文本分类,首先它是分类问题,应该对应着分类过程的两个重要的步骤,一个是使用训练数据集训练分类器,另一个就是使用测试数据集来评价分类器的分类精度。然而,作为文本分类,它还具有文本这样的约束,所以对于文本来说,需要额外的处理过程,我们结合使用libsvm从宏观上总结一下,基于libsvm实现文本分类实现的基本过程,如下所示:
- 选择文本训练数据集和测试数据集:训练集和测试集都是类标签已知的;
- 训练集文本预处理:这里主要包括分词、去停用词、建立词袋模型(倒排表);
- 选择文本分类使用的特征向量(词向量):最终的目标是使得最终选出的特征向量在多个类别之间具有一定的类别区分度,可以使用相关有效的技术去实现特征向量的选择,由于分词后得到大量的词,通过选择降维技术能很好地减少计算量,还能维持分类的精度;
- 输出libsvm支持的量化的训练样本集文件:类别名称、特征向量中每个词元素分别到数字编号的映射转换,以及基于类别和特征向量来量化文本训练集,能够满足使用libsvm训练所需要的数据格式;
- 测试数据集预处理:同样包括分词(需要和训练过程中使用的分词器一致)、去停用词、建立词袋模型(倒排表),但是这时需要加载训练过程中生成的特征向量,用特征向量去排除多余的不在特征向量中的词(也称为降维);
- 输出libsvm支持的量化的测试样本集文件:格式和训练数据集的预处理阶段的输出相同。
- 使用libsvm训练文本分类器:使用训练集预处理阶段输出的量化的数据集文件,这个阶段也需要做很多工作(后面会详细说明),最终输出分类模型文件
- 使用libsvm验证分类模型的精度:使用测试集预处理阶段输出的量化的数据集文件,和分类模型文件来验证分类的精度。
- 分类模型参数寻优:如果经过libsvm训练出来的分类模型精度很差,可以通过libsvm自带的交叉验证(Cross Validation)功能来实现参数的寻优,通过搜索参数取值空间来获取最佳的参数值,使分类模型的精度满足实际分类需要。
基于上面的分析,分别对上面每个步骤进行实现,最终完成一个分类任务。
数据集选择
我们选择了搜狗的语料库,可以参考后面的链接下载语料库文件。这里,需要注意的是,分别准备一个训练数据集和一个测试数据集,不要让两个数据集有交叉。例如,假设有C个类别,选择每个分类的下的N篇文档作为训练集,总共的训练集文档数量为C*N,剩下的每一类下M篇作为测试数据集使用,测试数据集总共文档数等于C*M。
数据集文本预处理
我们选择使用ICTCLAS分词器,使用该分词器可以不需要预先建立自己的词典,而且分词后已经标注了词性,可以根据词性对词进行一定程度过滤(如保留名词,删除量词、叹词等等对分类没有意义的词汇)。
下载ICTCLAS软件包,如果是在Win7 64位系统上使用Java实现分词,选择如下两个软件包:
- 20131115123549_nlpir_ictclas2013_u20131115_release.zip
- 20130416090323_Win-64bit-JNI-lib.zip
将第二个软件包中的NLPIR_JNI.dll文件拷贝到C:\Windows\System32目录下面,将第一个软件包中的Data目录和NLPIR.dll、NLPIR.lib、NLPIR.h、NLPIR.lib文件拷贝到Java工程根目录下面。
对于其他操作系统,可以到ICTCLAS网站(http://ictclas.nlpir.org/downloads)下载对应版本的软件包。
下面,我们使用Java实现分词,定义分词器接口,以便切换其他分词器实现时,容易扩展,如下所示:
1 | package org.shirdrn.document.processor.common; |
6 | public interface DocumentAnalyzer { |
7 | Map<String, Term> analyze(File file); |
增加一个外部的停用词表,这个我们直接封装到抽象类AbstractDocumentAnalyzer中去了,该抽象类就是从一个指定的文件或目录读取停用词文件,将停用词加载到内存中,在分词的过程中对词进行进一步的过滤。然后基于上面的实现,给出包裹ICTCLAS分词器的实现,代码如下所示:
01 | package org.shirdrn.document.processor.analyzer; |
03 | import java.io.BufferedReader; |
05 | import java.io.FileInputStream; |
06 | import java.io.IOException; |
07 | import java.io.InputStreamReader; |
08 | import java.util.HashMap; |
11 | import kevin.zhang.NLPIR; |
13 | import org.apache.commons.logging.Log; |
14 | import org.apache.commons.logging.LogFactory; |
15 | import org.shirdrn.document.processor.common.DocumentAnalyzer; |
16 | import org.shirdrn.document.processor.common.Term; |
17 | import org.shirdrn.document.processor.config.Configuration; |
19 | public class IctclasAnalyzer extends AbstractDocumentAnalyzer implements DocumentAnalyzer { |
21 | private static final Log LOG = LogFactory.getLog(IctclasAnalyzer.class); |
22 | private final NLPIR analyzer; |
24 | public IctclasAnalyzer(Configuration configuration) { |
26 | analyzer = new NLPIR(); |
28 | boolean initialized = NLPIR.NLPIR_Init(".".getBytes(charSet), 1); |
30 | throw new RuntimeException("Fail to initialize!"); |
32 | } catch (Exception e) { |
