







一、概述
分区表的用途和优点:
1. 降低故障引起的损失;
2. 均衡I/O,减少竞争;
3. 提高查询速度,这一点在数据仓库的TP查询特别有用;
*TP查询:Transaction Processing,事务处理查询?这点不太清楚、网上资料也少,没查到
二、创建表分区
*首先通过下列语句找到目标数据库中的表空间名:
select tablespace_name,file_name,bytes/1024/1024 as MB from dba_data_files order by tablespace_name;
1. 范围分区:关键字RANGE,创建这种分区后,插入的数据会根据指定的分区键值范围进行分布,当数据在范围内均匀分布时,性能最好。
指定某一列的键值创建分区表:
例:创建一个商品零售表、包含四个分区,记录按照日期所在的季度分区:
create table ware_retail_part --创建一个描述商品零售的数据表
(
id integer primary key,--销售编号
retail_date date,--销售日期
ware_name varchar2(50)--商品名称
)
partition by range(retail_date)
(
--2011年第一个季度为part_01分区
partition par_01 values less than(to_date('2011-04-01','yyyy-mm-dd')) tablespace TB_3,
--2011年第二个季度为part_02分区
partition par_02 values less than(to_date('2011-07-01','yyyy-mm-dd')) tablespace TB_4,
--2011年第三个季度为part_03分区
partition par_03 values less than(to_date('2011-10-01','yyyy-mm-dd')) tablespace TB_3,
--2011年第四个季度为part_04分区
partition par_04 values less than(to_date('2012-01-01','yyyy-mm-dd')) tablespace TB_4
);之后我们向该表插入几条记录看下结果:
insert into ware_retail_part values(1,to_date('2011-01-21','yyyy-mm-dd'),'Pad');
insert into ware_retail_part values(2,to_date('2011-04-01','yyyy-mm-dd'),'Pad');insert into ware_retail_part values(3,to_date('2011-07-25','yyyy-mm-dd'),'Pad');
insert into ware_retail_part values(4,to_date('2011-12-31','yyyy-mm-dd'),'Pad');
查询该表中某个分区中的数据:
select *from ware_retail_part partition(par_01);
指定某几列的键值创建分区表:
例:创建一个商品零售表、包含四个分区,按照日期和销售序号进行分区:
create table ware_retail_part2 --创建一个描述商品零售的数据表
(
id integer primary key,--销售编号
retail_date date,--销售日期
ware_name varchar2(50)--商品名称
)
partition by range(id,retail_date)
(
--part_01分区
partition par_01 values less than(10,to_date('2011-04-01','yyyy-mm-dd')) tablespace TB_3,
--part_02分区
partition par_02 values less than(20,to_date('2011-07-01','yyyy-mm-dd')) tablespace TB_4,
--part_03分区
partition par_03 values less than(maxvalue,maxvalue) tablespace TB_3
);最后一句有必要提一下,意思就是ID大于20、日期大于2011-07-01的记录全部存到第三个分区。
*注:这里指定的表空间块大小要一致,否则会报ORA-14519错误;这时需要修改对应表空间的块大小:
alter system set db_block_size=xxxx;
如果修改不了,可以参考这篇文章:http://blog.csdn.net/victory_xing126/article/details/45126247
2. 散列分区:又叫Hash分区;实在列的取值范围难以确定的情况下采用的分区方法。一般,下面几种情况可以采用Hash分区:
·DBA无法获知具体的数据值;
·数据的分布有Oracle处理;
·每个分区有自己的表空间。
例1:创建一个商品零售表,将表的ID列设为Hash键来决定记录的所在分区
create table ware_retail_part3 --创建一个描述商品零售的数据表
(
id integer primary key,--销售编号
retail_date date,--销售日期
ware_name varchar2(50)--商品名称
)
partition by hash(id)
(
partition par_01 tablespace TB_3,
partition par_02 tablespace TB_4
);此时,向其中插入数据,Oracle会自动计算ID列的Hash值、从而决定该条记录该被存到哪个分区。
insert into ware_retail_part3 values(181,to_date('2011-01-21','yyyy-mm-dd'),'Pad');
insert into ware_retail_part3 values(271,to_date('2011-04-01','yyyy-mm-dd'),'Pad');insert into ware_retail_part3 values(301,to_date('2011-07-25','yyyy-mm-dd'),'Pad');
insert into ware_retail_part3 values(431,to_date('2011-12-31','yyyy-mm-dd'),'Pad');
如果想知道某条记录被插入到哪个分区中,可以用下面的语句查询:select ora_hash(Hash键值, 分区数) from dual;
