







namenode工作流程图:
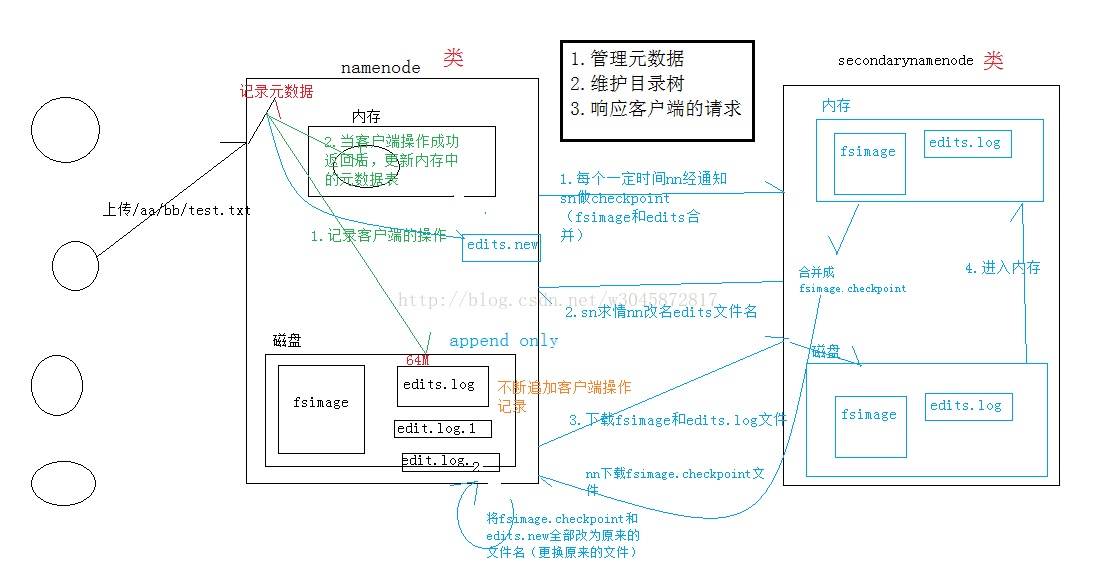
1.客户端上传的元数据,如何知道元数据被记录在各个datanode中和如何快速找到客户端需要的元数据,(其中找数据涉及随机查找)
2.如何记录元数据的记录表:可以放在内存中,也可以放在磁盘上,但放在磁盘上读取效率低,所以namenode是记录元数据的记录表放在内存中
3.现在有个问题,放在内存中,如果出现故障,数据不是就丢失了,为了防止出现这种情况,所以在磁盘上存储一下表,
4.现在又有一个问题,内存中的表示不断更新的,而磁盘上的数据没有更新,如果出现故障,内存中更新数据,没有写入更新磁盘的数据fsimage
5.所以,引入日志去记录客户端操作,在磁盘中存储一个比较小的日志文件,每次去跟新日志就行了,(现在磁盘上文件和内存中的文件就差一个日志)
6.日志和fsimage文件合并,是很费内存和cpu资源的,所以我们引入另一台服务器(secondarynamenode),专门去做日志和fsimage文件合并
7.secondarynamenode服务器从namenode下载日志和fsimage文件,将他们合并,namenode再将合并后的文件下载到本地磁盘














 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









