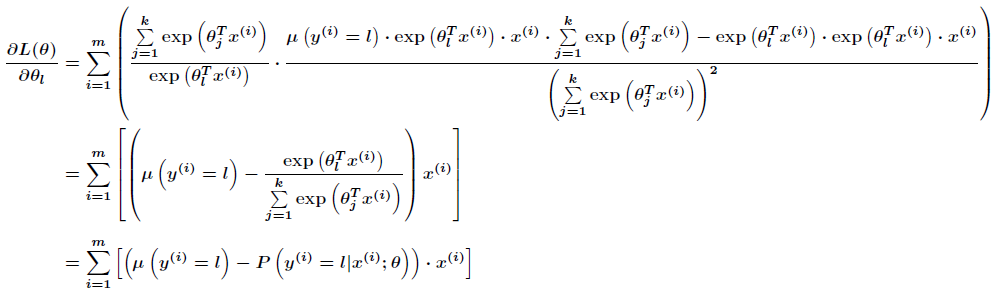
然后我们可以通过梯度上升法来更新参数

注意这里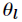
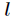
在softmax回归中直接用上述对数似然函数是不能更新参数的,因为它存在冗余的参数,通常用牛顿方法中的Hessian矩阵也不可逆,是一个非凸函数,那么可以通过添加一个权重衰减项来修改代价函数,使得代价函数是凸函数,并且得到的Hessian矩阵可逆。
三、TensorFlow实现MNIST手写数字识别(利用到softmax回归)
#!/usr/bin/env python
import tensorflow as tf
import numpy as np
import tensorflow.examples.tutorials.mnist.input_data as input_data
# read MNIST data set
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
# create symbolic variables
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
# create variables: weights and biases
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# define model
y = tf.nn.softmax(tf.matmul(X, W) + b)
# cross entropy
cross_entropy = -tf.reduce_sum(Y * tf.log(y))
# train step
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# init step
init = tf.initialize_all_variables()
with tf.Session() as sess:
# run the init op
sess.run(init)
# then train
for i in range(1000):
batch_trX, batch_trY = mnist.train.next_batch(128)
sess.run(train_step, feed_dict={X: batch_trX, Y: batch_trY})
# test and evaluate our model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels})参考:















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









