







话说爬虫为什么会陷入循环呢?答案很简单,当我们重新去解析一个已经解析过的网页时,就会陷入无限循环。这意味着我们会重新访问那个网页的所有链接,然后不久后又会访问到这个网页。最简单的例子就是,网页A包含了网页B的链接,而网页B又包含了网页A的链接,那它们之间就会形成一个闭环。
那么我们怎样防止访问已经访问过的页面呢?答案很简单,设置一个标志即可。整个互联网就是一个图结构,我们通常使用DFS(深度优先搜索)和BFS(广度优先搜索)进行遍历。所以,像遍历一个简单的图一样,将访问过的结点标记一下即可。
爬虫的基本思路如下:
- 根据URL获取相应页面的HTML代码
- 利用正则匹配或者Jsoup等库解析HTML代码,提取需要的内容
- 将获取的内容持久化到数据库中
- 处理好中文字符的编码问题,可以采用多线程提高效率
爬虫基本原理
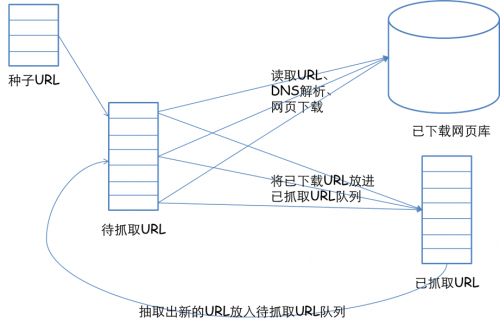
更宽泛意义上的爬虫侧重于如果在大量的URL中寻找出高质量的资源,如何在有限的时间内访问更多页面等等。网络爬虫的基本工作流程如下:
- 首先选取一部分精心挑选的种子URL;
- 将这些URL放入待抓取URL队列;
- 从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
- 分析已抓取URL对应的网页,分析页面里包含的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
有几个概念,一个是发http请求,一个是正则匹配你感兴趣的链接,一个是多线程,另外还有两个队列。
爬虫难点1 环路
网络爬虫有时候会陷入循环或者环路中,比如从页面A,A链接到页面B,B链接到页面C,页面C又会链接到页面A。这样就陷入到环路中。
环路影响:
- 消耗网络带宽,无法获取其他页面
- 对Web服务器也是负担,可能击垮该站点,可能阻止正常用户访问该站点
- 即使没有性能影响,但获取大量重复页面也导致数据冗余
解决方案:
- 简单限定爬虫的最大循环次数,对于某web站点访问超过一定阈值就跳出,避免无限循环
- 保存一个已访问url列表,记录页面是否被访问过的技术
1、二叉树和散列表,快速判定某个url是否访问过
2、存在位图
就是new int[length],然后把第几个数置为1,表示已经访问过了。可不可以再优化,int是32位,32位可以表示32个数字。HashCode会存在冲突的情况,两个URL映射到同一个存在位上,冲突的后果是某个页面被忽略(这比死循环的恶作用小)
3、保存检查
一定要及时把已访问的URL列表保存到硬盘上,防止爬虫崩溃,内存里的数据会丢失
4、集群,分而治之
多台机器一起爬虫,可以根据URL计算HashCode,然后根据HashCode映射到相应机器的id(第0台、第1台、第2台等等)
难点2 URL别名
有些URL名称不一样,但是指向同一个资源。
| URl 1 | URL 2 | 什么时候是别名 |
|---|---|---|
| www.foo.com/bar.html | www.foo.com:80/bar.html | 默认端口是80 |
| www.foo.com/~fred | www.foo.com/%7Ffred | %7F与~相同 |
| www.foo.com/x.html#top | www.foo.com/x.html#middle | %7F与~相同 |
| https://www.baidu.com/ | https://www.BAIDU.com/ | 服务器是大小写无关 |
| www.foo.com/index.html | www.foo.com | 默认页面为 index.html |
| www.foo.com/index.html | 209.123.123/index.html | ip和域名相同 |
难点3 动态虚拟空间
比如日历程序,它会生成一个指向下一个月的链接,真正的用户是不会不停地请求下个月的链接的。但是不了解这些内容特性的爬虫蜘蛛可能会不断向这些资源发出无穷的请求。
抓取策略
一般策略是深度优先或者广度优先。有些技术能使得爬虫蜘蛛有更好的表现
- 广度优先的爬行,避免深度优先陷入某个站点的环路中,无法访问其他站点。
- 限制访问次数,限定一段时间内机器人可以从一个web站点获取的页面数量。
- 内容指纹,根据页面的内容计算出一个校验和,但是动态的内容(日期,评论数目)会阻碍重复检测
- 维护黑名单
- 人工监视,特殊情况发出邮件通知
- 动态变化,根据当前热点新闻等等
- 规范化URL,把一些转义字符、ip与域名之类的统一
- 限制URL大小,环路可能会使得URL长度增加,比如/index.html,/folder/index.html,/folder/folder/index.html……
全文索引
全文索引就是一个数据库,给它一个单词,它可以立刻提供包含那个单词的所有文字。创建了索引后,就不必对文档自身进行扫描了。
比如:文章A包含了Java、学习、程序员;文章B包含了Java、Python、面试、招聘。
如果搜索了Java,可以知道得到文章A和文章B,而不必对文章A、B全文扫描。














 2963
2963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