33 | throw new RuntimeException("", e); |
38 | public Map<String, Term> analyze(File file) { |
39 | String doc = file.getAbsolutePath(); |
40 | LOG.info("Process document: file=" + doc); |
41 | Map<String, Term> terms = new HashMap<String, Term>(0); |
42 | BufferedReader br = null; |
44 | br = new BufferedReader(new InputStreamReader(new FileInputStream(file), charSet)); |
46 | while((line = br.readLine()) != null) { |
49 | byte nativeBytes[] = analyzer.NLPIR_ParagraphProcess(line.getBytes(charSet), 1); |
50 | String content = new String(nativeBytes, 0, nativeBytes.length, charSet); |
51 | String[] rawWords = content.split("\\s+"); |
52 | for(String rawWord : rawWords) { |
53 | String[] words = rawWord.split("/"); |
54 | if(words.length == 2) { |
55 | String word = words[0]; |
56 | String lexicalCategory = words[1]; |
57 | Term term = terms.get(word); |
59 | term = new Term(word); |
61 | term.setLexicalCategory(lexicalCategory); |
62 | terms.put(word, term); |
65 | LOG.debug("Got word: word=" + rawWord); |
70 | } catch (IOException e) { |
77 | } catch (IOException e) { |
它是对一个文件进行读取,然后进行分词,去停用词,最后返回的Map包含了的集合,此属性包括词性(Lexical Category)、词频、TF等信息。
这样,遍历数据集目录和文件,就能去将全部的文档分词,最终构建词袋模型。我们使用Java中集合来存储文档、词、类别之间的关系,如下所示:
01 | private int totalDocCount; |
02 | private final List<String> labels = new ArrayList<String>(); |
04 | private final Map<String, Integer> labelledTotalDocCountMap = new HashMap<String, Integer>(); |
06 | private final Map<String, Map<String, Map<String, Term>>> termTable = |
07 | new HashMap<String, Map<String, Map<String, Term>>>(); |
09 | private final Map<String, Map<String, Set<String>>> invertedTable = |
10 | new HashMap<String, Map<String, Set<String>>>(); |
基于训练数据集选择特征向量
上面已经构建好词袋模型,包括相关的文档和词等的关系信息。现在我们来选择用来建立分类模型的特征词向量,首先要选择一种度量,来有效地选择出特征词向量。基于论文《A comparative study on feature selection in text categorization》,我们选择基于卡方统计量(chi-square statistic, CHI)技术来实现选择,这里根据计算公式: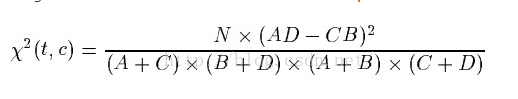
其中,公式中各个参数的含义,说明如下:
- N:训练数据集文档总数
- A:在一个类别中,包含某个词的文档的数量
- B:在一个类别中,排除该类别,其他类别包含某个词的文档的数量
- C:在一个类别中,不包含某个词的文档的数量
- D:在一个类别中,不包含某个词也不在该类别中的文档的数量
要想进一步了解,可以参考这篇论文。
使用卡方统计量,为每个类别下的每个词都进行计算得到一个CHI值,然后对这个类别下的所有的词基于CHI值进行排序,选择出最大的topN个词(很显然使用堆排序算法更合适);最后将多个类别下选择的多组topN个词进行合并,得到最终的特征向量。
其实,这里可以进行一下优化,每个类别下对应着topN个词,在合并的时候可以根据一定的标准,将各个类别都出现的词给出一个比例,超过指定比例的可以删除掉,这样可以使特征向量在多个类别分类过程中更具有区分度。这里,我们只是做了个简单的合并。
我们看一下,用到的存储结构,使用Java的集合来存储:
2 | private final Map<String, Map<String, Term>> chiLabelToWordsVectorsMap = newHashMap<String, Map<String, Term>>(0); |
4 | private final Map<String, Term> chiMergedTermVectorMap = new HashMap<String, Term>(0); |
下面,实现特征向量选择计算的实现,代码如下所示:
001 | package org.shirdrn.document.processor.component.train; |
003 | import java.util.Iterator; |
004 | import java.util.Map; |
005 | import java.util.Map.Entry; |
006 | import java.util.Set; |