例2:创建一个分区表,让系统自动生成分区名,并把这两个分区分别放到表空间tb_3,tb_4中:
create table ware_retail_part4 --创建一个描述商品零售的数据表
(
id integer primary key,--销售编号
retail_date date,--销售日期
ware_name varchar2(50)--商品名称
)
partition by hash(id)
<pre name="code" class="sql">partitions 2例3:创建一个分区表,并指定其初始化空间大小为2MB:
create table ware_retail_part5 --创建一个描述商品零售的数据表
(
id integer primary key,--销售编号
retail_date date,--销售日期
ware_name varchar2(50)--商品名称
)storage(initial 2048k)
partition by hash(id)
(
partition par_01 tablespace TB_3,
partition par_02 tablespace TB_4
);3. 列表分区:与范围分区类似,但分区依据是根据分区键的“具体值”来决定
例1:保存客户信息的clients表,以province列的值创建列表分区:
create table clients
(
id integer primary key,
name varchar2(50),
province varchar2(20)
)
partition by list(province)
(
partition shandong values('山东省') tablespace TB_3,
partition guangdong values('广东省') tablespace TB_4,
partition yunnan values('云南省') tablespace TB_3
);向其中插入数据:
insert into clients values (19,'East','云南省');
insert into clients values (29,'West','广东省');
insert into clients values (09,'North','山东省');
查下结果:
select * from clients partition(yunnan);
select * from clients partition(shandong);
select * from clients partition(guangdong);
4. 组合分区:顾名思义,把两种分区方法用到同一段分区创建语句中;Oracle在执行时会先对第一个分区键值用第一种分区方法进行分配,然后再按照第二种分区方法对分区内的数据进行二次分区
例1:创建人员信息表person2,根据编号为其创建3个范围分区,再在每个分区内根据姓名创建两个Hash子分区
create table person2 --创建以一个描述个人信息的表
(
id number primary key, --个人的编号
name varchar2(20), --姓名
sex varchar2(2) --性别
)
partition by range(id)--以id作为分区键创建范围分区
subpartition by hash(name)--以name列作为分区键创建hash子分区
subpartitions 2 store in(tb_3,tb_4)--hash子分区公有两个,分别存储在两个不同的命名空间中
(
partition par1 values less than(5000),--范围分区,id小于5000
partition par2 values less than(10000),--范围分区,id小于10000
partition par3 values less than(maxvalue)--范围分区,id不小于10000
);
*关于什么是本地索引,可以参考:http://blog.csdn.net/tannafe/article/details/4132858
例1:创建销售记录表saleRecord,为该表创建Interval分区
create table saleRecord
(
id number primary key, --编号
goodsname varchar2(50),--商品名称
saledate date,--销售日期
quantity number--销售量
)
partition by range(saledate)
interval (numtoyminterval(1,'year'))--按年份自动分区
(
--设置分区键值日期小于2012-01-01
partition par_fist values less than (to_date('2012-01-01','yyyy-mm-dd'))
);
*对于已经进行了范围分区的表格,可以通过使用alter table命令的set interval选项扩展为Interval分区表,以最一开始创建的分区表ware_retail_part为例:
alter table ware_retail_partset interval(NUMTOYMINTERVAL(3,'month'));
*表分区策略:
(1)识别大表:
已经投入使用的系统,可以用analyze table语句进行分析;以上述CLIENTS表为例:
analyze table clients compute statistics;
select * from user_tables where table_name ='CLIENTS';
(更详细的可以参考:http://blog.csdn.net/victory_xing126/article/details/44948521)
如果是研发中的系统,则要靠架构人员和客户的实际情况进行预估。
(2)根据大表的用途,确定分区方法(也就是上面说的范围分区、Hash分区、List分区,还是Interval分区);
(3)分区的表空间规划
三、管理表分区
1. 为一个已存在的分区表添加新的表分区
例:向上面的 clients表中新增一个省份为河北省的表分区:
alter table clients
add partition hebei values('河北省')
storage(initial 10k next 20k) tablespace tb_3
nologging;
最后的nologging,请参考:http://blog.csdn.net/sdl_ok/article/details/5474774