008 | import org.apache.commons.logging.Log; |
009 | import org.apache.commons.logging.LogFactory; |
010 | import org.shirdrn.document.processor.common.AbstractComponent; |
011 | import org.shirdrn.document.processor.common.Context; |
012 | import org.shirdrn.document.processor.common.Term; |
013 | import org.shirdrn.document.processor.utils.SortUtils; |
015 | public class FeatureTermVectorSelector extends AbstractComponent { |
017 | private static final Log LOG = LogFactory.getLog(FeatureTermVectorSelector.class); |
018 | private final int keptTermCountEachLabel; |
020 | public FeatureTermVectorSelector(Context context) { |
022 | keptTermCountEachLabel = context.getConfiguration().getInt("processor.each.label.kept.term.count", 3000); |
029 | for(String label : context.getVectorMetadata().getLabels()) { |
031 | LOG.info("Compute CHI for: label=" + label); |
032 | processOneLabel(label); |
036 | Iterator<Entry<String, Map<String, Term>>> chiIter = |
037 | context.getVectorMetadata().chiLabelToWordsVectorsIterator(); |
038 | while(chiIter.hasNext()) { |
039 | Entry<String, Map<String, Term>> entry = chiIter.next(); |
040 | String label = entry.getKey(); |
041 | LOG.info("Sort CHI terms for: label=" + label + ", termCount=" + entry.getValue().size()); |
042 | Entry<String, Term>[] a = sort(entry.getValue()); |
043 | for (int i = 0; i < Math.min(a.length, keptTermCountEachLabel); i++) { |
044 | Entry<String, Term> termEntry = a[i]; |
046 | context.getVectorMetadata().addChiMergedTerm(termEntry.getKey(), termEntry.getValue()); |
051 | @SuppressWarnings("unchecked") |
052 | private Entry<String, Term>[] sort(Map<String, Term> terms) { |
053 | Entry<String, Term>[] a = new Entry[terms.size()]; |
054 | a = terms.entrySet().toArray(a); |
055 | SortUtils.heapSort(a, true, keptTermCountEachLabel); |
059 | private void processOneLabel(String label) { |
060 | Iterator<Entry<String, Map<String, Set<String>>>> iter = |
061 | context.getVectorMetadata().invertedTableIterator(); |
062 | while(iter.hasNext()) { |
063 | Entry<String, Map<String, Set<String>>> entry = iter.next(); |
064 | String word = entry.getKey(); |
065 | Map<String, Set<String>> labelledDocs = entry.getValue(); |
068 | int docCountContainingWordInLabel = 0; |
069 | if(labelledDocs.get(label) != null) { |
070 | docCountContainingWordInLabel = labelledDocs.get(label).size(); |
074 | int docCountContainingWordNotInLabel = 0; |
075 | Iterator<Entry<String, Set<String>>> labelledIter = |
076 | labelledDocs.entrySet().iterator(); |
077 | while(labelledIter.hasNext()) { |
078 | Entry<String, Set<String>> labelledEntry = labelledIter.next(); |
079 | String tmpLabel = labelledEntry.getKey(); |
080 | if(!label.equals(tmpLabel)) { |
081 | docCountContainingWordNotInLabel += entry.getValue().size(); |
086 | int docCountNotContainingWordInLabel = |
087 | getDocCountNotContainingWordInLabel(word, label); |
090 | int docCountNotContainingWordNotInLabel = |
091 | getDocCountNotContainingWordNotInLabel(word, label); |
094 | int N = context.getVectorMetadata().getTotalDocCount(); |
095 | int A = docCountContainingWordInLabel; |
096 | int B = docCountContainingWordNotInLabel; |
097 | int C = docCountNotContainingWordInLabel; |
098 | int D = docCountNotContainingWordNotInLabel; |
099 | int temp = (A*D-B*C); |
100 | double chi = (double) N*temp*temp / (A+C)*(A+B)*(B+D)*(C+D); |
101 | Term term = new Term(word); |
103 | context.getVectorMetadata().addChiTerm(label, word, term); |
107 | private int getDocCountNotContainingWordInLabel(String word, String label) { |
109 | Iterator<Entry<String,Map<String,Map<String,Term>>>> iter = |
110 | context.getVectorMetadata().termTableIterator(); |
111 | while(iter.hasNext()) { |
112 | Entry<String,Map<String,Map<String,Term>>> entry = iter.next(); |
113 | String tmpLabel = entry.getKey(); |
115 | if(tmpLabel.equals(label)) { |
116 | Map<String, Map<String, Term>> labelledDocs = entry.getValue(); |
117 | for(Entry<String, Map<String, Term>> docEntry : labelledDocs.entrySet()) { |
119 | if(!docEntry.getValue().containsKey(word)) { |
129 | private int getDocCountNotContainingWordNotInLabel(String word, String label) { |
131 | Iterator<Entry<String,Map<String,Map<String,Term>>>> iter = |
132 | context.getVectorMetadata().termTableIterator(); |
133 | while(iter.hasNext()) { |
134 | Entry<String,Map<String,Map<String,Term>>> entry = iter.next(); |
135 | String tmpLabel = entry.getKey(); |
137 | if(!tmpLabel.equals(label)) { |
138 | Map<String, Map<String, Term>> labelledDocs = entry.getValue(); |
139 | for(Entry<String, Map<String, Term>> docEntry : labelledDocs.entrySet()) { |
141 | if(!docEntry.getValue().containsKey(word)) { |
输出量化数据文件
特征向量已经从训练数据集中计算出来,接下来需要对每个词给出一个唯一的编号,从1开始,这个比较容易,输出特征向量文件,为测试验证的数据集所使用,文件格式如下所示:
由于libsvm使用的训练数据格式都是数字类型的,所以需要对训练集中的文档进行量化处理,我们使用TF-IDF度量,表示词与文档的相关性指标。
然后,需要遍历已经构建好的词袋模型,并使用已经编号的类别和特征向量,对每个文档计算TF-IDF值,每个文档对应一条记录,取出其中一条记录,输出格式如下所示:
1 | 8 9219:0.24673737883635047 453:0.09884635754820137 10322:0.21501394457319623 11947:0.27282495932970074 6459:0.41385272697452935 46:0.24041607991272138 8987:0.14897255497578704 4719:0.22296154731520754 10094:0.13116443653818177 5162:0.17050804524212404 2419:0.11831944042647048 11484:0.3501901869096251 12040:0.13267440708284894 8745:0.5320327758892881 9048:0.11445287153209653 1989:0.04677087098649205 7102:0.11308242956243426 3862:0.12007217405755069 10417:0.09796211412332205 5729:0.148037967054332 11796:0.08409157900442304 9094:0.17368658217203461 3452:0.1513474608736807 3955:0.0656773581702849 6228:0.4356889927309336 5299:0.15060439516792662 3505:0.14379243687841153 10732:0.9593462052245719 9659:0.1960034406311122 8545:0.22597403804274924 6767:0.13871522631066047 8566:0.20352452713417019 3546:0.1136541497082903 6309:0.10475466997804883 10256:0.26416957780238604 10288:0.22549409383630933 |