2. 合并分区:合并分区时,Oracle会自动:
·将待删除的分区内容挪到其他保留分区中;
·将待删除分区的内容和索引完全清楚;
·将一个或多个索引的本地索引分区标识为不可用(Unsable);
·对不可用的索引进行重建
(1)合并散列 分区:也就是将一个分区表的所有分区合并
alter table person coalesce partition;
(2)合并复合分区:也就是把若干个分区合并到其他保留子分区中:
比如,要将person2 的par3 分区合并到其他分区中:
alter table person2 modify partition par3 coalesce subpartition;
*注:这里说下如何查看一个表是否是分区表
先查看:
select tablespace_name from user_tables where table_name ='CLIENTS'
如果tablespace_name 为空,则表示这张表为分区表(当然,如果你把这张表的所有分区都建在同一个表空间上,那这个地方也会有值,这时就用下面的语句进行查询)
每张表的分区信息都存放在下列表中:
SELECT * FROM USER_TAB_PARTITIONS WHERE TABLE_NAME = 'CLIENTS'
3. 删除分区:可以从范围分区和复合分区中删除分区;但散列分区和复合分区中的散列子分区,只能通过合并来达到删除的目的
(1)删除一个表分区:删除后该分区的数据记录也会被删除,所以操作要谨慎。
alter table ware_retail_part drop partition par_03;
如果该表存在索引,那么需要重建该表的索引:
alter index ware_index rebuild;
*注:oracle不允许删除最后一个表分区,此外,如果该表的索引是范围分区的全局索引,那么需要重建所有索引的分区:
alter index ware_index rebuild index_01;
alter index ware_index rebuild index_02;
alter index ware_index rebuild index_04;
(2)先用DELETE删除表分区中的数据,然后在删除对应的分区,这样做的目的是让分区表的索引自动更新,即:
delete from tablename where [condition] ; --这里的condition注意,要恰好能将分区表中的数据清空
commit;
alter table ware_retail_part drop partition par_03;
(3)删除具有完整性约束的分区,这里提供两种办法:
·先禁用约束,然后删除该表的分区,在激活约束条件:
alter table table_name disable constraints constraints_name;
注:查看该表的约束条件语句:select constraint_name from USER_CONSTRAINTS where table_name=‘tablename’;
查看该表的具体哪一列被设置了约束:select * from USER_CONS_COLUMNS where table_name=‘tablename’;
alter table table_name drop partition partition_name;
alter table table_name enable constraints constraints_name;
·第二种办法:先删除待删除分区中的数据,然后在删除分区:
delete from tablename where [condition] ; --这里的condition注意,要恰好能将分区表中的数据清空
commit;
alter table ware_retail_part drop partition par_03;
4. 并入分区:·可以将两个相邻的范围分区合并为一个新分区,这个新分区继承原来两个分区的边界;
·如果原分区存在索引,则在合并时删除索引;
·如果被合并的分区为空,则新生成的分区表示为unsable;
·不能对HASH分区表执行合并操作;
例:创建销售记录表sales,以销售日期(季度)分为4个范围分区:
create table sales--创建一个销售记录表
(
id number primary key,--记录编号
goodsname varchar2(10),--商品名
saledate date--销售日期
)
partition by range(saledate)--按照日期分区
(
--第一季度数据
partition part_sea1 values less than(to_date('2011-04-01','yyyy-mm-dd')) tablespace tb_3,
--第二季度数据
partition part_sea2 values less than(to_date('2011-07-01','yyyy-mm-dd')) tablespace tb_4,
--第三季度数据
partition part_sea3 values less than(to_date('2011-10-01','yyyy-mm-dd')) tablespace tb_3,
--第四季度数据
partition part_sea4 values less than(to_date('2012-01-01','yyyy-mm-dd')) tablespace tb_4
);
在sales表中创建局部索引:
create index index_3_4 on sales(saledate)
local(
partition part_seal tablespace tb_3,
partition part_sea2 tablespace tb_4,
partition part_sea3 tablespace tb_3,
partition part_sea4 tablespace tb_4
);
将第三个分区并入第四个分区:
alter table sales merge partitions part_sea3,part_sea4 into partition part_sea4;
重建局部索引:
alter table sales modify partition part_sea4 rebuild unusable local indexes;
四、索引分区
如果索引对应的表数据量很大,那么索引占用的空间也会很大,这是,需要对索引进行分区。
·本地索引:不反应基础表的结构,只能进行范围分区;
·全局索引:能够反映基础表的结构,当表被更改时,oracle会自动对本地索引所在的分区进行维护
1. 本地索引分区:通过和范围分区相同的列进行索引分区,也就是说,数据分区和索引分区是一一对应的,它有以下几个优点:
·如果只有一个分区需要维护,则只有一个本地索引受影响;
·支持分区独立性;
·只有本地索引能够支持单一分区的装入和卸载;
·表分区和各自的本地索引可以同时恢复;
·本地索引可以单独重建;
·位图索引仅由本地索引支持
(1)创建范围分区的本地索引分区:
--准备表空间
create tablespace TEST_2 datafile 'C:\tsdbf\ts1.dbf'
size 10m
extent management local autoallocate;
create tablespace ts_2 datafile 'C:\tsdbf\ts2.dbf'
size 10m
extent management local autoallocate;
create tablespace tb_3 datafile 'C:\tsdbf\ts3.dbf'
size 10m
extent management local autoallocate;
--创建分区表:
create table studentgrade
(
id number primary key,--记录id
name varchar2(10),--学生名称
subject varchar2(10),--学科
grade number --成绩
)
partition by range(grade)
(
--小于60分,不及格
partition par_nopass values less than(60) tablespace TEST_2,
--小于70分,及格
partition par_pass values less than(70) tablespace ts_2,
--大于或等于70分,优秀
partition par_good values less than(maxvalue) tablespace tb_3
);
--创建本地索引分区
create index grade_index on studentgrade(grade)
local
(
partition p1 tablespace TEST_2,
partition p2 tablespace ts_2,
partition p3 tablespace tb_3
);
--查看索引分区信息
select partition_name,tablespace_name from dba_ind_partitions where index_name = 'GRADE_INDEX';
(2)创建组合分区的本地分区索引
--创建范围-列表组合分区表:
create table studentgrade2
(
id number primary key,--记录id
name varchar2(10),--学生名称
subject varchar2(10),--学科
grade number --成绩
)
partition by range(grade)
subpartition by list(subject)
(
--小于60分,不及格
partition grade_nopass values less than ('60') tablespace ts_2
(
subpartition list1 values('math') tablespace ts_2,
subpartition list2 values('ch') tablespace tb_3,
subpartition list3 values('phy') tablespace test_2
)
,
--小于75分,及格
partition grade_pass values less than ('75')tablespace TEST_2
(
subpartition list4 values('math') tablespace ts_2,
subpartition list5 values('ch') tablespace tb_3,
subpartition list6 values('phy') tablespace test_2
)
,
--大于75分,优秀
partition grade_good values less than (maxvalue) tablespace tb_3
(
subpartition list7 values('math') tablespace ts_2,
subpartition list8 values('ch') tablespace tb_3,
subpartition list9 values('phy') tablespace test_2
)
);
--创建组合分区的、包含索引子分区的本地分区索引
create index subject_index on studentgrade2(subject)
local
(
partition p1 tablespace TEST_2
(
subpartition p11 tablespace test_2,
subpartition p12 tablespace test_2,
subpartition p13 tablespace test_2
)
,
partition p2 tablespace ts_2
(
subpartition p21 tablespace ts_2,
subpartition p22 tablespace ts_2,
subpartition p23 tablespace ts_2
)
,
partition p3 tablespace tb_3
(
subpartition p31 tablespace tb_3,
subpartition p32 tablespace tb_3,
subpartition p33 tablespace tb_3
)
);*注:索引的子分区数必须与基础表的子分区数相等,否则会报ORA-14186错误
2. 创建全局索引分区:当分区中出现许多事物并且要保证所有分区中的数据记录唯一时、采用这种索引;他的分区键不一定非要和表分区的分区键一致。
(1)创建范围分区的全局索引:
create index index_studentgrade on studentgrade(subject)
global partition by range(subject) --注意关键字global
(
partition p1 values less than(30),
partition p2 values less than(60),
partition p3 values less than (maxvalue)
);
(2)创建组合分区的全局分区索引:
--创建范围-列表组合分区表