第一列的8表示类别编号,其余的每一列是词及其权重,使用冒号分隔,例如“9219:0.24673737883635047”表示编号为9219的词,对应的TF-IDF值为0.24673737883635047。如果特征向量有个N个,那么每条记录就对应着一个N维向量。
对于测试数据集中的文档,也使用类似的方法,不过首先需要加载已经输出的特征向量文件,从而构建一个支持libsvm格式的输出测试集文件。
使用libsvm训练文本分类器
前面的准备工作已经完成,现在可以使用libsvm工具包训练文本分类器。在使用libsvm的开始,需要做一个尺度变换操作(有时也称为归一化),有利于libsvm训练出更好的模型。我们已经知道前面输出的数据中,每一维向量都使用了TF-IDF的值,但是TF-IDF的值可能在一个不规范的范围之内(因为它依赖于TF和IDF的值),例如0.19872~8.3233,所以可以使用libsvm将所有的值都变换到同一个范围之内,如0~1.0,或者-1.0~1.0,可以根据实际需要选择。我们看一下命令:
1 | F:\libsvm-3.0\windows>svm-scale.exe -l 0 -u 1 C:\\Users\\thinkpad\\Desktop\\vector\\train.txt > C:\\Users\\thinkpad\\Desktop\\vector\\train-scale.txt |
尺度变换后输出到文件train-scale.txt中,它可以直接作为libsvm训练的数据文件,我使用Java版本的libsvm代码,输入参数如下所示:
1 | train -h 0 -t 0 C:\\Users\\thinkpad\\Desktop\\vector\\train-scale.txt C:\\Users\\thinkpad\\Desktop\\vector\\model.txt |
这里面,-t 0表示使用线性核函数,我发现在进行文本分类时,线性核函数比libsvm默认的-t 2非线性核函数的效果要要好一些。最后输出的是模型文件model.txt,内容示例如下所示:
05 | rho -0.26562545584492675 -0.19596934447720876 0.24937032535471693 0.3391566771481882 -0.19541394291523667 -0.20017990510840347 -0.27349052681332664 -0.08694672836814998 -0.33057155365157015 0.06861675551386985 0.5815821822995312 0.7781870137763507 0.054722797451472065 0.07912846180263113 -0.01843419889020123 0.15110176721612528 -0.08484865489154271 0.46608205351462983 0.6643550487438468 -0.003914533674948038 -0.014576392246426623 -0.11384567944039309 0.09257404411884447 -0.16845445862600575 0.18053514069700813 -0.5510915276095857 -0.4885382860289285 -0.6057167948571457 -0.34910272249526764 -0.7066730463805829 -0.6980796972363181 -0.639435517196082 -0.8148772080348755 -0.5201121512955246 -0.9186975203736724 -0.008882360255733836 -0.0739010940085453 0.10314117392946448 -0.15342997221636115 -0.10028736061509444 0.09500443080371801 -0.16197536915675026 0.19553010464320583 -0.030005330377757263 -0.24521471309904422 |
06 | label 8 4 7 5 10 9 3 2 6 1 |
07 | nr_sv 6542 5926 5583 4058 5347 6509 5932 4050 6058 4850 |
09 | 0.16456599916886336 0.22928285261208994 0.921277302054534 0.39377902901901013 0.4041207410447258 0.2561997963212561 0.0 0.0819993502684317 0.12652009525418703 9219:0.459459 453:0.031941 10322:0.27027 11947:0.0600601 6459:0.168521 46:0.0608108 8987:0.183784 4719:0.103604 10094:0.0945946 5162:0.0743243 2419:0.059744 11484:0.441441 12040:0.135135 8745:0.108108 9048:0.0440154 1989:0.036036 7102:0.0793919 3862:0.0577064 10417:0.0569106 5729:0.0972222 11796:0.0178571 9094:0.0310078 3452:0.0656566 3955:0.0248843 6228:0.333333 5299:0.031893 3505:0.0797101 10732:0.0921659 9659:0.0987654 8545:0.333333 6767:0.0555556 8566:0.375 3546:0.0853659 6309:0.0277778 10256:0.0448718 10288:0.388889 |
上面,我们只是选择了非默认的核函数,还有其他参数可以选择,比如代价系数c,默认是1,表示在计算线性分类面时,可以容许一个点被分错。这时候,可以使用交叉验证来逐步优化计算,选择最合适的参数。
使用libsvm,指定交叉验证选项的时候,只输出经过交叉验证得到的分类器的精度,而不会输出模型文件,例如使用交叉验证模型运行时的参数示例如下:
1 | -h 0 -t 0 -c 32 -v 5 C:\\Users\\thinkpad\\Desktop\\vector\\train-scale.txt C:\\Users\\thinkpad\\Desktop\\vector\\model.txt |
用-v启用交叉验证模式,参数-v 5表示将每一类下面的数据分成5份,按顺序1对2,2对3,3对4,4对5,5对1分别进行验证,从而得出交叉验证的精度。例如,下面是我们的10个类别的交叉验证运行结果:
1 | Cross Validation Accuracy = 71.10428571428571% |
在选好各个参数以后,就可以使用最优的参数来计算输出模型文件。
使用libsvm验证文本分类器精度
前面已经训练出来分类模型,就是最后输出的模型文件。现在可以使用测试数据集了,通过使用测试数据集来做对基于文本分类模型文件预测分类精度进行验证。同样,需要做尺度变换,例如:
1 | F:\libsvm-3.0\windows>svm-scale.exe -l 0 -u 1 C:\\Users\\thinkpad\\Desktop\\vector\\test.txt > C:\\Users\\thinkpad\\Desktop\\vector\\test-scale.txt |
注意,这里必须和训练集使用相同的尺度变换参数值。
我还是使用Java版本的libsvm进行预测,验证分类器精度,svm_predict类的输入参数:
1 | C:\\Users\\thinkpad\\Desktop\\vector\\test-scale.txt C:\\Users\\thinkpad\\Desktop\\vector\\model.txt C:\\Users\\thinkpad\\Desktop\\vector\\predict.txt |
这样,预测结果就在predict.txt文件中,同时输出分类精度结果,例如:
1 | Accuracy = 66.81% (6681/10000) (classification) |
如果觉得分类器精度不够,可以使用交叉验证去获取更优的参数,来训练并输出模型文件,例如,下面是几组结果:
01 | train -h 0 -t 0 C:\\Users\\thinkpad\\Desktop\\vector\\train-scale.txt C:\\Users\\thinkpad\\Desktop\\vector\\model.txt |
02 | Accuracy = 67.10000000000001% (6710/10000) (classification) |
04 | train -h 0 -t 0 -c 32 -v 5 C:\\Users\\thinkpad\\Desktop\\vector\\train-scale.txt C:\\Users\\thinkpad\\Desktop\\vector\\model.txt |
05 | Cross Validation Accuracy = 71.10428571428571% |
06 | Accuracy = 66.81% (6681/10000) (classification) |
08 | train -h 0 -t 0 -c 8 -m 1024 C:\\Users\\thinkpad\\Desktop\\vector\\train-scale.txt |
09 | C:\\Users\\thinkpad\\Desktop\\vector\\model.txt |
10 | Cross Validation Accuracy = 74.3240057320121% |
11 | Accuracy = 67.88% (6788/10000) (classification) |
第一组是默认情况下c=1时的精度为 67.10000000000001%;
第二组使用了交叉验证模型,交叉验证精度为71.10428571428571%,获得参数c=32,使用该参数训练输出模型文件,基于该模型文件进行预测,最终的精度为66.81%,可见没有使用默认c参数值的精度高;
第三组使用交叉验证,精度比第二组高一些,输出模型后并进行预测,最终精度为67.88%,略有提高。
可以基于这种方式不断地去寻找最优的参数,从而使分类器具有更好的精度。
总结
文本分类有其特殊性,在使用libsvm分类,或者其他的工具,都不要忘记,有如下几点需要考虑到:
- 其实文本在预处理过程进行的很多过程对最后使用工具进行分类都会有影响。
- 最重要的就是文本特征向量的选择方法,如果文本特征向量选择的很差,即使再好的分类工具,可能训练得到的分类器都未必能达到更好。
- 文本特征向量选择的不好,在训练调优分类器的过程中,虽然找到了更好的参数,但是这本身可能会是一个不好的分类器,在实际预测中可以出现误分类的情况。
- 选择训练集和测试集,对整个文本预处理过程,以及使用分类工具进行训练,都有影响。
相关资源
最后,附上文章中有关文本分类预处理的实现代码,仅供参考,链接为:
这个是最早的那个版本,默认分词使用了中科院ICTCLAS分词器,不过我当时使用的现在好像因为License的问题可能用不了了。
这个是我最近抽时间将原来document-processor代码进行重构,使用Maven进行构建,分为多个模块,并做了部分优化:
- 默认使用Lucene的SmartChineseAnalyzer进行分词,默认没有使用词典,分词效果可能没有那么理想。
- 增加了api层,对于某些可以自定义实现的,预留出了接口,并可以通过配置来注入自定义实现功能,主要是接口:FeatureTermSelector。
- 分词过程中,各个类别采用并行处理,处理时间大大减少:DocumentWordsCollector。
- 将train阶段和test阶段通用的配置提出来,放在配置文件config.properties中。
- 默认给予CHI卡方统计量方法选择特征向量,实现了各个类别之间并行处理的逻辑,可以查看实现类ChiFeatureTermSelector。
另外,使用的语料库文件,我放在百度网盘上了,可以下载:http://pan.baidu.com/s/1pJv6AIR
参考链接






















 3536
3536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