create table studentgrade3
(
id number primary key,--记录id
name varchar2(10),--学生名称
subject varchar2(10),--学科
grade number --成绩
)
partition by range(grade)
subpartition by list(subject)
(
--小于60分,不及格
partition grade_nopass values less than ('60') tablespace ts_2
(
subpartition list1 values('math') tablespace ts_2,
subpartition list2 values('ch') tablespace tb_3,
subpartition list3 values('phy') tablespace test_2
),
--小于75分,及格
partition grade_pass values less than ('75') tablespace TEST_2
(
subpartition list4 values('math') tablespace ts_2,
subpartition list5 values('ch') tablespace tb_3,
subpartition list6 values('phy') tablespace test_2
),
--大于75分,优秀
partition grade_good values less than (maxvalue) tablespace tb_3
(
subpartition list7 values('math') tablespace ts_2,
subpartition list8 values('ch') tablespace tb_3,
subpartition list9 values('phy') tablespace test_2
)
);
--创建包含子分区的全局分区索引<strong>(这段有问题、还在钻研中...希望有看到的大神赐教)</strong>
create index index_studentgrade3 on studentgrade3(grade,subject)
global partition by range(grade)
global subpartition by list(subject)
(
partition p1 values less than(30)
(
subpartition p11 values('math') tablespace ts_2,
subpartition p12 values('ch') tablespace tb_3,
subpartition p13 values('phy') tablespace test_2
)
,
partition p2 values less than(50)
(
subpartition p21 values('math') tablespace ts_2,
subpartition p22 values('ch') tablespace tb_3,
subpartition p23 values('phy') tablespace test_2
)
,
partition p3 values less than (maxvalue)
(
subpartition p31 values('math') tablespace ts_2,
subpartition p32 values('ch') tablespace tb_3,
subpartition p33 values('phy') tablespace test_2
)
);例2:对上面的studentgrade表的name列创建hash分区的全局索引:
create index ind_studentgrade on studentgrade(name) global partition by hash(name);
3. 管理索引分区:
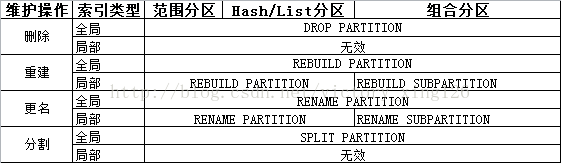
实际操作:
--更名,范围分区的全局索引index_studentgrade下的p2分区
alter index index_studentgrade rename partition p2 to p2new;
--更名,组合分区的局部索引subject_index下的p11子分区
alter index subject_index rename subpartition p11 to p11new;
--重建,局部索引分区
alter index grade_index rebuild partition p1;
--重建,组合分区的局部索引分区
alter index subject_index rebuild partition p1;
ORA-14287: 不能 REBUILD (重建) 组合范围分区的索引的分区;这个和书上讲的不一致,研究中...
--重建,组合分区的局部索引子分区
alter index subject_index rebuild subpartition p11;
--删除全局索引分区:
alter index index_studentgrade drop partition p1;
--分割表分区:
ALTER TABLE table_name SPLIT partition partition_name AT (分割点) INTO (PARTITION new_partition_name1 TABLESPACE ts1,PARTITIONnew_partition_name2 TABLESPACE ts2) ;
比如:
alter table studentgrade split partition par_good at (100) into (partition par_hun tablespace ts_2, partition par_error tablespace tb_3);
--分割全局分区索引:
alter index index_studentgrade split partition p2 at(40) into(partition par2_39 tablespace ts_2, partition par2_41 tablespace tb_3);
*注:如果要对maxvalue值所在的索引分区进行分割,则要先添加一个maxvalue分区,否则会报ORA-14080错误














 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









